👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
背景信息
Llama.cpp简介
Llama2模型简介
环境要求
NVIDIA驱动:
GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例。
CUDA:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 12.2为例。
CUDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.5.0.96为例。
运行环境:
Transformers:一种神经网络架构,用于语言建模、文本生成和机器翻译等任务。深度学习框架。本文以4.30.2为例。
Pytorch:开源的Python机器学习库,实现强大的GPU加速的同时还支持动态神经网络。本文以2.0.1为例。
Python:执行Llama.cpp的某些脚本所需的版本。本文以Python 3.8为例。
使用说明
操作步骤
步骤一:准备环境
创建GPU计算型实例。
基础配置:
计算规格:ecs.g1ve.2xlarge
镜像:Ubuntu 20.04,不勾选“后台自动安装GPU驱动”。
存储:云盘容量在200 GiB以上。
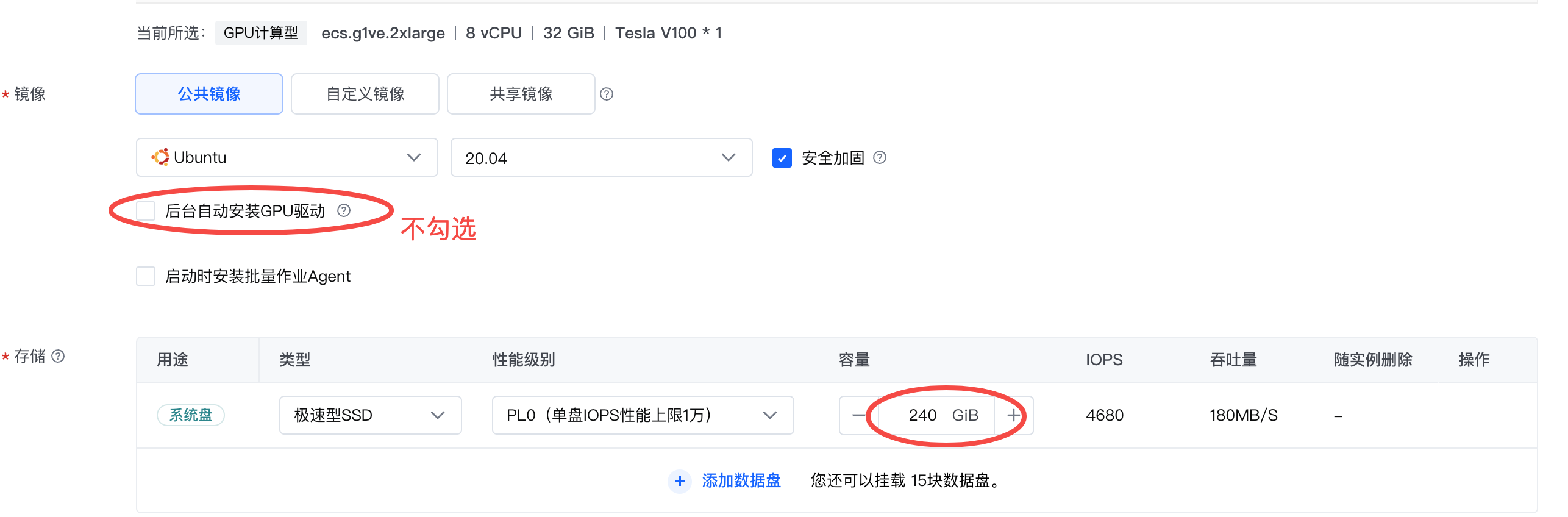
