👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
本文以Ubuntu 20.04的hpcpni2实例为例,介绍在LLaMA多机训练时如何配置RDMA网络,充分发挥GPU算力和RDMA高速网络性能。
背景信息
LLaMA(Large Language Model Meta AI )是Meta于2023年2月推出的大型语言模型系统(Large Language Model, LLM),目前提供有70亿、130亿、330亿和650亿四种参数规模,且仅使用完全公开的数据集进行训练,其训练原理是将一系列单词作为“输入”并预测下一个单词以递归生成文本,旨在帮助研究人员推进研究工作。
LLM具有建模大量词语之间联系的能力,在文本生成、问题回答、书面材料总结,以及自动证明数学定理、预测蛋白质结构等更复杂的方面也有很大的发展前景。能够降低生成式AI工具可能带来的“偏见、有毒评论、产生错误信息的可能性”等问题。但是为了让其强大的建模能力向下游具体任务输出,需要进行指令微调,根据大量不同指令对模型部分权重进行更新,使模型更善于遵循指令。指令简单直观地描述了任务,具体的指令格式如下:
{"instruction": "Given the following input, find the missing number","input": "10, 12, 14, __, 18","output": "16"}前提条件
您已购买两台 高性能计算GPU型hpcpni2实例,下文分别命名为node1和node2,购买操作请参见购买高性能计算GPU型实例。
本文HPC GPU实例的镜像以 Ubuntu 20.04 with GPU Driver 为例,您也可以任选其它镜像。
操作步骤
登录实例。
安装docker。
拉取镜像。
执行如下命令下载Dockerfile文件。
wget https://gpu.tos-cn-beijing.volces.com/Dockerfile
执行如下命令拉取镜像。
docker pull iaas-gpu-cn-beijing.cr.volces.com/gpu-images/stanford_alpaca:v1
配置NCCL环境变量。
执行vim /etc/profile命令,打开配置文件。
按i,进入编辑模式。
在文件末尾添加如下参数。
NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1NCCL_IB_DISABLE=0NCCL_SOCKET_IFNAME=eth0NCCL_IB_GID_INDEX=3NCCL_NET_GDR_LEVEL=2NCCL_DEBUG=INFO
按Esc退出编辑模式,输入:wq并按下Enter键,保存并退出文件。
执行source /etc/profile命令,使配置更新生效。
容器环境配置。
在两台HPC实例上,分别运行如下脚本启动并进入容器。
启动容器时,需要将HPC实例上的virtualTopology.xml文件挂载至容器中。
node1:
docker run --runtime=nvidia -itd --net=host --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --name=node1 --privileged --ipc=host -v /var/run/nvidia-topologyd/virtualTopology.xml:/var/run/nvidia-topologyd/virtualTopology.xml iaas-gpu-cn-beijing.cr.volces.com/gpu-images/stanford_alpaca:v1 /bin/bashdocker exec -it node1 bash
node2:
docker run --runtime=nvidia -itd --net=host --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --name=node2 --privileged --ipc=host -v /var/run/nvidia-topologyd/virtualTopology.xml:/var/run/nvidia-topologyd/virtualTopology.xml iaas-gpu-cn-beijing.cr.volces.com/gpu-images/stanford_alpaca:v1 /bin/bashdocker exec -it node2 bash
