👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
背景信息
Lambada数据集
语料来源
数据筛选过程
评估指标
PPL
ACC
软件要求
操作系统:本文以Ubuntu 20.04为例。
NVIDIA驱动:
GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.129.03为例。
CUDA:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 12.1为例。
cuDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.9.7.29为例。
使用说明
操作步骤
步骤一:准备环境
请参考通过向导购买实例创建一台符合以下条件的实例:
基础配置:
计算规格:ecs.g1ve.2xlarge
镜像:Ubuntu 20.04,并勾选“后台自动安装GPU驱动”。
存储:云盘容量在100 GiB以上。
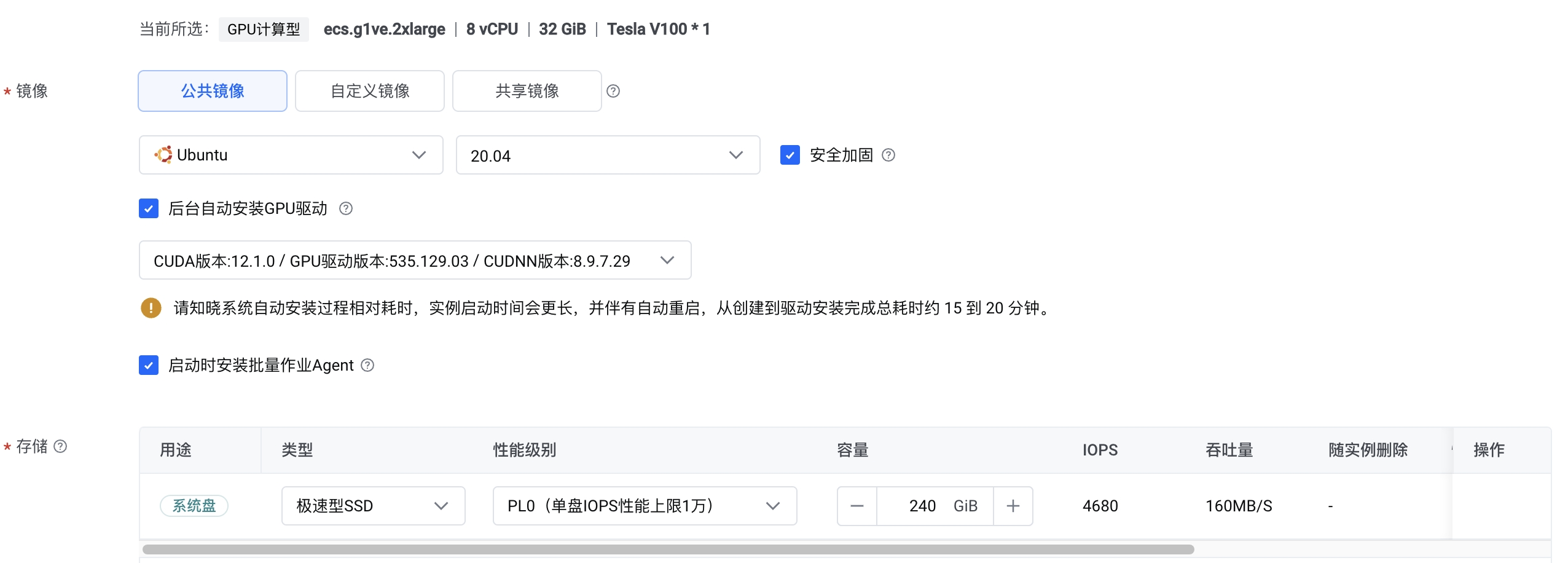
网络配置:勾选“分配弹性公网IP”。
登录Linux实例。
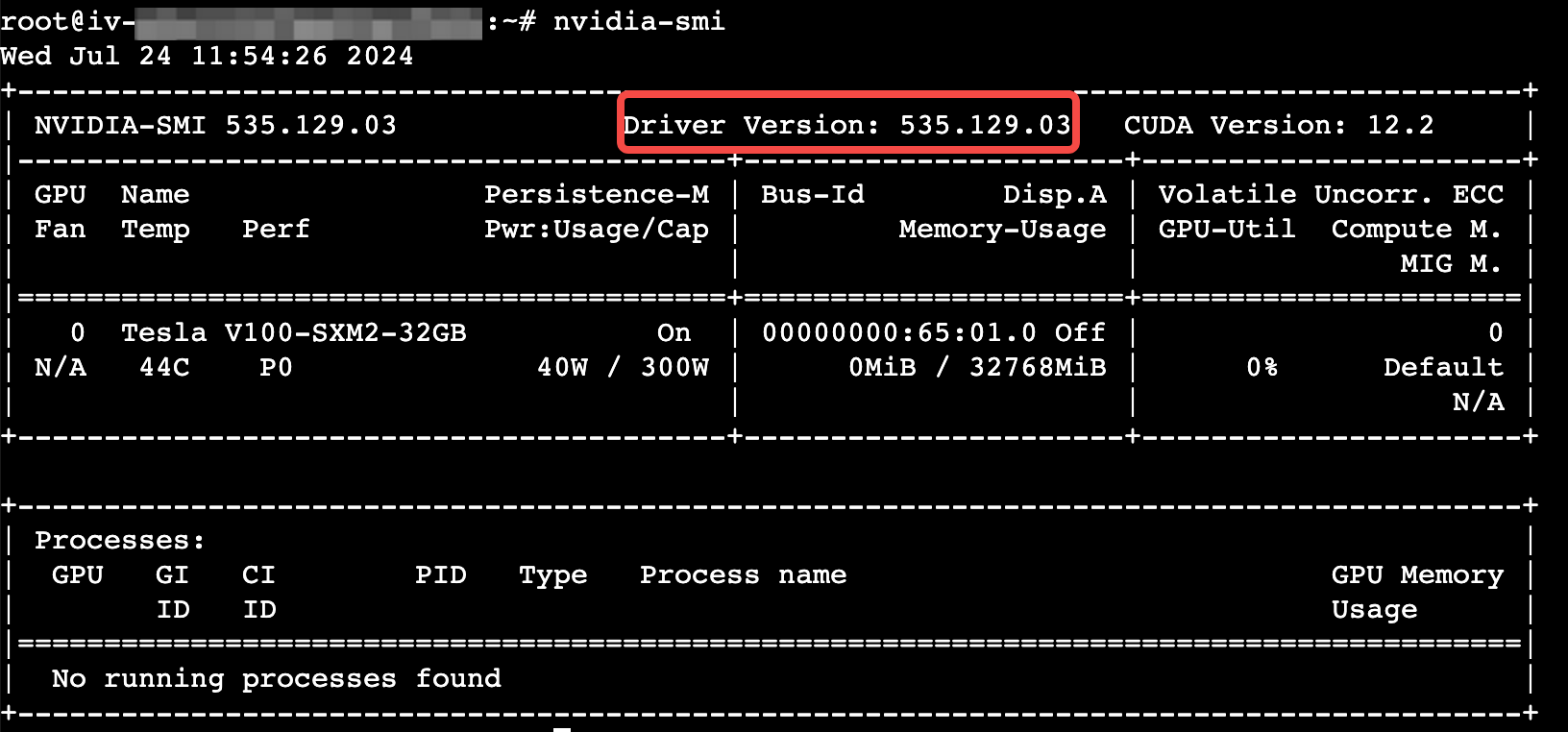
查看驱动版本已安装成功。
执行以下命令,确认GPU驱动是否安装。