网络配置:勾选“分配弹性公网IP”。
安装GPU驱动和CUDA工具包。
登录实例。
执行以下命令,下载CUDA Toolkit。
CUDA Toolkit大小约4G,其中已经包含了GPU驱动和CUDA,安装过程相对耗时,请耐心等待。
wget https://developer.download.nvidia.com/compute/cuda/12.2.1/local_installers/cuda_12.2.1_535.86.10_linux.run
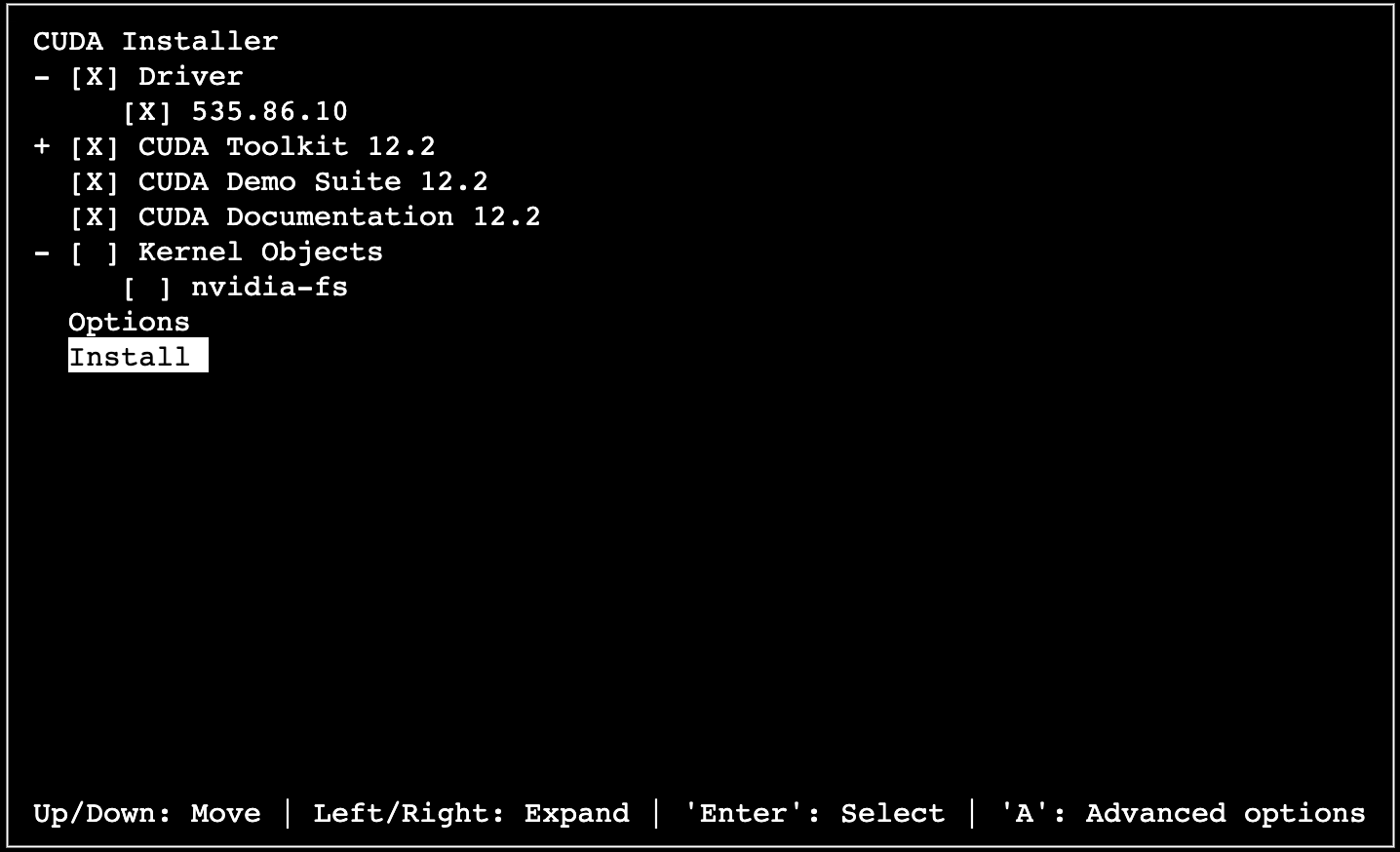
执行以下命令,安装GPU驱动和CUDA。
sh cuda_12.2.1_535.86.10_linux.run
输入"accept"确认信息。

按键盘上下键选中【Install】,回车确认,开始安装。
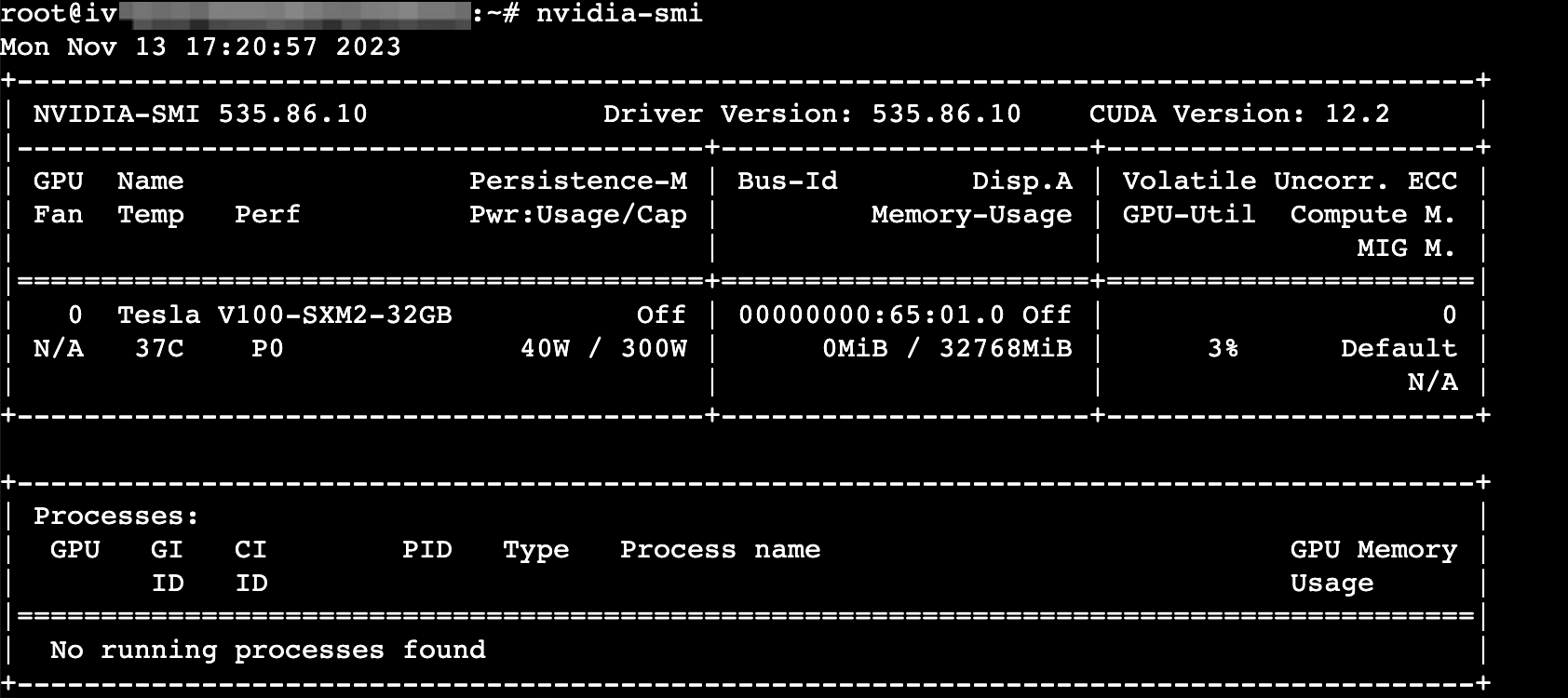
安装完成后,执行以下命令进行验证。
nvidia-smi
安装git工具。
执行如下命令,安装git。
apt-get updateapt-get install git
执行如下命令,验证git是否安装成功。
git --version

安装Python3.8和相关依赖。
执行如下命令,安装Python 3.8和pip工具。
