| 百度智能云全功能AI开发平台BML-数据模型可视化功能说明 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
百度智能云全功能AI开发平台BML-数据模型可视化功能说明 当前BML Notebook已经集成VisualDL工具以实现数据模型可视化,您可在可视化tab中启动VisualDL服务。 VisualDL工具VisualDL是一个面向深度学习任务设计的可视化工具,利用丰富的图表来展示数据,用户可以更直观、清晰地查看数据的特征与变化趋势,有助于分析数据、及时发现错误,进而改进神经网络模型的设计。目前,VisualDL 支持 scalar, image, audio, graph, histogram, pr curve, high dimensional 七个组件,项目正处于高速迭代中,敬请期待新组件的加入。
Scalar--标量组件介绍 Scalar 组件的输入数据类型为标量,该组件的作用是将训练参数以折线图形式呈现。将损失函数值、准确率等标量数据作为参数传入 scalar 组件,即可画出折线图,便于观察变化趋势。 记录接口 Scalar 组件的记录接口如下:
接口参数说明如下:
*注意tag的使用规则为: 1、第一个/前的为父tag,并作为一栏图片的tag 具体使用参见以下三个例子:
Demo
下面展示了使用 Scalar 组件记录数据的示例: from visualdl import LogWriter
if __name__ == '__main__':
value = [i/1000.0 for i in range(1000)]
# 初始化一个记录器
with LogWriter(logdir="./log/scalar_test/train") as writer:
for step in range(1000):
# 向记录器添加一个tag为`acc`的数据
writer.add_scalar(tag="acc", step=step, value=value[step])