执行以下命令,查看CUDA驱动。

步骤二:安装Docker和Nvidia-docker
执行以下命令,通过官方的便捷脚本安装Docker。
curl https://get.docker.com | sh \&& sudo systemctl --now enable docker
安装nvidia-docker2。
执行以下命令,配置apt仓库。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
执行以下命令,安装nvidia-docker2。
sudo apt-get updatesudo apt-get install -y nvidia-docker2
执行以下命令,重启Docker。
sudo systemctl restart docker
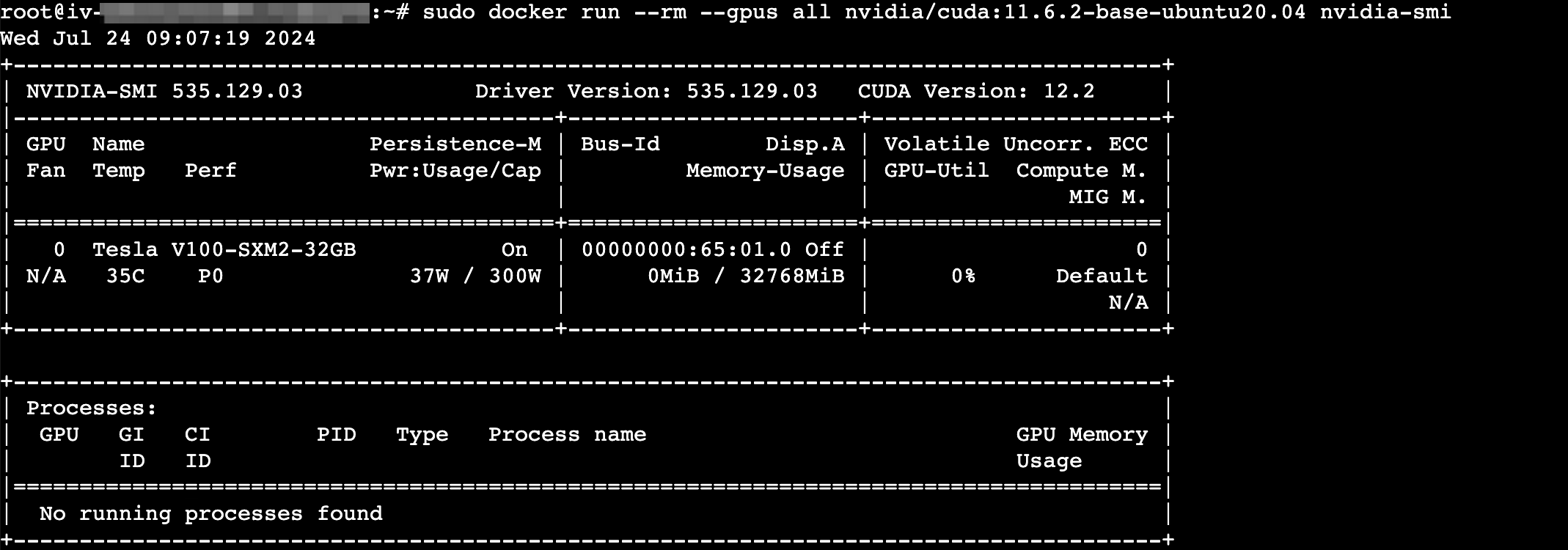
验证是否安装成功。
sudo docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
步骤三:下载NEMO镜像
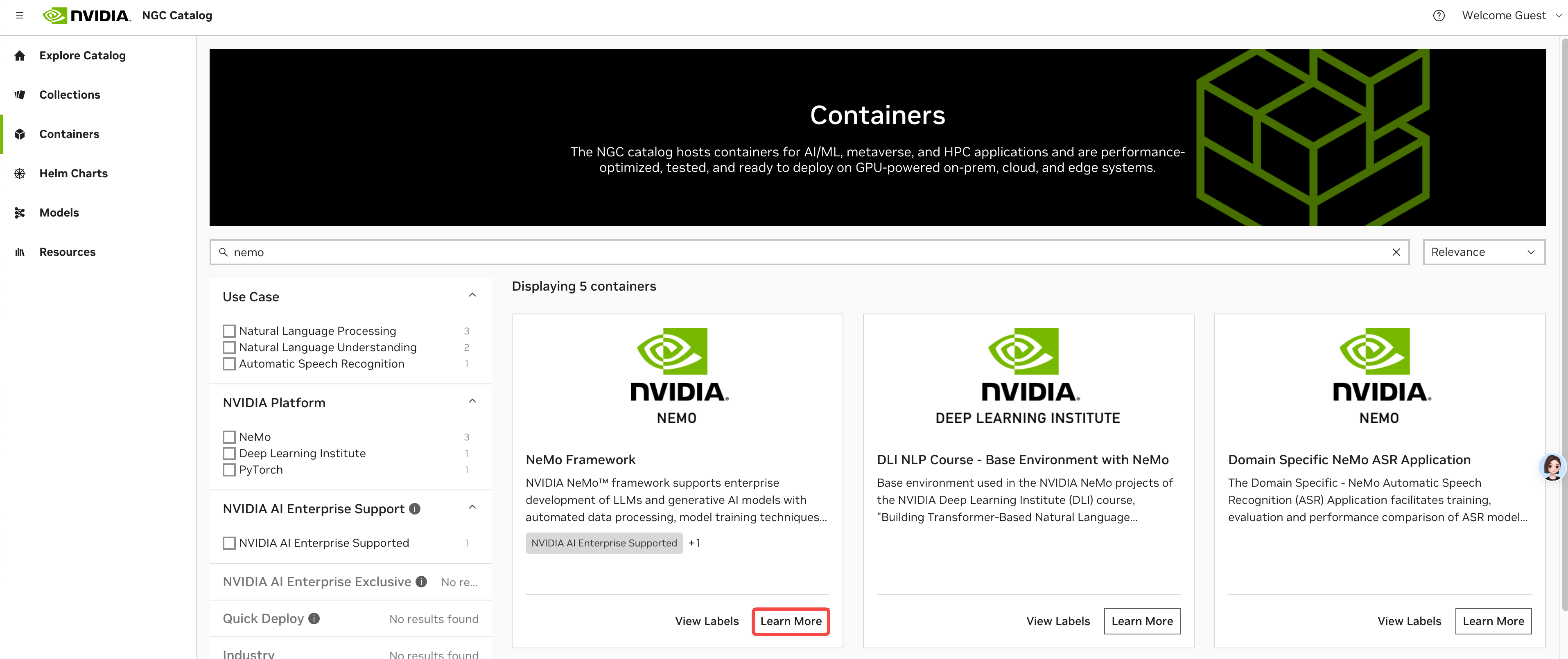
登录NVIDIA NGC网站。
在左侧选择Catalog下的的“Containers”。