apt-get install python3.8apt-get install pip
执行如下命令,使用pip安装相关依赖。
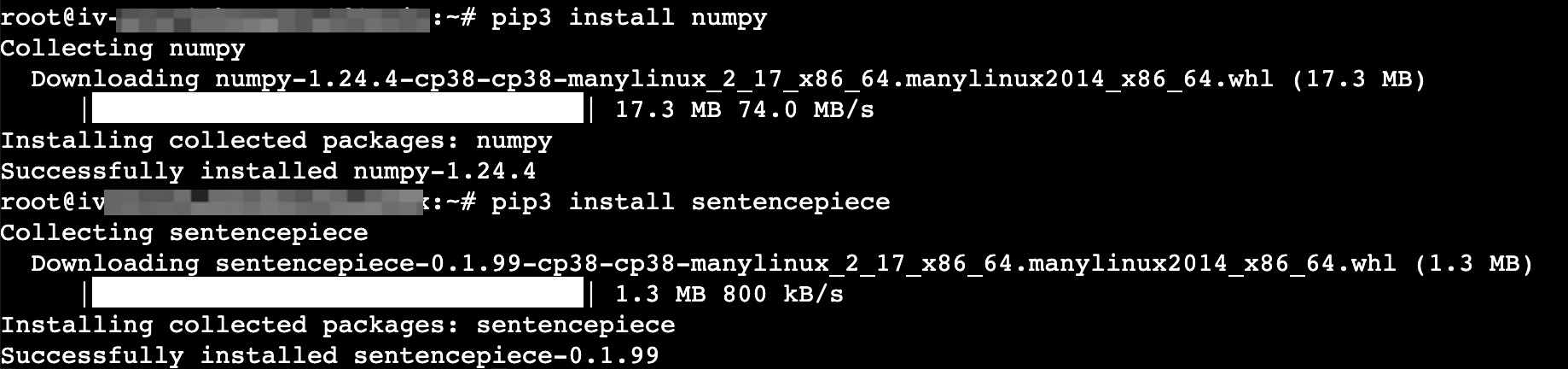
pip3 install numpypip3 install sentencepiece
步骤二:下载Llama2-7B模型
安装Llama.cpp工具。
执行以下命令,下载llama.cpp包。
git clone https://github.com/ggerganov/llama.cpp
wget https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.zip # 下载master分支的repo包unzip master.zip # 解压
下载完成之后,执行如下命令,对llama.cpp项目进行编译,得到后续用于量化和运行模型的可执行文件 ./quantize和./main。
cd llama.cppmake
下载Llama2-7B模型。
Llama官方模型是不提供chat能力的,并且其配套的分词文件和配置文件格式也非通用,需将其转化成HF格式才能被Llama.cpp正常使用。您可以直接在一些模型网站上下载HF格式的Llama2-7B模型。
由于Llama模型的使用受Meta官方的约束,您需要申请License才能获取到模型。