进入容器后,执行ip a命令检查是否可以看到eth0 ~ eth4共5张网卡,其中eth0为以太网卡,其它为RDMA网卡。
在两台实例上分别运行如下脚本启动训练,需注意:
nnodes:设置为总的实例数量。
node_rank:node1上设置为0,node2上设置为1,以此类推。
master_addr:设置为node1上eth0的IP地址。
node1:
NCCL_SOCKET_IFNAME=eth0 NCCL_IB_DISABLE=0 NCCL_NET_GDR_LEVEL=2 NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1 NCCL_DEBUG=INFO WANDB_MODE=disabled torchrun --nnodes 2 --node_rank 0 --master_addr=192.168.XX.XX --nproc_per_node=8 --master_port=9999 train.py --model_name_or_path /workspace/llama-7b-hf/ --data_path ./alpaca_data.json --bf16 True --output_dir output --num_train_epochs 1 --per_device_train_batch_size 4 --per_device_eval_batch_size 4 --gradient_accumulation_steps 8 --evaluation_strategy "no" --save_strategy "steps" --save_steps 2000 --save_total_limit 1 --learning_rate 2e-5 --weight_decay 0. --warmup_ratio 0.03 --lr_scheduler_type "cosine" --logging_steps 1 --tf32 True --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' --fsdp 'full_shard auto_wrap'
node2:
NCCL_SOCKET_IFNAME=eth0 NCCL_IB_DISABLE=0 NCCL_NET_GDR_LEVEL=2 NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1 NCCL_DEBUG=INFO WANDB_MODE=disabled torchrun --nnodes 2 --node_rank 1 --master_addr=192.168.XX.XX --nproc_per_node=8 --master_port=9999 train.py --model_name_or_path /workspace/llama-7b-hf/ --data_path ./alpaca_data.json --bf16 True --output_dir output --num_train_epochs 1 --per_device_train_batch_size 4 --per_device_eval_batch_size 4 --gradient_accumulation_steps 8 --evaluation_strategy "no" --save_strategy "steps" --save_steps 2000 --save_total_limit 1 --learning_rate 2e-5 --weight_decay 0. --warmup_ratio 0.03 --lr_scheduler_type "cosine" --logging_steps 1 --tf32 True --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' --fsdp 'full_shard auto_wrap'
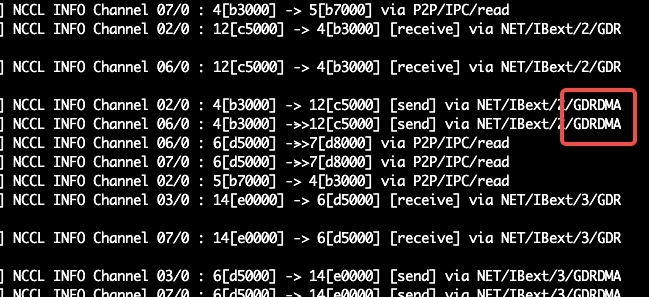
若回显含有GDRDMA,表示RDMA已成功启用。
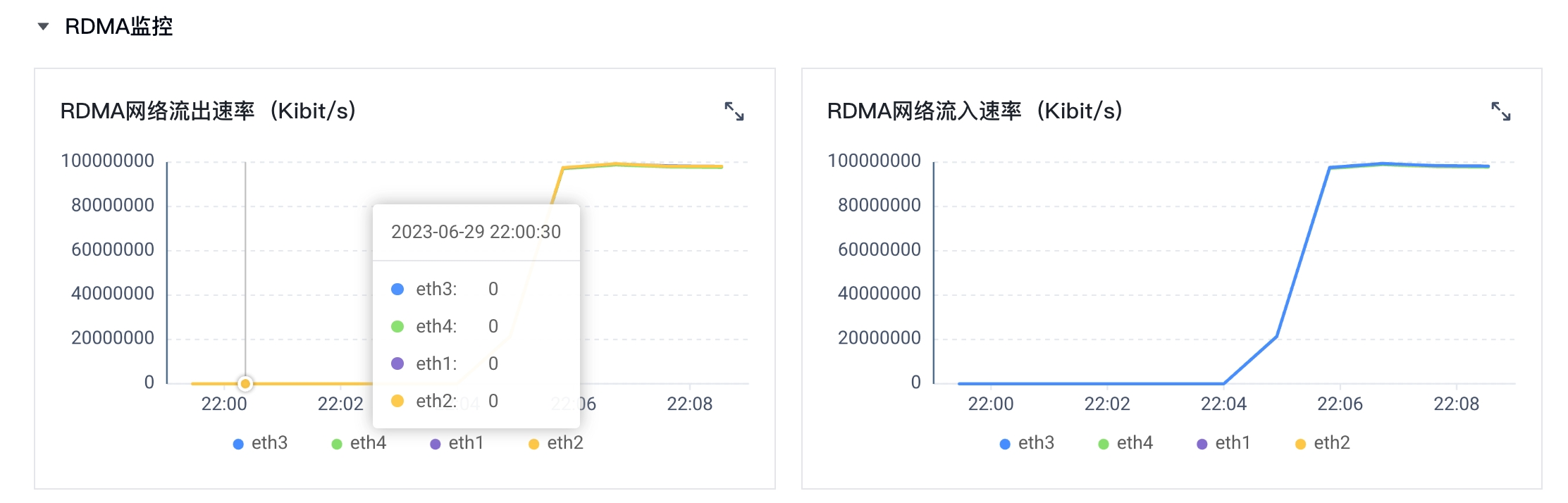
结果验证
RDMA成功启用后,您可以在云服务器控制台实例详情页的“监控 > RDMA监控”页签下查看RDMA网络的流入/流出速率。