在Containers页面搜索NEMO,单击“NEMO Framework”的“Learn More”按钮。
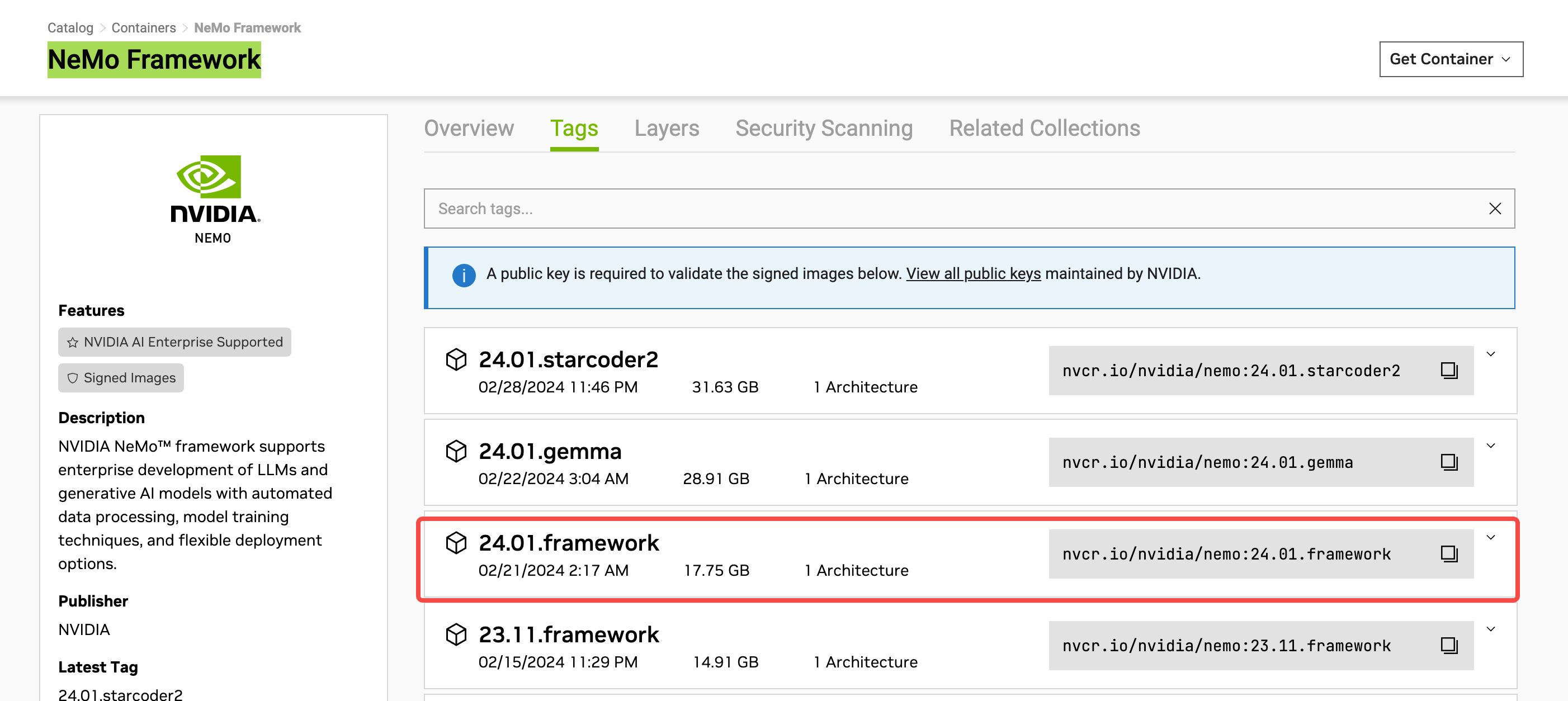
进入NEMO Framework页面,选择“Tags”页签复制下载命令,本文以24.01.framework为例。
在GPU实例中执行以下命令,下载NEMO镜像。
docker pull nvcr.io/nvidia/nemo:24.01.framework
步骤四:准备模型及数据集
依次执行以下命令,配置 packagecloud 存储库并安装git-lfs。
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashapt-get install git-lfs
依次执行以下命令,安装git。
apt-get update # 更新安装包列表apt-get install git # 安装gitapt-get install git-lfs # 安装git-lfs
执行以下命令,初始化git-lfs。
git lfs install

执行以下命令,下载Lambada模型的权重文件模型到指定目录,本文以下载到 gpt3_dataset为例。
git clone https://huggingface.co/ayrnb/megatron_nemo gpt3_dataset