执行如下命令,通过git-lfs下载Llama2-7B模型。
apt-get install git-lfsgit clone https://huggingface.co/meta-llama/Llama-2-7b-hf
cd Llama-2-7b-hflf -F

执行如下命令,将模型目录Llama-2-7b-hf整体移动到llama.cpp下的models目录。
mv Llama-2-7b-hf llama.cpp/models/
步骤三:使用Llama.cpp量化Llama2-7B模型
在llama.cpp的主目录下,找到convert.py文件,使用python3.8执行该文件将原llama2-7B模型转换成gguf格式。
cd llama.cpppython3.8 convert.py models/Llama-2-7b-hf/
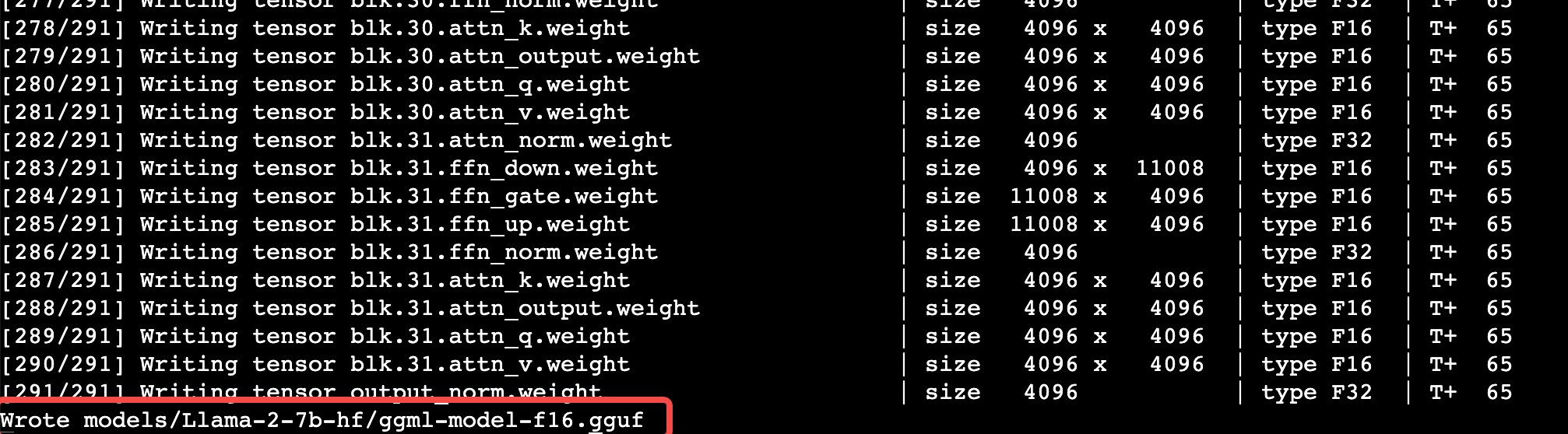
执行如下命令,量化转换后的模型。
./quantize models/Llama-2-7b-hf/ggml-model-f16.gguf models/ggml-model-q4_0.gguf q4_0
步骤四:运行量化后的Llama2-7B模型
在CPU上运行模型