# 向记录器添加一个tag为`loss`的数据
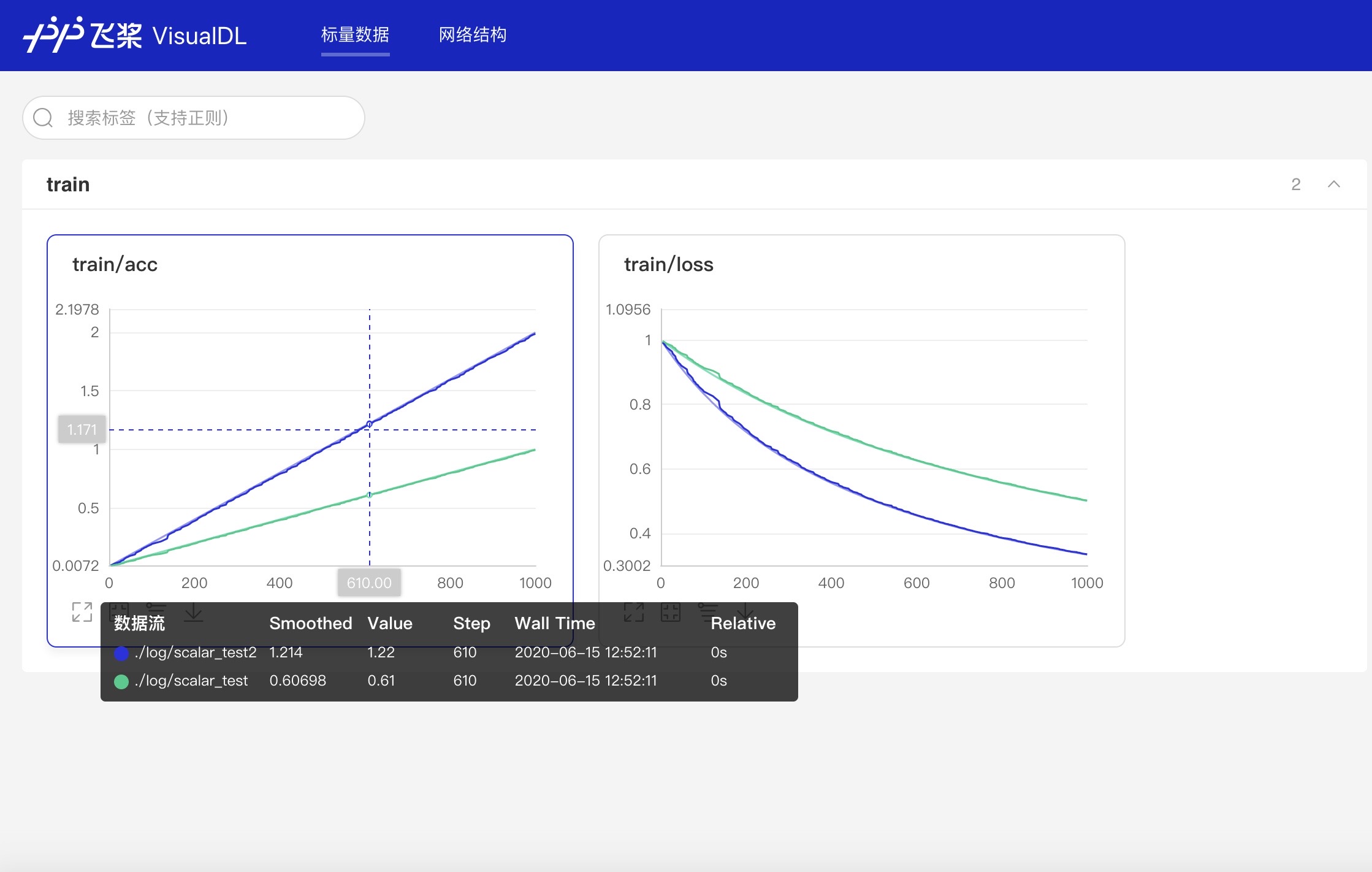
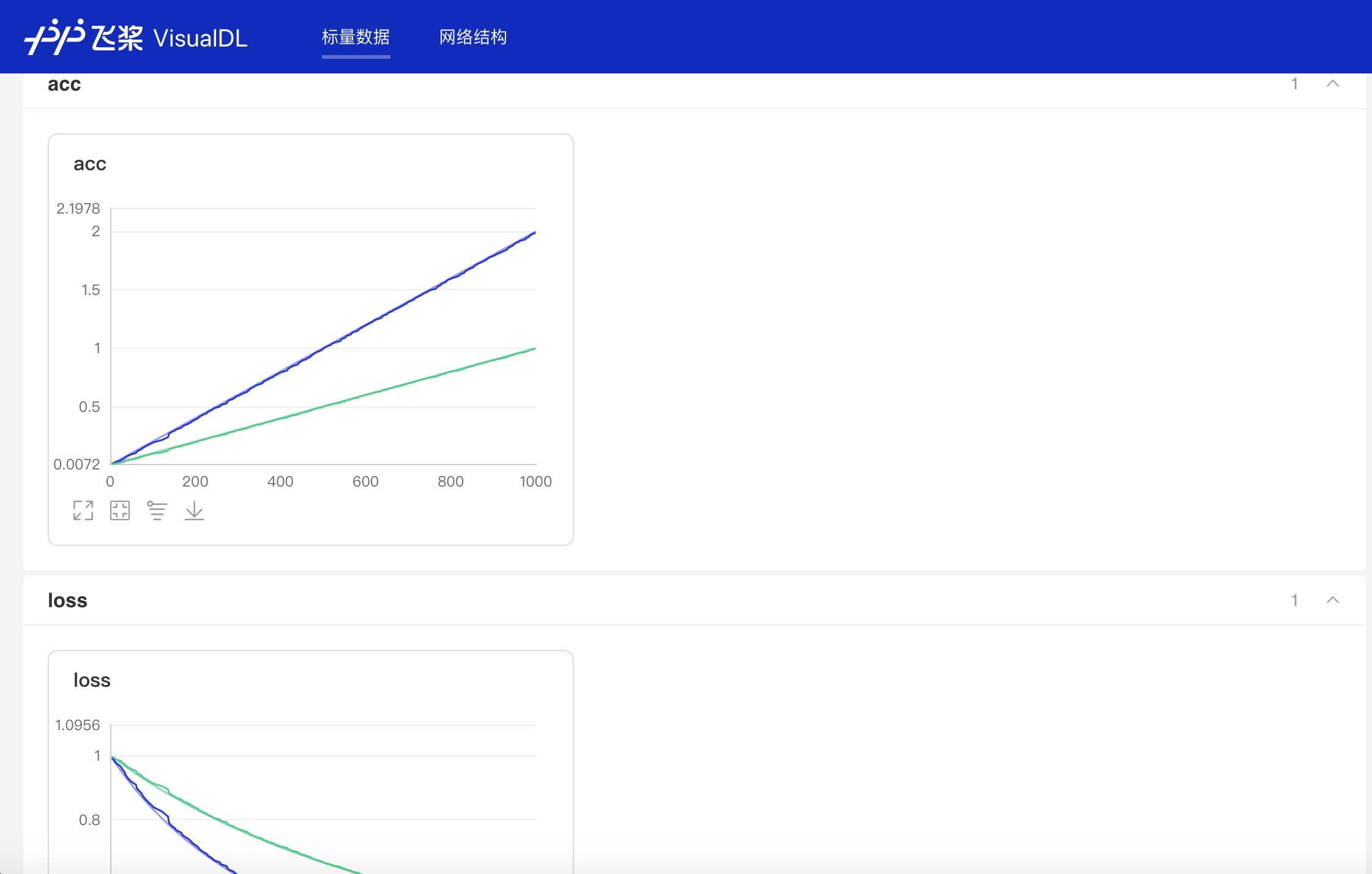
writer.add_scalar(tag="loss", step=step, value=1/(value[step] + 1))运行上述程序后,点击可视化选择相应日志文件即可查看可视化结果:
下面展示了使用Scalar组件实现多组实验对比 多组实验对比的实现分为两步: 1、创建子日志文件储存每组实验的参数数据 2、将数据写入scalar组件时,使用相同的tag,即可实现对比不同实验的同一类型参数 from visualdl import LogWriter
if __name__ == '__main__':
value = [i/1000.0 for i in range(1000)]
# 步骤一:创建父文件夹:log与子文件夹:scalar_test
with LogWriter(logdir="./log/scalar_test") as writer:
for step in range(1000):
# 步骤二:向记录器添加一个tag为`train/acc`的数据
writer.add_scalar(tag="train/acc", step=step, value=value[step])
# 步骤二:向记录器添加一个tag为`train/loss`的数据
writer.add_scalar(tag="train/loss", step=step, value=1/(value[step] + 1))
# 步骤一:创建第二个子文件夹scalar_test2
value = [i/500.0 for i in range(1000)]
with LogWriter(logdir="./log/scalar_test2") as writer:
for step in range(1000):
# 步骤二:在同样名为`train/acc`下添加scalar_test2的accuracy的数据
writer.add_scalar(tag="train/acc", step=step, value=value[step])
# 步骤二:在同样名为`train/loss`下添加scalar_test2的loss的数据
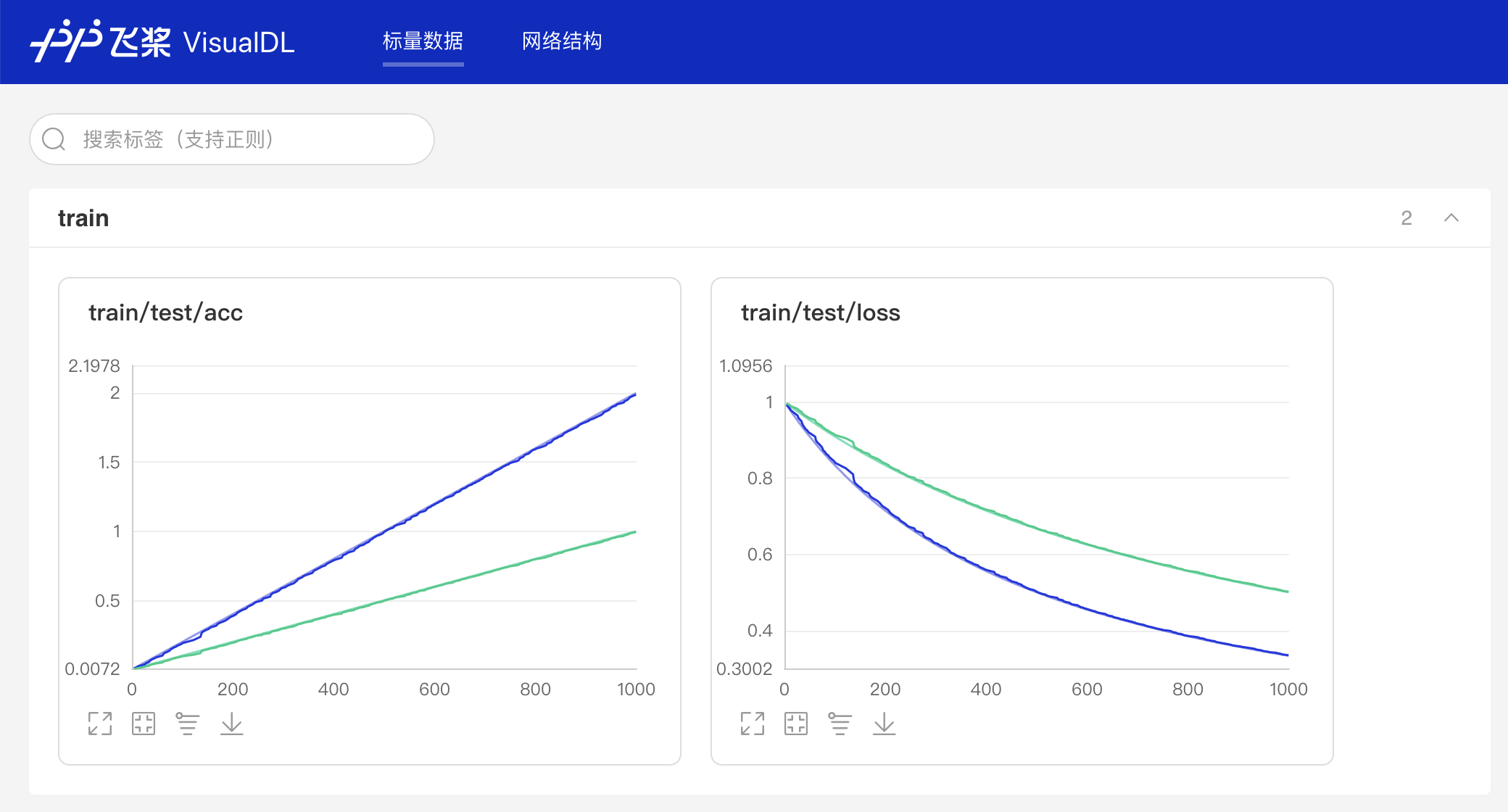
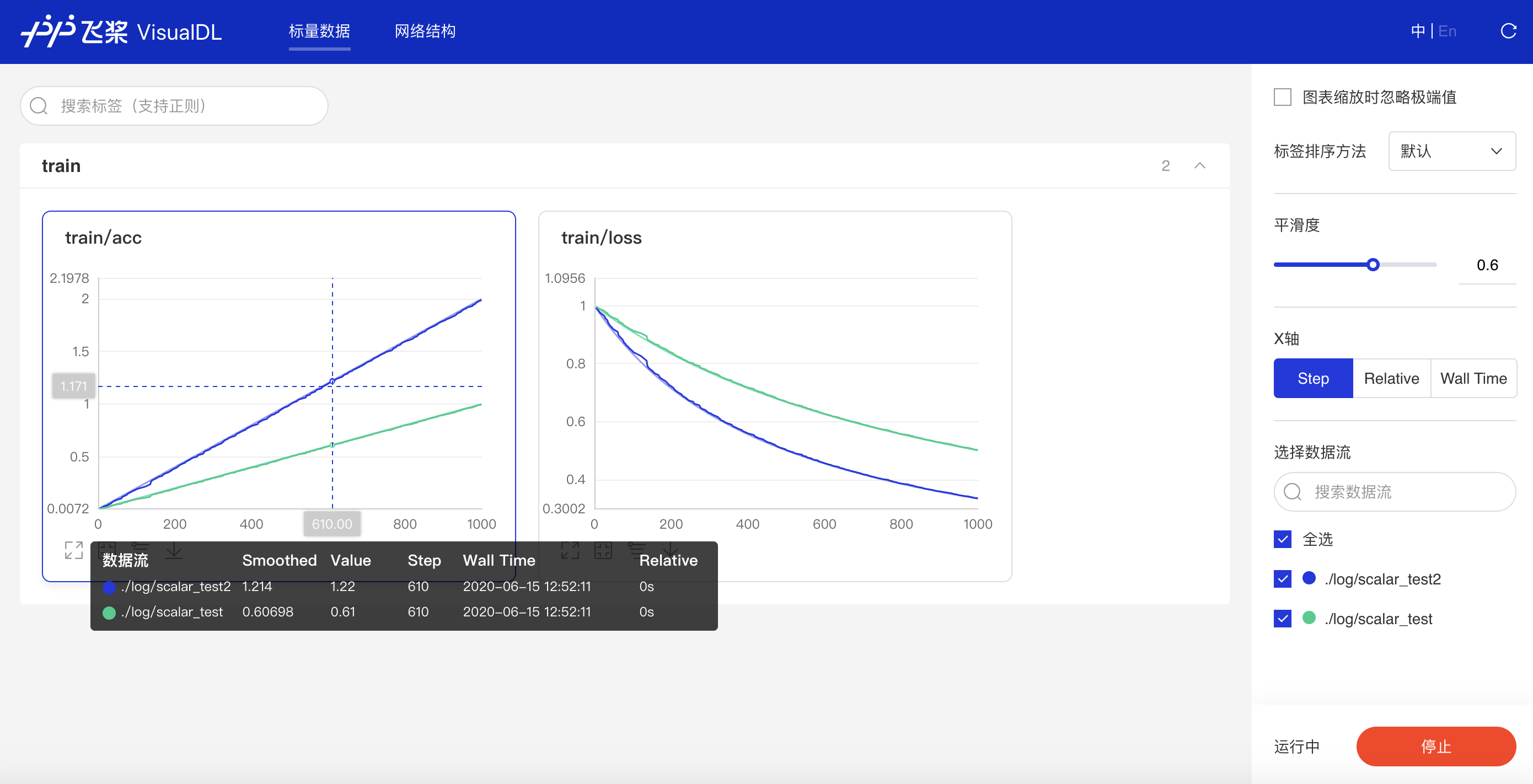
writer.add_scalar(tag="train/loss", step=step, value=1/(value[step] + 1))运行上述程序后,点击可视化选择相应日志文件即可查看以下折线图,观察scalar_test和scalar_test2的accuracy和loss的对比。
功能操作说明
1、Step:迭代次数
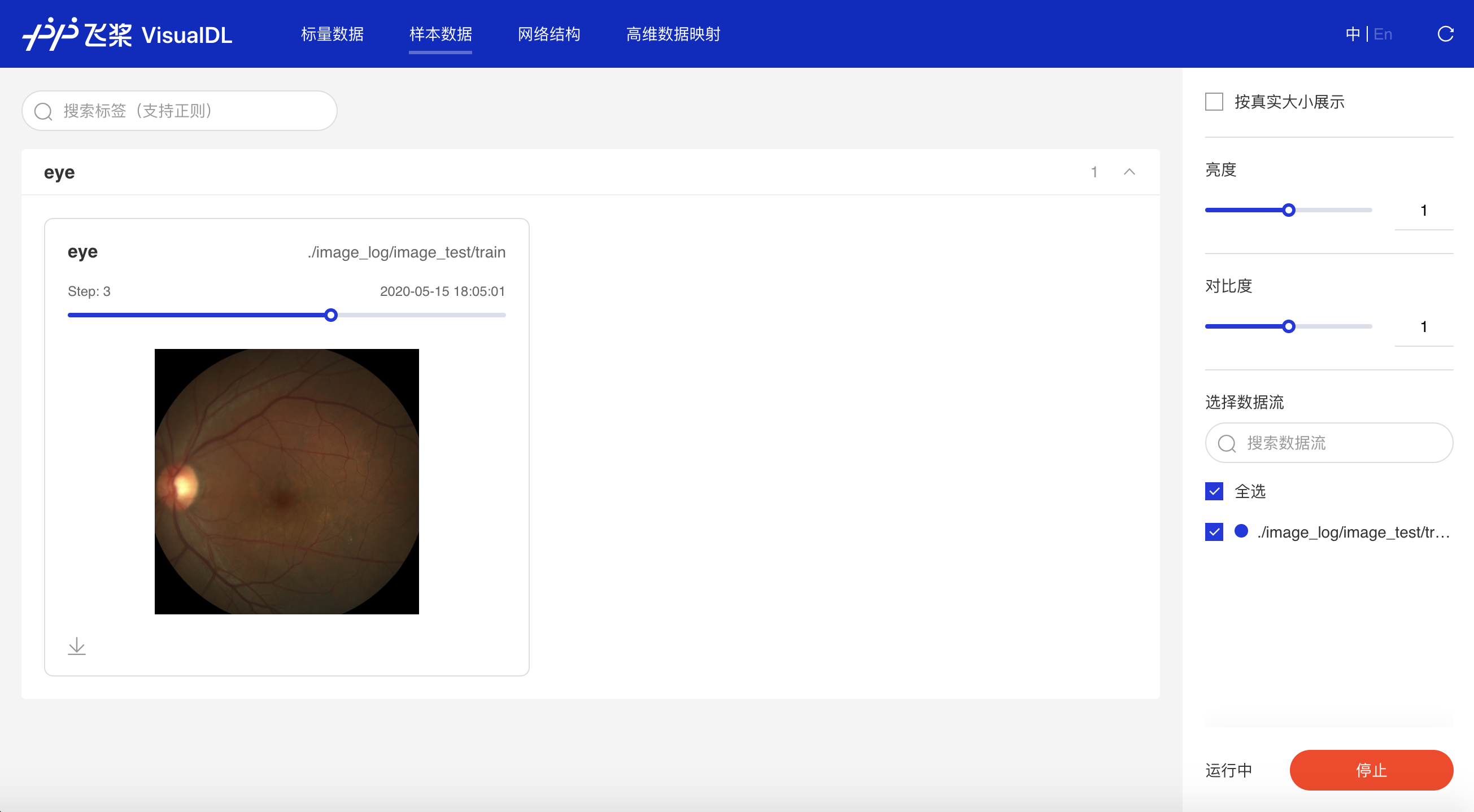
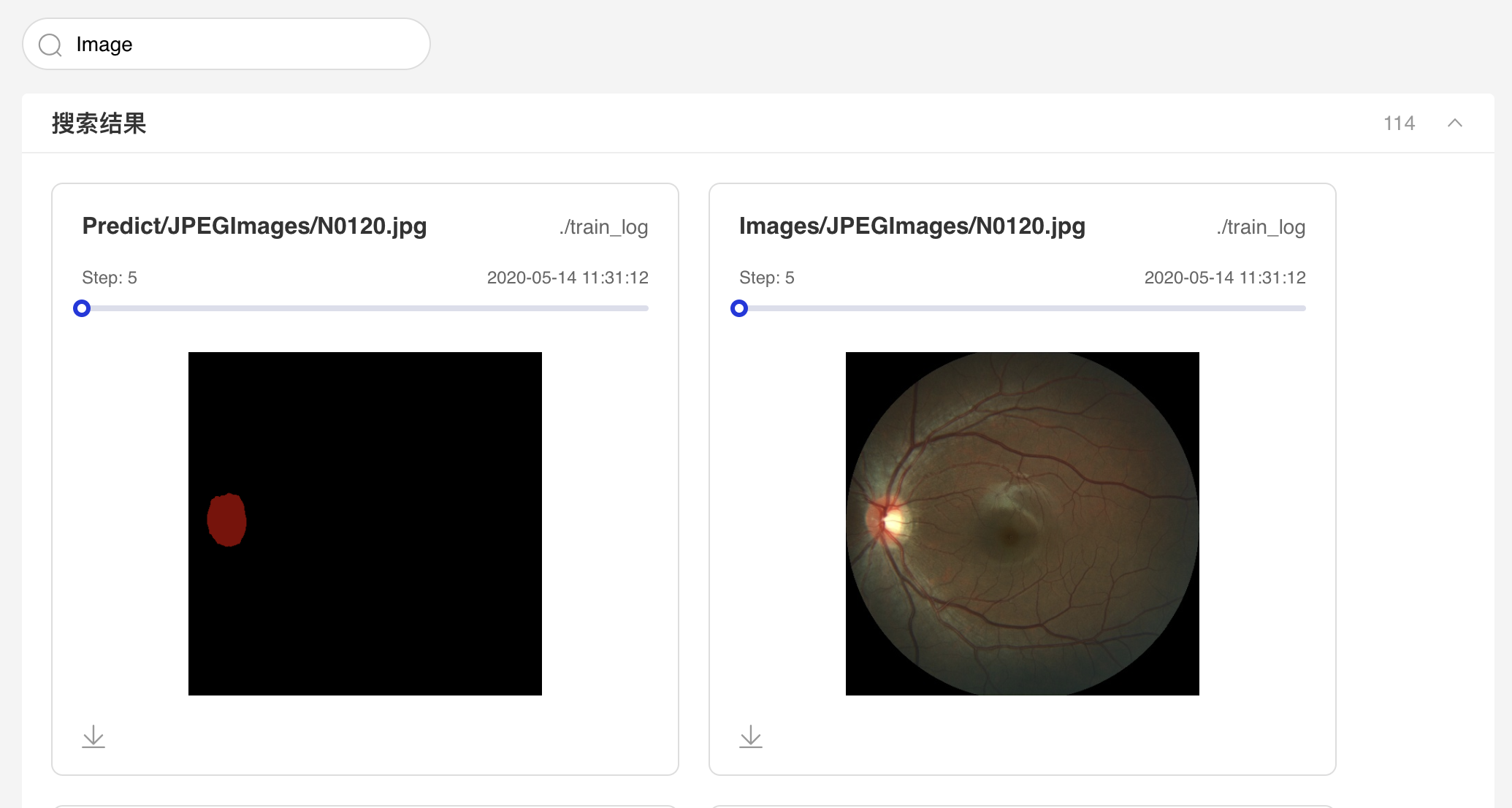
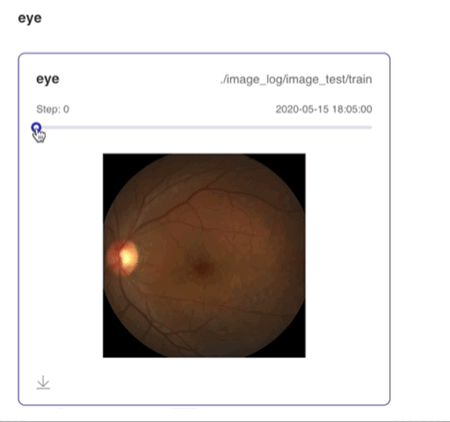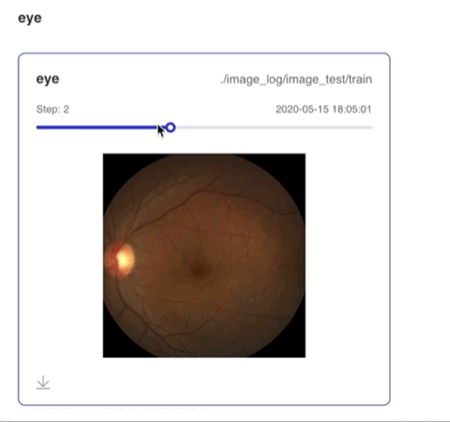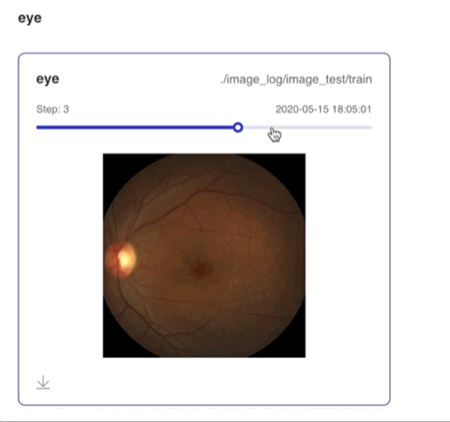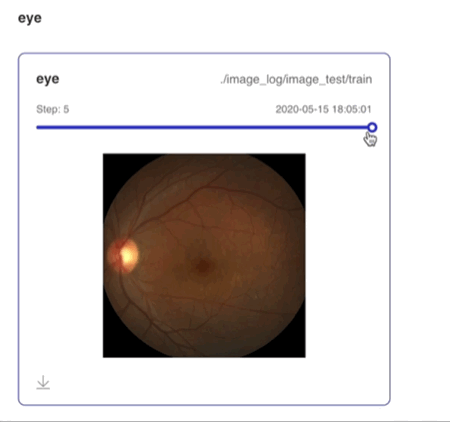
Image--图片可视化组件介绍 Image 组件用于显示图片数据随训练的变化。在模型训练过程中,将图片数据传入 Image 组件,就可在 VisualDL 的前端网页查看相应图片。 记录接口 Image 组件的记录接口如下:
接口参数说明如下:
Demo 下面展示了使用 Image 组件记录数据的示例: import numpy as np
from PIL import Image
