| 百度智能云全功能AI开发平台BML-配置专家模式表格数据预测任务 | ||||||||||||||||||||||||||||||||||||||||||||||
|
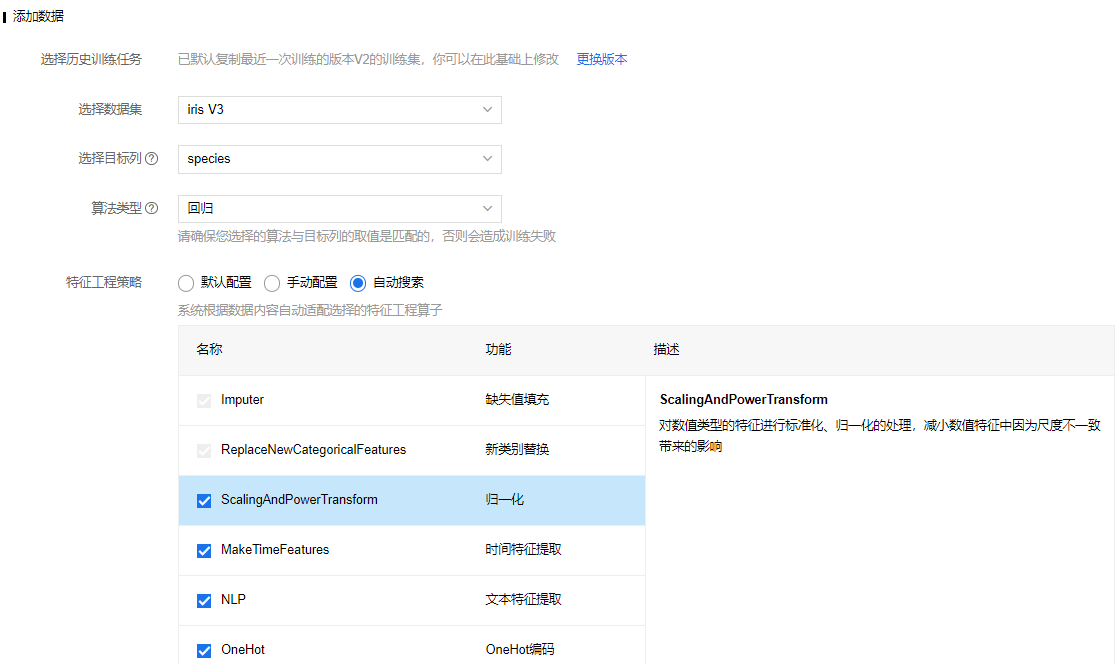
百度智能云全功能AI开发平台BML-配置专家模式表格数据预测任务 表格预测任务支持AutoML和专家两种运行方式:
创建专家建模任务操作场景以iris数据集为例,创建多分类模型,iris数据集示例如下: sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3.0,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa前提条件在创建表格预测任务前,需满足如下条件:
操作步骤
|





 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477