执行如下命令,使用步骤二编译得到的可执行文件./main运行量化后的模型,体验对话机器人效果。
./main -m models/ggml-model-q4_0.gguf --color -f ./prompts/alpaca.txt -ins -n 2048
--color:将输入和输出分别使用不同颜色,用以区分。
-f:指定prompt模板,达到类ChatGPT的效果。
-ins:交互模式。
-n:推理的最大输出长度。
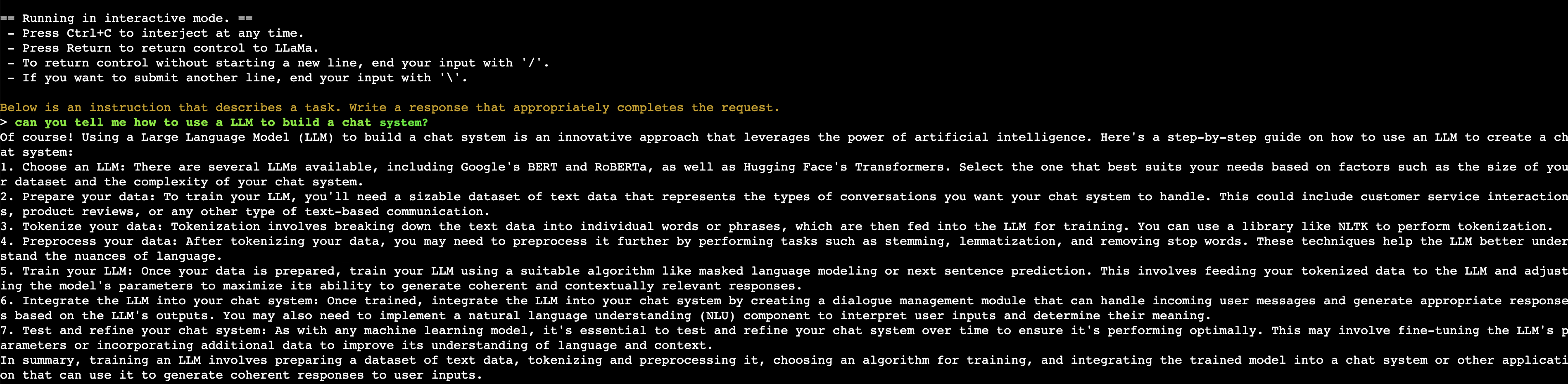
按ctrl+c可以退出交互模式,退出时可以查看基于CPU推理的性能指标。

在GPU上运行模型
执行如下命令,重新编译llama.cpp。
make LLAMA_CUBLAS=1 PATH="/usr/local/cuda/bin/:$PATH"
LLAMA_CUBLAS=1:表示将使用CUDA核心提供BLAS加速能力。
PATH:编译时可能会有nvcc找不到的报错,需要指定安装的CUDA路径。
完成编译后,同样以交互模式运行main程序(增加-ngl选项)。
./main -m models/ggml-model-q4_0.gguf --color -f ./prompts/alpaca.txt -ins -n 2048 -ngl 40

按ctrl+c可以退出交互模式,退出时可以查看基于GPU推理的性能指标。