from visualdl import LogWriter
def random_crop(img):
"""获取图片的随机 100x100 分片
"""
img = Image.open(img)
w, h = img.size
random_w = np.random.randint(0, w - 100)
random_h = np.random.randint(0, h - 100)
r = img.crop((random_w, random_h, random_w + 100, random_h + 100))
return np.asarray(r)
if __name__ == '__main__':
# 初始化一个记录器
with LogWriter(logdir="./log/image_test/train") as writer:
for step in range(6):
# 添加一个图片数据
writer.add_image(tag="eye",
img=random_crop("../../docs/images/eye.jpg"),
step=step)运行上述程序后,点击可视化选择相应日志文件即可查看可视化结果。
功能操作说明
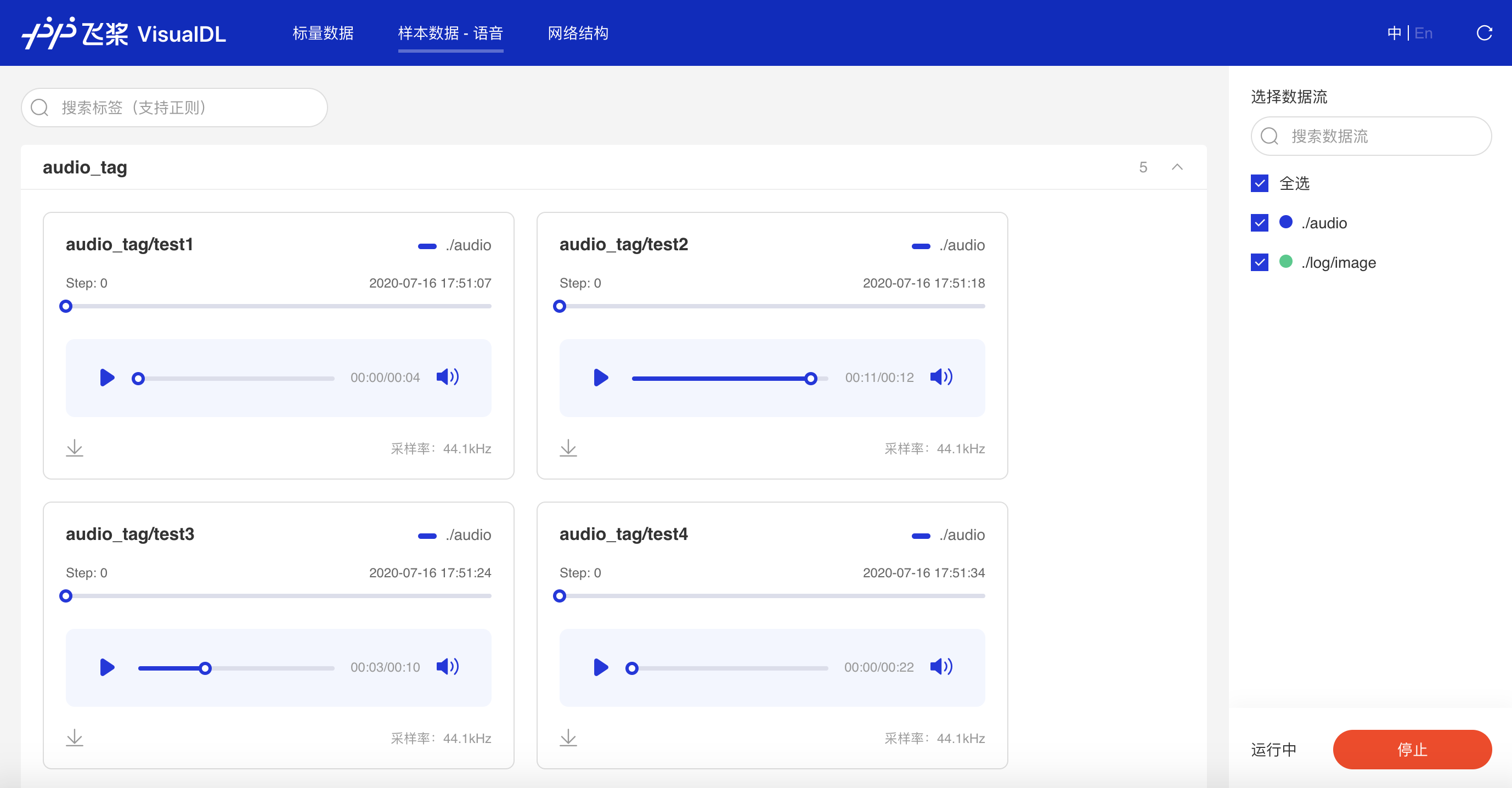
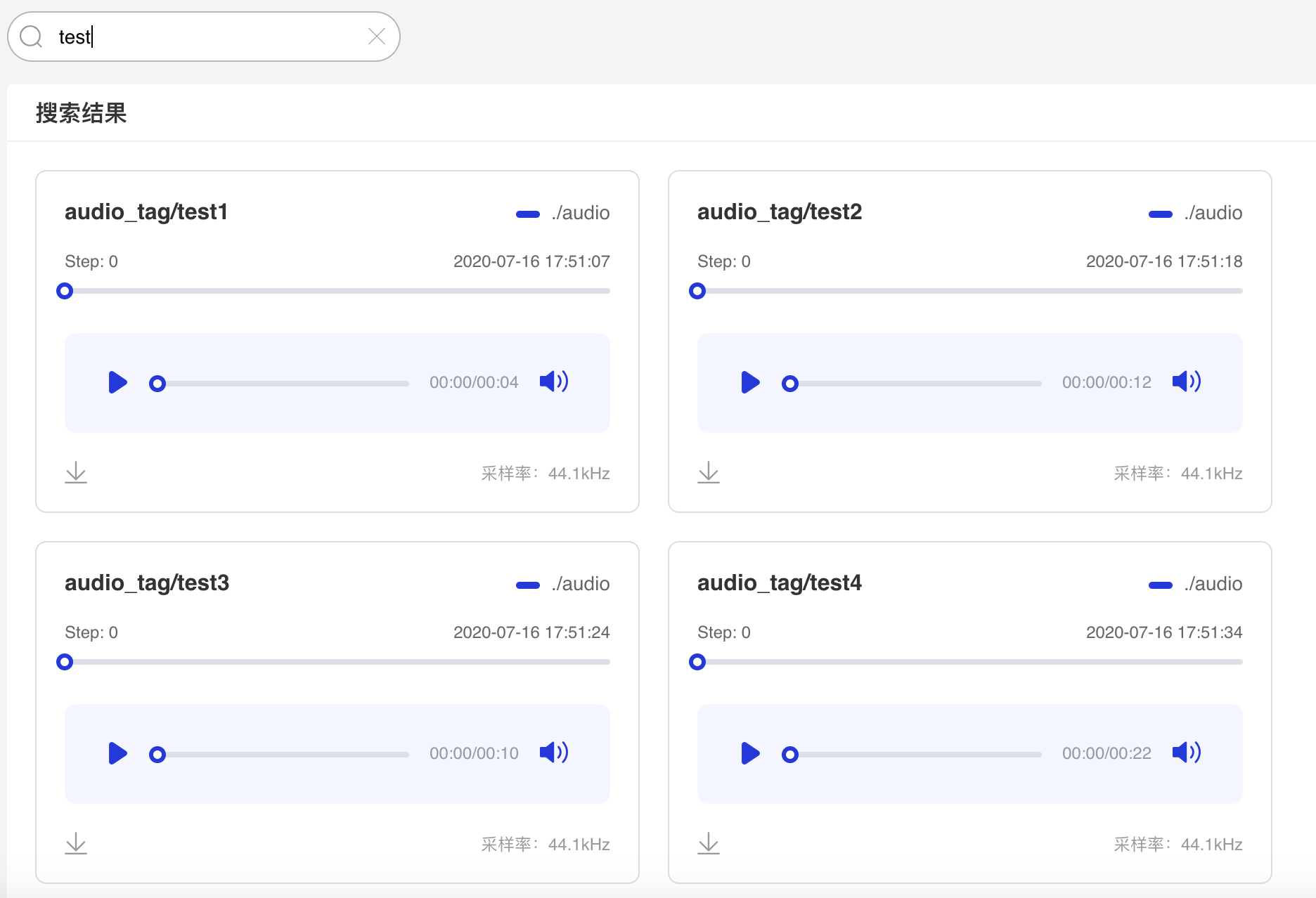
Audio--音频播放组件介绍 Audio组件实时查看训练过程中的音频数据,监控语音识别与合成等任务的训练过程。 记录接口 Audio 组件的记录接口如下:
接口参数说明如下:
Demo 下面展示了使用 Image 组件记录数据的示例: from visualdl import LogWriter
import numpy as np
import wave
def read_audio_data(audio_path):
"""
Get audio data.
"""
CHUNK = 4096