执行以下命令,启动容器。
docker run -it --gpus=all --privileged --shm-size=100g -v /gpt3_dataset/:/gpt3_dataset/ nvcr.io/nvidia/nemo:24.01.framework bash
步骤五:模型参数修改
执行以下命令,打开环境配置文件。
vim /opt/NeMo-Megatron-Launcher/launcher_scripts/conf/config.yaml
参考下表说明,设置参数取值。其它参数根据使用设备和实际情况进行配置。
参数名称 | 设置值 |
defaults下的evaluation | NeMo提供了多种不同类型任务的数据集进行评估,这里设置为gpt3/evaluate_lambada,来使用lambada进行评估 |
stages | 注释除evaluation以外的参数 |
cluster_type | interactive |
launcher_scripts_path | /opt/NeMo-Megatron-Launcher/launcher_scripts |
data_dir | /gpt3_dataset/lambada_test.jsonl |
TRANSFORMERS_OFFLINE | 0 |
按esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
执行以下命令,打开评估配置文件。
vim /opt/NeMo-Megatron-Launcher/launcher_scripts/conf/evaluation/gpt3/evaluate_lambada.yaml
参考下表说明,设置参数取值。其它参数根据使用设备和实际情况进行配置。
参数名称 | 参数说明 | 设置值 |
tasks | 进行评估的任务 | lambada |
nemo_model | 预训练的nemo模型地址 | /gpt3_dataset/megatron_gpt_te_false_bf16.nemo |
vocab_file | 分词文件目录 | /gpt3_dataset/vocab.json |
merge_file | /gpt3_dataset/merges.txt | |
hparams_file | /gpt3_dataset/hparams.yaml | |
pipeline_model_parallel_size | 流水线并行数量,与训练时相同 | 2 |
按esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
步骤六:评估实验
运行评估。
执行以下命令,在/opt/NeMo-Megatron-Launcher/launcher_scripts/路径下新建运行脚本exec.sh。
cd /opt/NeMo-Megatron-Launcher/launcher_scripts/vi exec.sh
输入以下内容。
#!/bin/bashexport NVTE_FUSED_ATTN=1export NVTE_FLASH_ATTN=1rm -rvf /megatron_nemo/results/HYDRA_FULL_ERROR=1 python3 main.py
按esc退出编辑模式,输入:wq并按Enter键,保存并退出文件。
执行以下命令,为exec.sh文件添加可执行权限。
chmod +x exec.sh
执行以下命令,进行评估。
./exec.sh
结果展示。
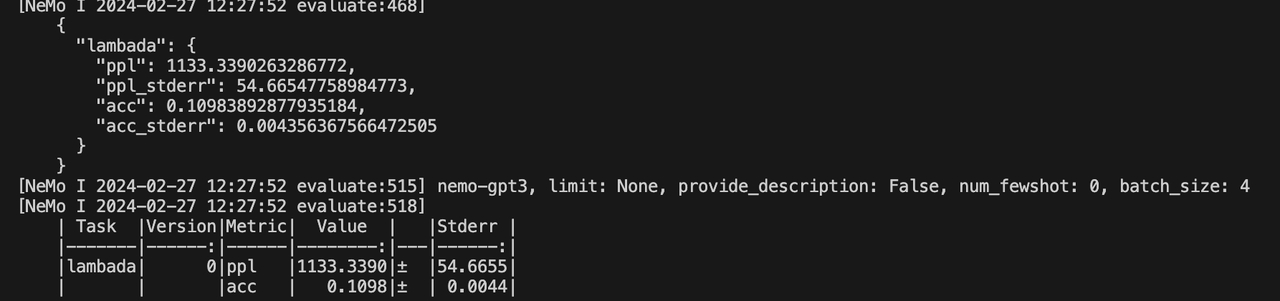
TP | PP | MBS | GBS | TE | dtype | Lambada | |
PPL(越低越好) | ACC(越高越好) | ||||||
2 | 1 | 1 | 2048 | TRUE | FP8 | 927.8558 | 0.1265 |
2 | 1 | 1 | TRUE | TEBF16 | 1035.1385 | 0.1244 | |
2 | 1 | 1 | FALSE | BF16 | 1133.339 | 0.1098 | |