f = wave.open(audio_path, "rb")
wavdata = []
chunk = f.readframes(CHUNK)
while chunk:
data = np.frombuffer(chunk, dtype='uint8')
wavdata.extend(data)
chunk = f.readframes(CHUNK)
# 8k sample rate, 16bit frame, 1 channel
shape = [8000, 2, 1]
return shape, wavdata
if __name__ == '__main__':
with LogWriter(logdir="./log") as writer:
audio_shape, audio_data = read_audio_data("./testing.wav")
audio_data = np.array(audio_data)
writer.add_audio(tag="audio_tag",
audio_array=audio_data,
step=0,
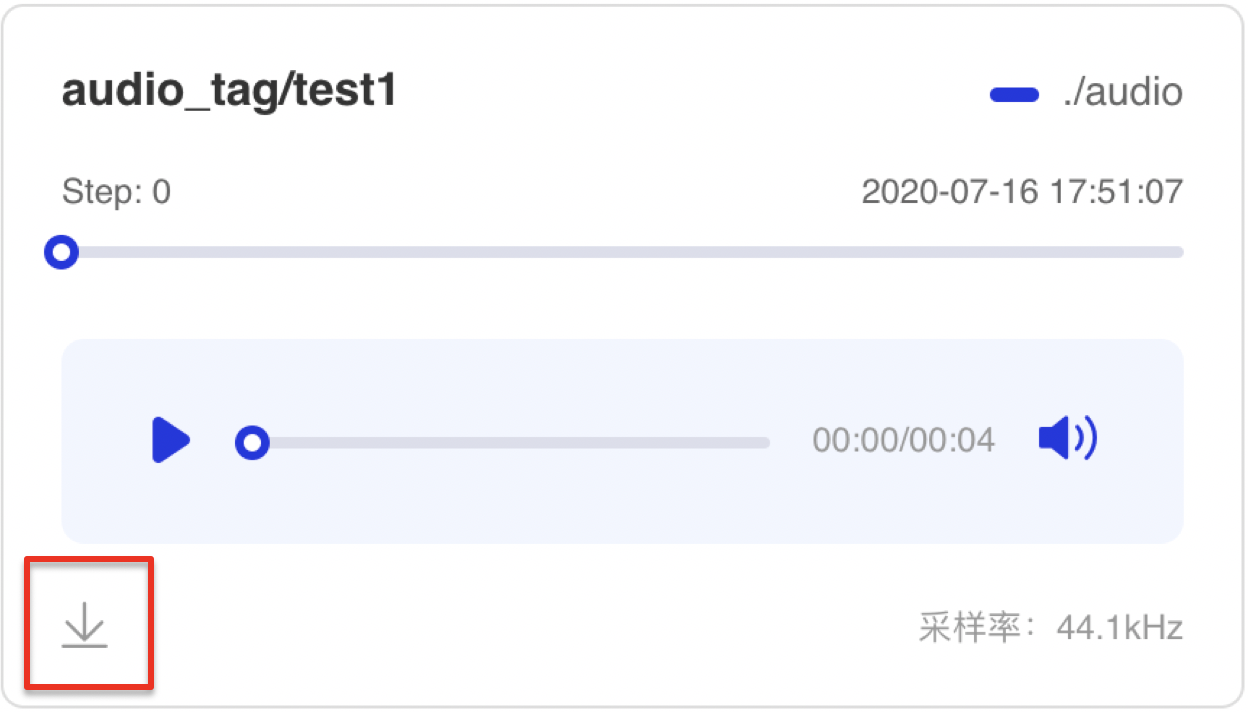
sample_rate=8000)运行上述程序后,点击可视化选择相应日志文件即可查看可视化结果。
功能操作说明
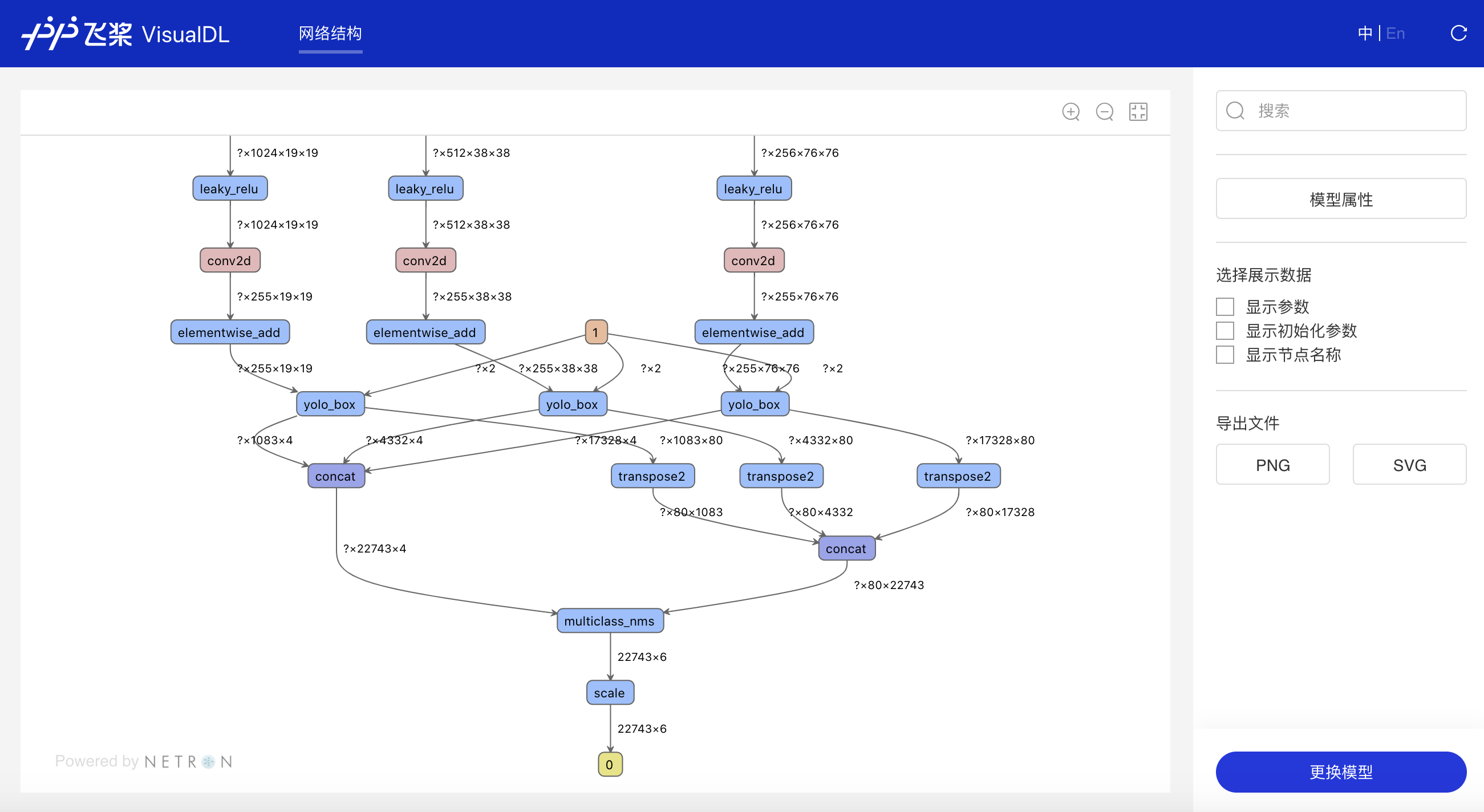
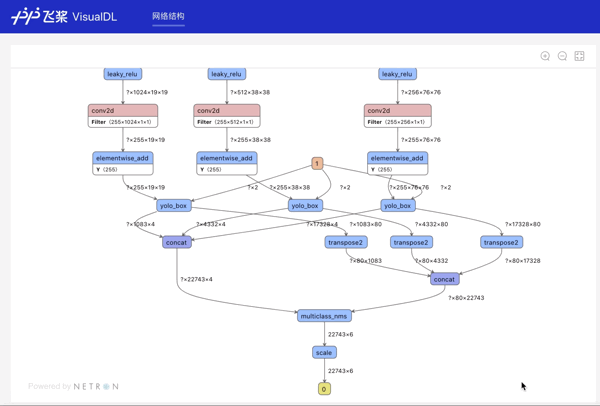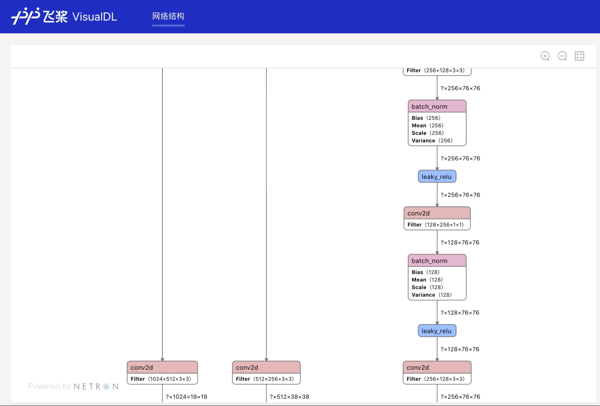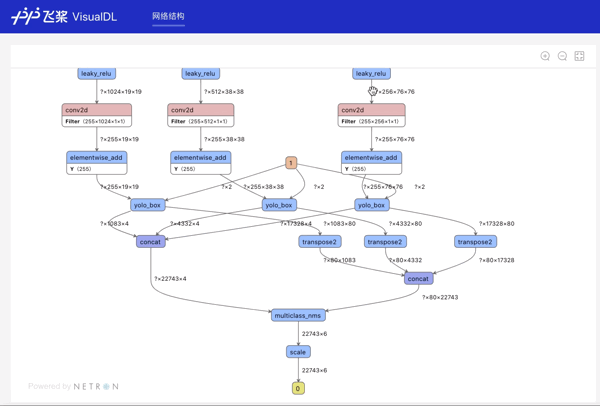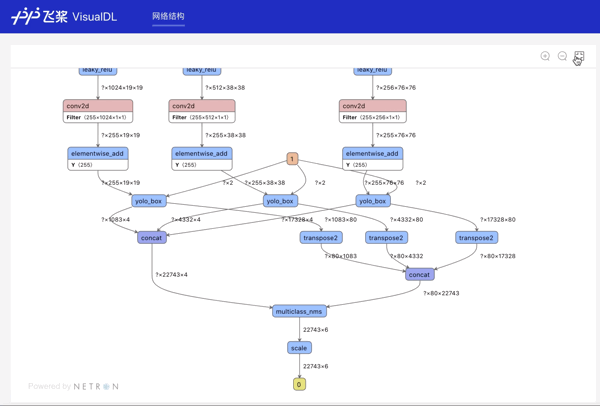
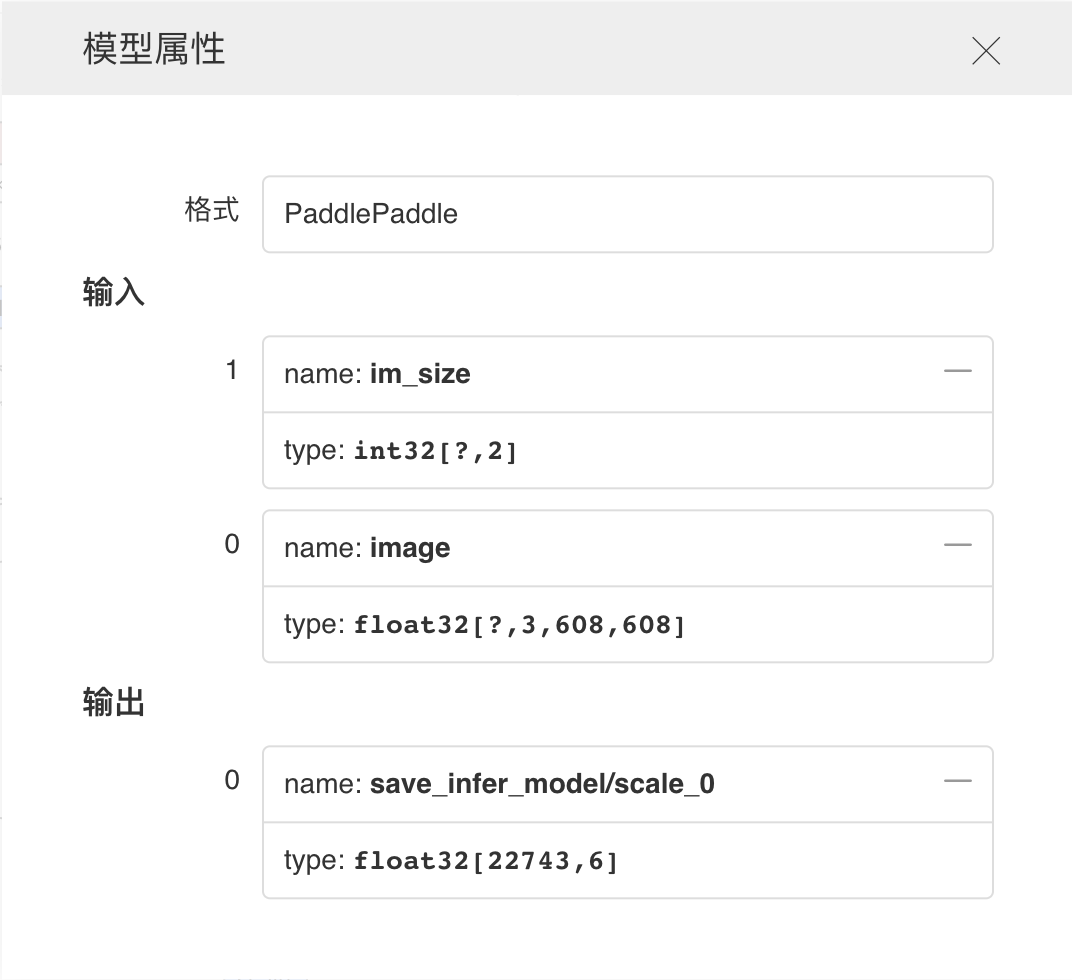
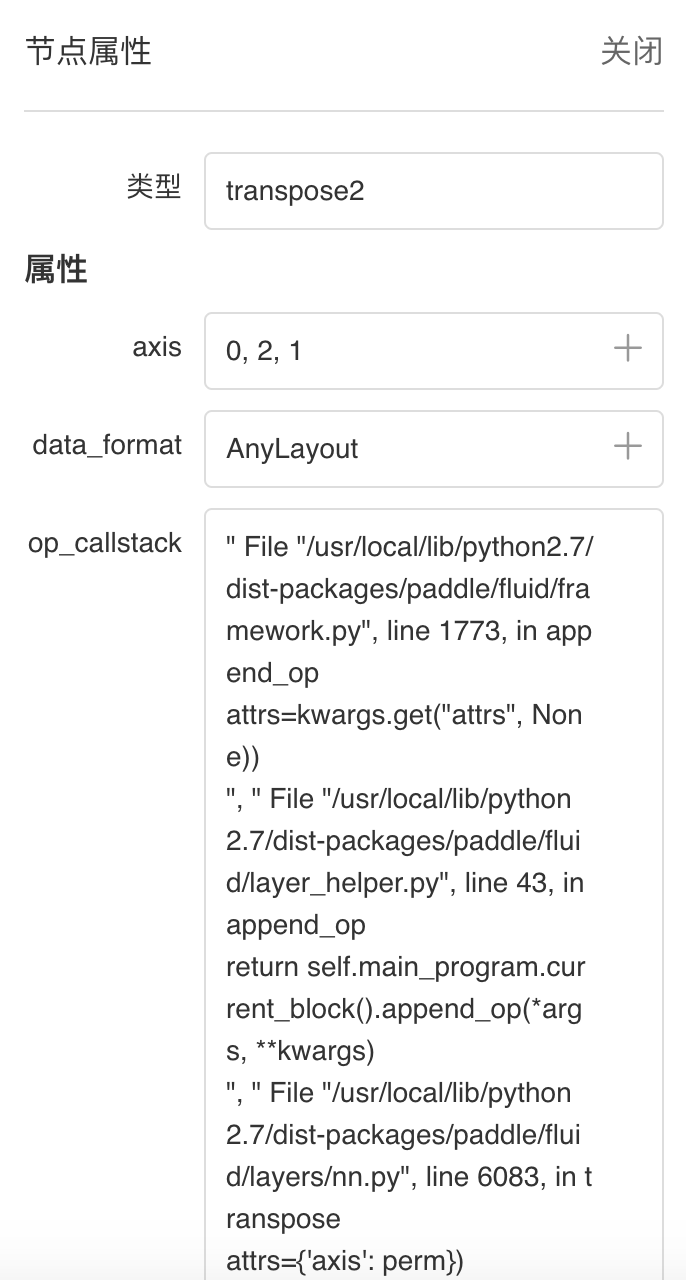
Graph--网络结构组件介绍 Graph组件一键可视化模型的网络结构。用于查看模型属性、节点信息、节点输入输出等,并进行节点搜索,协助开发者们快速分析模型结构与了解数据流向。 在生成Model文件后,在可视化模块中选择模型文件,启动后即可查看网络结构可视化:
功能操作说明
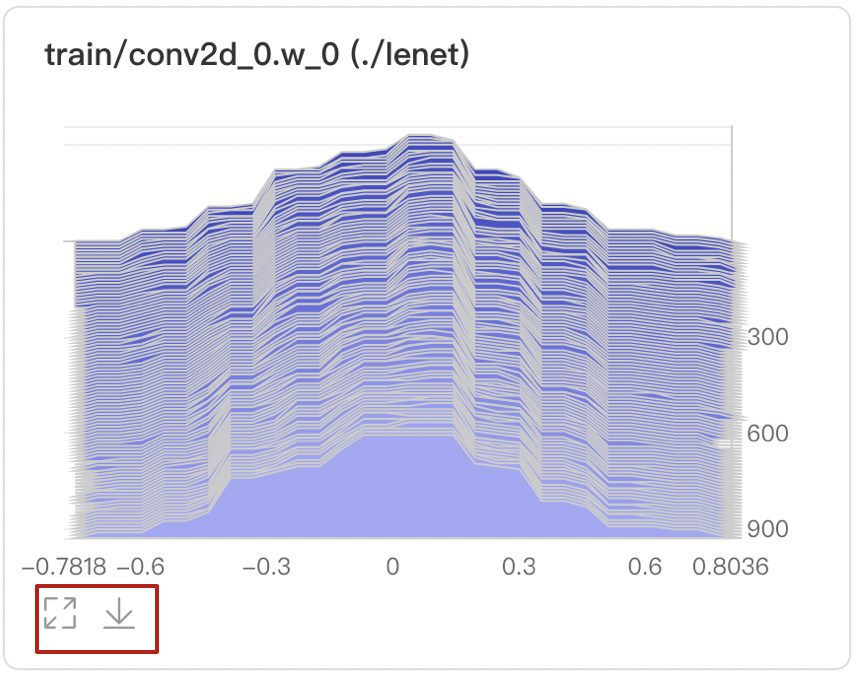
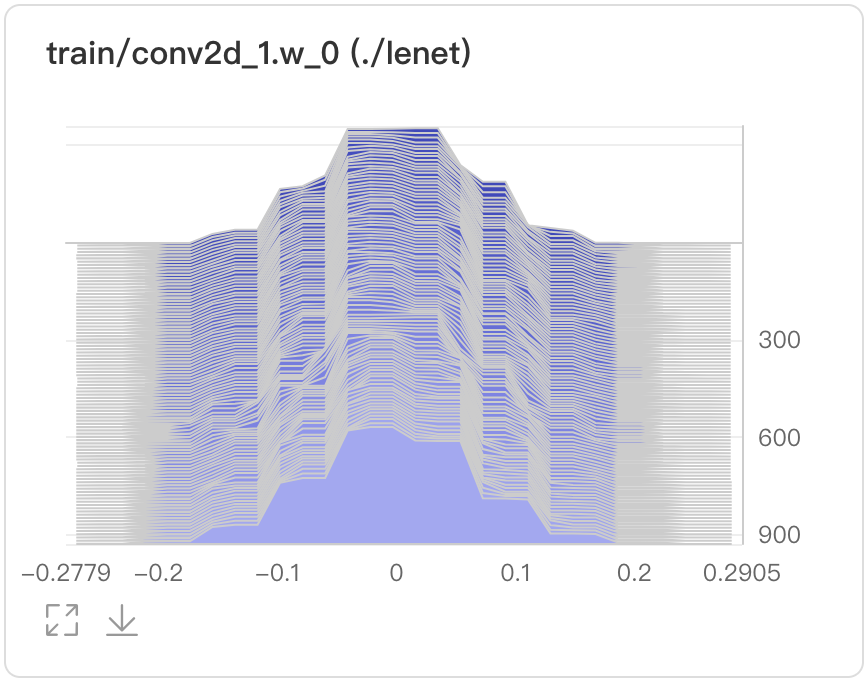
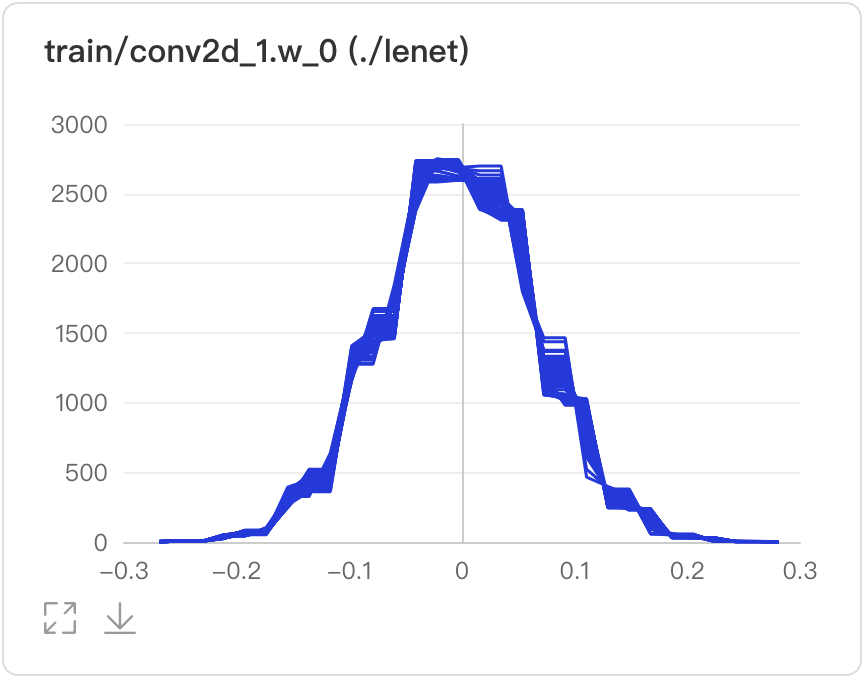
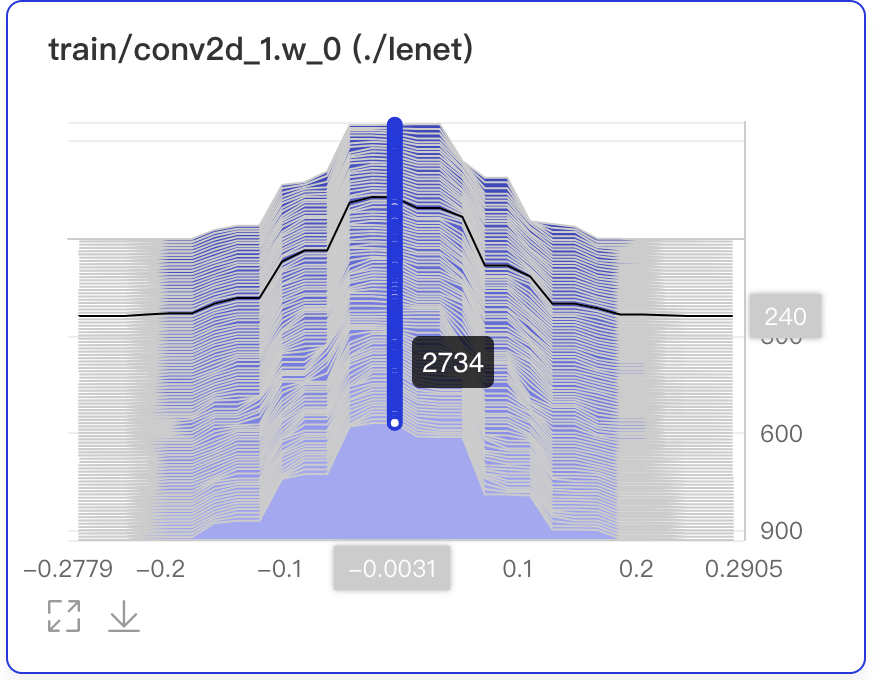
Histogram--直方图组件介绍 Histogram组件以直方图形式展示Tensor(weight、bias、gradient等)数据在训练过程中的变化趋势。深入了解模型各层效果,帮助开发者精准调整模型结构。 记录接口 Histogram 组件的记录接口如下:
接口参数说明如下:
Demo 下面展示了使用 Histogram 组件记录数据的示例: from visualdl import LogWriter
import numpy as np
if __name__ == '__main__':
values = np.arange(0, 1000)
with LogWriter(logdir="./log/histogram_test/train") as writer:
for index in range(1, 101):
interval_start = 1 + 2 * index / 100.0
interval_end = 6 - 2 * index / 100.0
data = np.random.uniform(interval_start, interval_end, size=(10000))
writer.add_histogram(tag='default tag',
values=data,
step=index,
buckets=10)运行上述程序后,点击可视化选择相应日志文件即可查看可视化结果。 功能操作说明
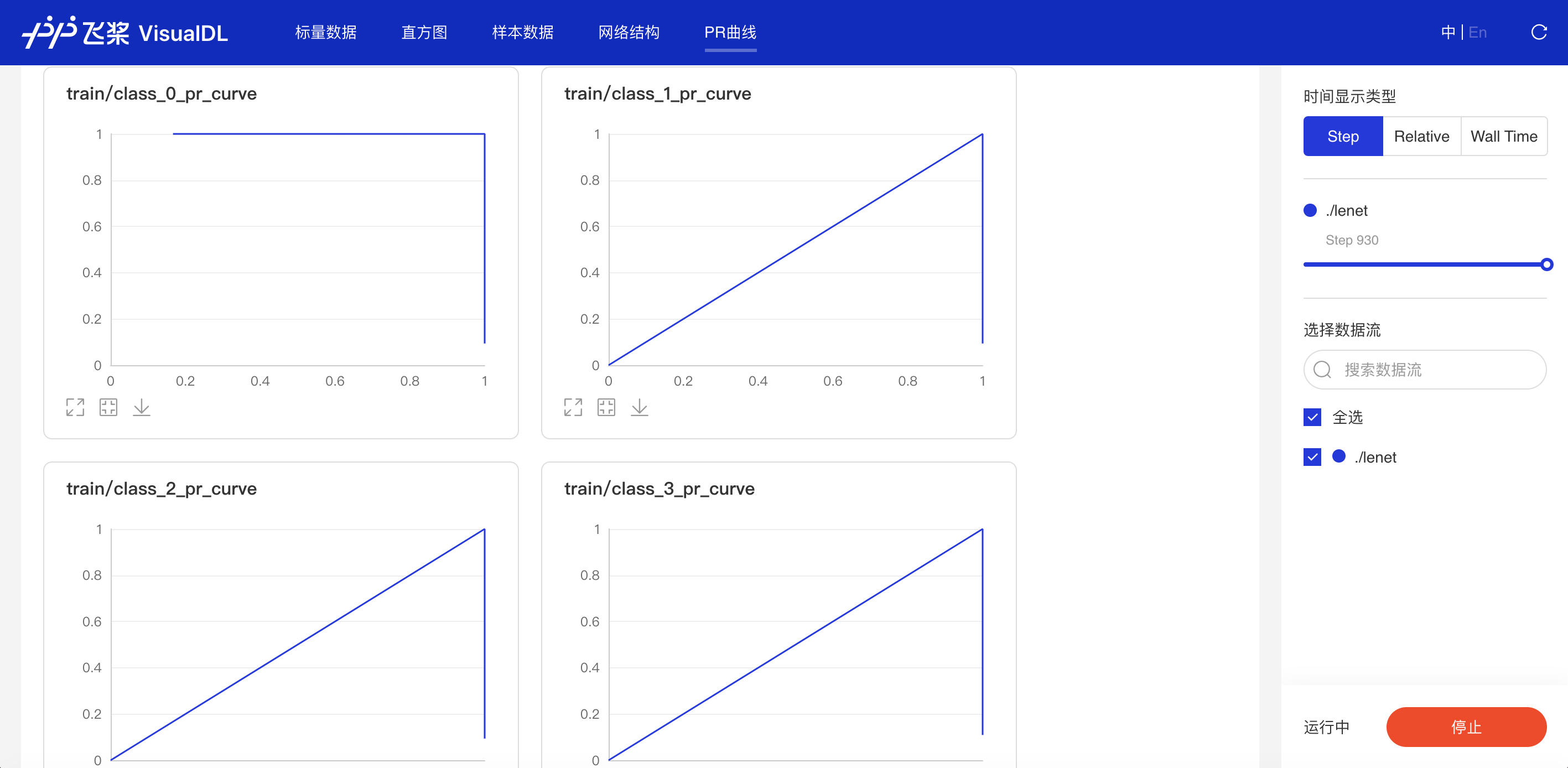
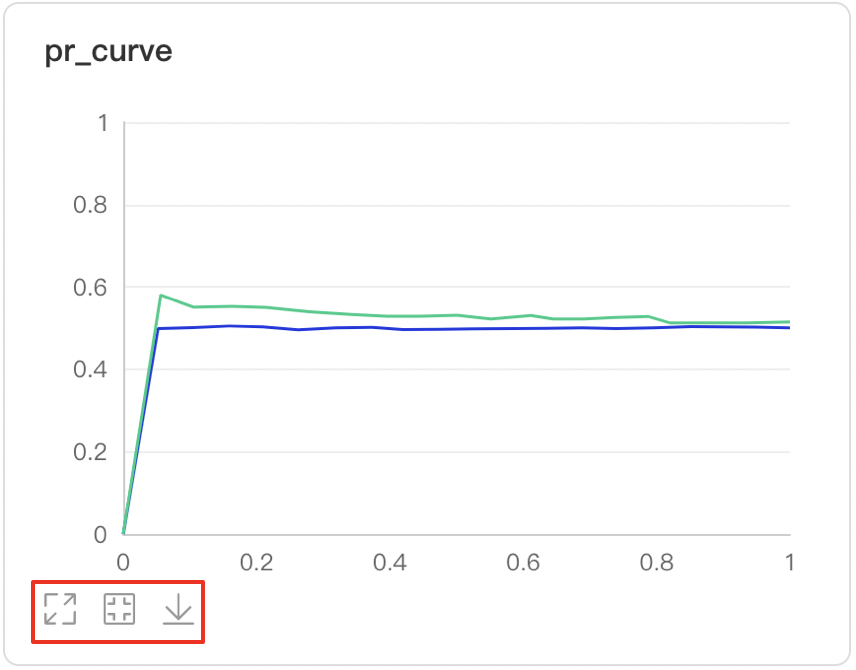
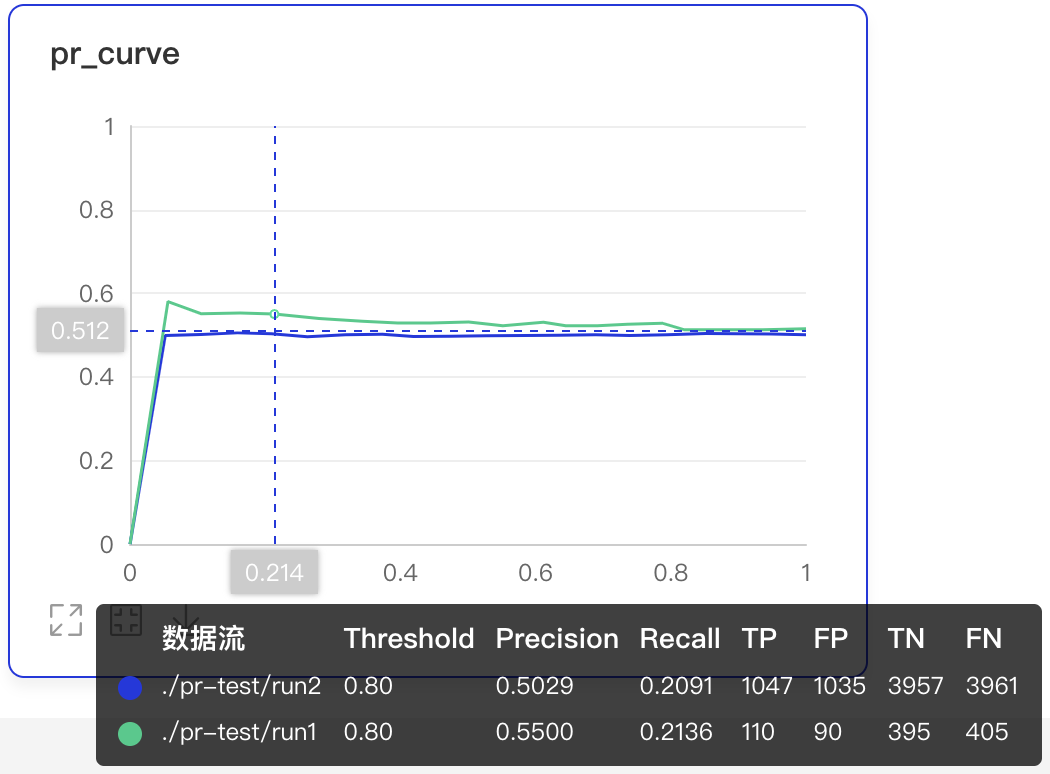
PR Curve--PR曲线组件介绍 PR Curve以折线图形式呈现精度与召回率的权衡分析,清晰直观了解模型训练效果,便于分析模型是否达到理想标准。 记录接口 PR Curve 组件的记录接口如下:
接口参数说明如下:
Demo 下面展示了使用 PR Curve 组件记录数据的示例: from visualdl import LogWriter
import numpy as np
with LogWriter("./log/pr_curve_test/train") as writer:
for step in range(3):
labels = np.random.randint(2, size=100)
predictions = np.random.rand(100)
writer.add_pr_curve(tag='pr_curve',
labels=labels,
predictions=predictions,
step=step,
num_thresholds=5)运行上述程序后,点击可视化选择相应日志文件即可查看可视化结果。
功能操作说明
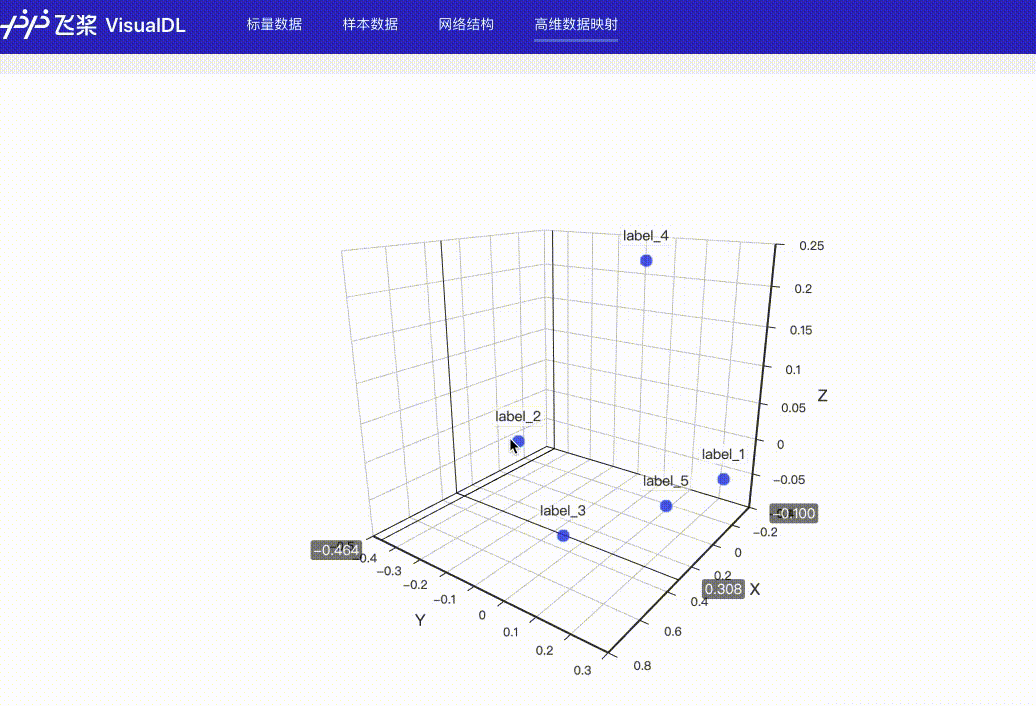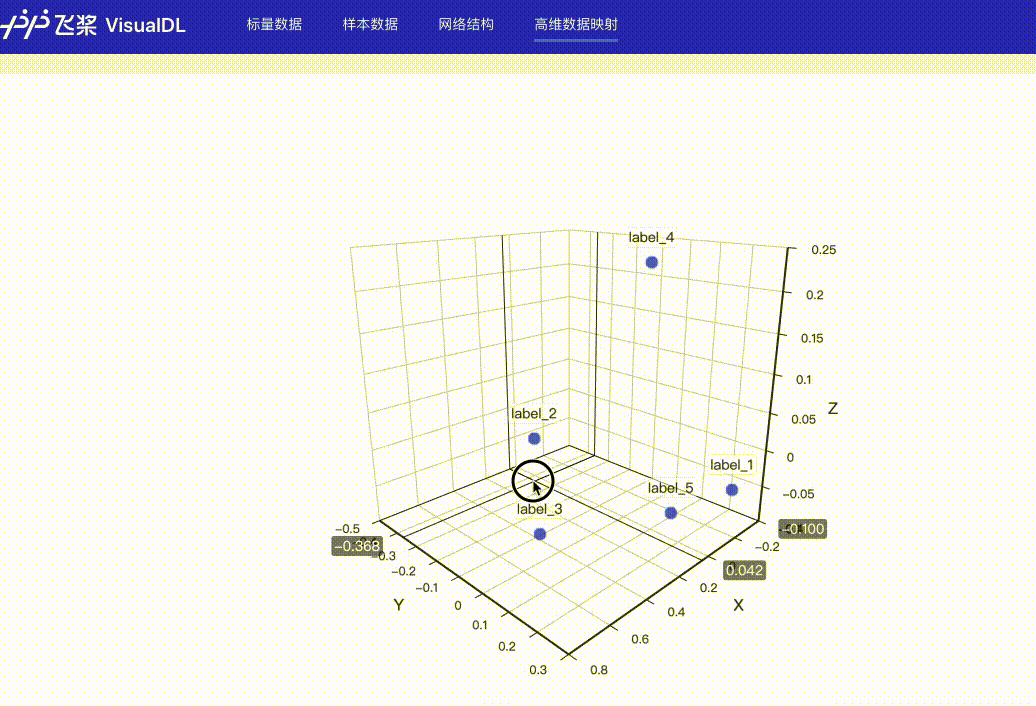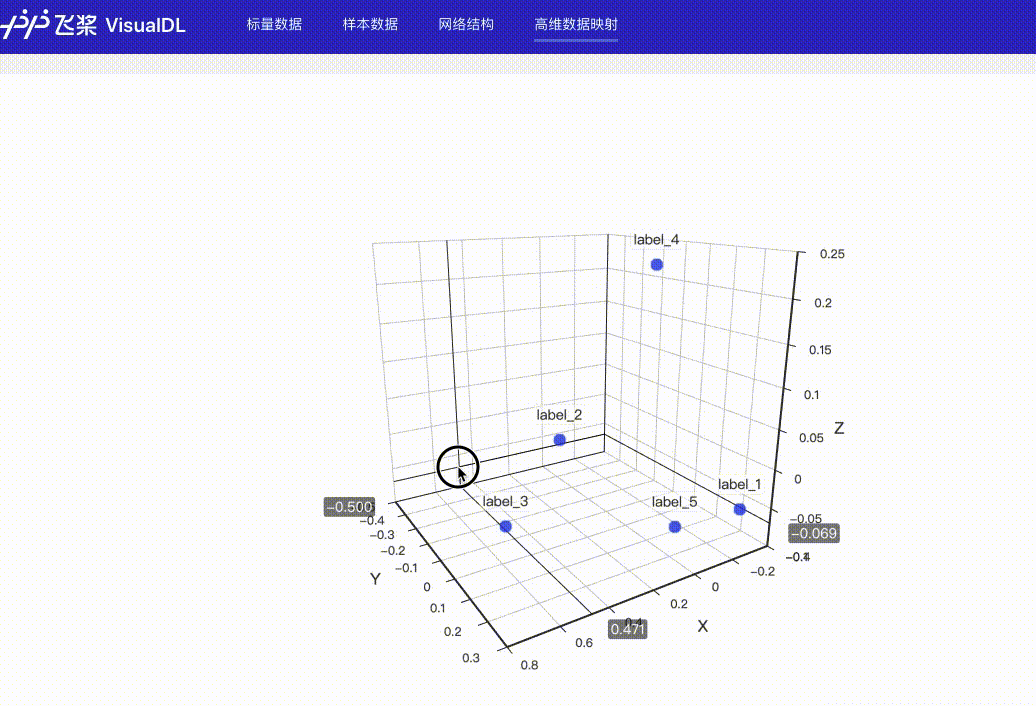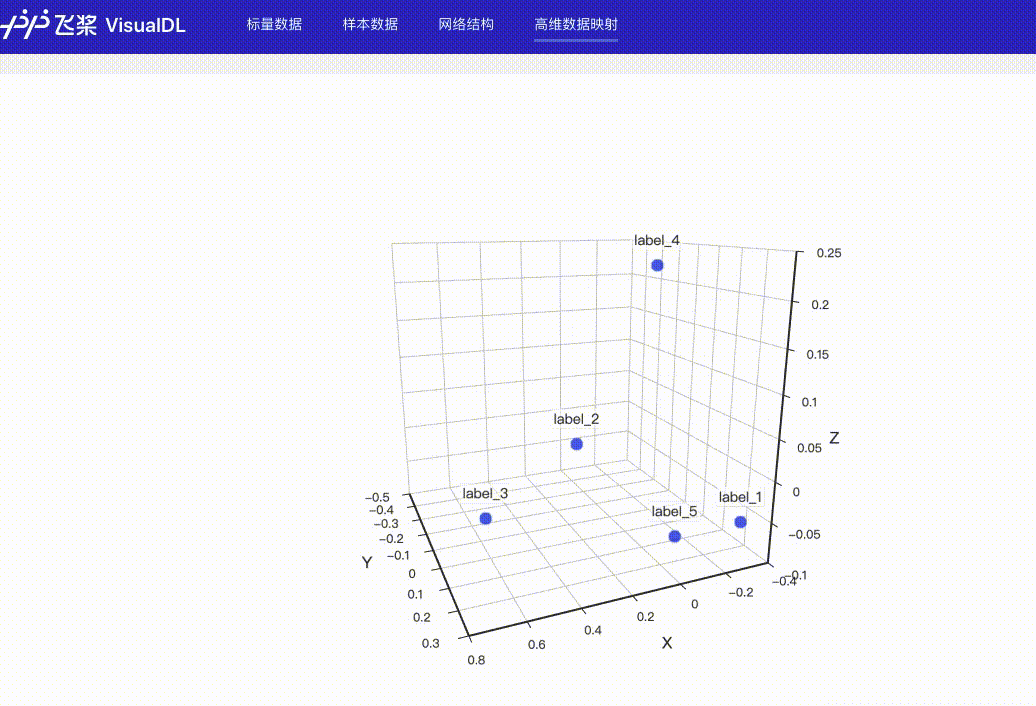
High Dimensional--数据降维组件介绍 High Dimensional 组件将高维数据进行降维展示,用于深入分析高维数据间的关系。目前支持以下两种降维算法:
记录接口 High Dimensional 组件的记录接口如下:
接口参数说明如下:
Demo 下面展示了使用 High Dimensional 组件记录数据的示例。 from visualdl import LogWriter
if __name__ == '__main__':
hot_vectors = [
[1.3561076367500755, 1.3116267195134017, 1.6785401875616097],
[1.1039614644440658, 1.8891609992484688, 1.32030488587171],
[1.9924524852447711, 1.9358920727142739, 1.2124401279391606],
[1.4129542689796446, 1.7372166387197474, 1.7317806077076527],
[1.3913371800587777, 1.4684674577930312, 1.5214136352476377]]
labels = ["label_1", "label_2", "label_3", "label_4", "label_5"]
# 初始化一个记录器
with LogWriter(logdir="./log/high_dimensional_test/train") as writer:
# 将一组labels和对应的hot_vectors传入记录器进行记录
writer.add_embeddings(tag='default',
labels=labels,
hot_vectors=hot_vectors)运行上述程序后,点击可视化选择相应日志文件即可查看可视化结果。
功能操作说明
|























 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477