

1.标注体系说明
在序列标注任务中,一般会定义一个标签集合,来表示所有可能取到的预测结果。
标签是对字符串的token序列进行的表示:
对于英文字符串而言,token可以是一个单词(e.g. baidu),也可以是一个字符(e.g. b);
对于中文字符串而言,token可以是一个分词后的词语,也可以是单个汉字字符;
当前平台支持主流的IOB、IO、IOE、IOBES四种标注体系:
- IOB: 标签B用于文本块的开始,标签I用于文本块中的字符,标签O用于文本块之外的字符
- IOE: 标签I用于文本块中的字符,每个文本块都以标签E结尾,标签O用于文本块之外的字符
- IOBES: 包含了全部的5种标签,使用S标签表示文本块由单个字符组成;由一个以上的字符组成时,首字符总是使用B标签,尾字符总是使用E标签,中间的字符使用I标签
- IO: 只使用I和O标签,如果文本中有连续的同种类型实体的文本块,使用该标签方案不能够区分这种情况
可参考如下案例了解四种标注体系的区别和使用:
| 中 | 韩 | 对 | 抗 | 赛 | 中 | , | 于 | 大 | 宝 | 的 | 进 | 球 | 帮 | 中 | 国 | 队 | 获 | 胜 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOB | CN-B | KR-B | O | O | O | O | O | PER-B | PER-I | PER-I | O | O | O | O | ORG-B | ORG-I | ORG-I | O | O |
| IO | CN-I | KR-I | O | O | O | O | O | PER-I | PER-I | PER-I | O | O | O | O | ORG-I | ORG-I | ORG-I | O | O |
| IOE | CN-E | KR-E | O | O | O | O | O | PER-I | PER-I | PER-E | O | O | O | O | ORG-I | ORG-I | ORG-E | O | O |
| IOBES | CN-S | KR-S | O | O | O | O | O | PER-B | PER-I | PER-E | O | O | O | O | ORG-B | ORG-I | ORG-E | O | O |
英文的标注案例,请参考如下实例,注意由于ERNIE是由超大规模的中文知识语料进行的预训练模型,如果您需要在英文数据集上做序列标注任务,建议使用非ERNIE的任务进行训练。
====== ====== ====== ===== == ============ ===== ===== ===== == =========
Li Ming works at Agricultural Bank of China in Beijing.
====== ====== ====== ===== == ============ ===== ===== ===== == =========
IO I-PER I-PER O O I-ORG I-ORG I-ORG I-ORG O I-LOC
IOB B-PER I-PER O O B-ORG I-ORG I-ORG I-ORG O B-LOC
IOE I-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O E-LOC
IOBES B-PER E-PER O O B-ORG I-ORG I-ORG E-ORG O S-LOC
====== ====== ====== ===== == ============ ===== ===== ===== == =========2.标注数据格式说明
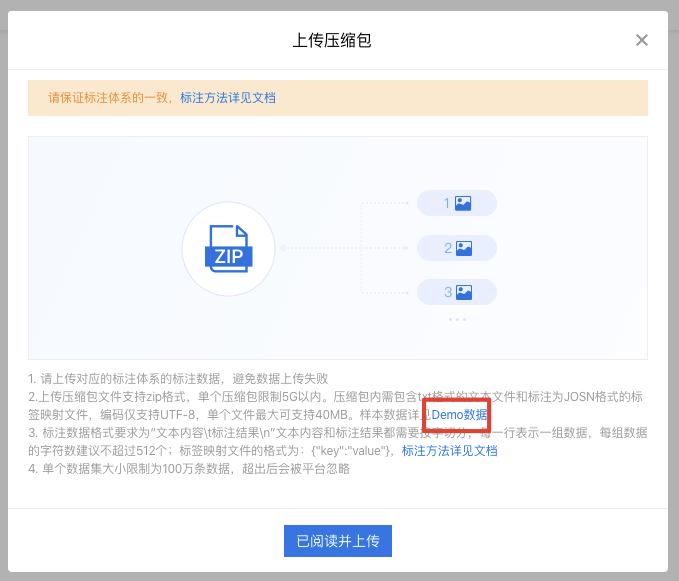
本文以平台推荐的IOB标注体系进行详细讲解。在平台上传数据集过程中,提供了快递关键信息抽取场景的示例数据以供参考,Demo数据下载,详见下方截图位置:
2.1 定义标签集合
在本示例场景中,针对需要被抽取的“姓名、电话、省、市、区、详细地址”等实体,标签集合可以定义为:
label = {P-B, P-I, T-B, T-I, A1-B, A1-I, A2-B, A2-I, A3-B, A3-I, A4-B, A4-I, O}
标签集合将会在后续上传平台时放在json文件中用到,详见下方“平台数据准备模块”
每个标签的定义分别为:
| 标签 | 说明 |
|---|---|
| P-B | 姓名起始位置 |
| P-I | 姓名中间位置或结束位置 |
| T-B | 电话起始位置 |
| T-I | 电话中间位置或结束位置 |
| A1-B | 省份起始位置 |
| A1-I | 省份中间位置或结束位置 |
| A2-B | 城市起始位置 |
| A2-I | 城市中间位置或结束位置 |
| A3-B | 县区起始位置 |
| A3-I | 县区中间位置或结束位置 |
| A4-B | 详细地址起始位置 |
| A4-I | 详细地址中间位置或结束位置 |
| O | 不关注的字 |
注意每个标签的结果只有 B、I、O 三种。其中 B 表示一个标签类别的开头,比如 P-B 指的是姓名的开头;相应的,I 表示一个标签的延续。此时四种标注体系中,B、I、O、E、S对应的解释也可总结为:
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- E,即End,表示结尾
- S,即Single,表示单个字符
- O,即Other,表示其他,用于标记无关字符
2.2对文本进行标注
对于句子“张三18625584663广东省深圳市南山区百度国际大厦”,每个汉字及对应标签为:
| 张 | 三 | 1 | 8 | 6 | 2 | 5 | 5 | 8 | 4 | 6 | 6 | 3 | 广 | 东 | 省 | 深 | 圳 | 市 | 南 | 山 | 区 | 百 | 度 | 国 | 际 | 大 | 厦 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P-B | P-I | T-B | T-I | T-I | T-I | T-I | T-I | T-I | T-I | T-I | T-I | T-I | A1-B | A1-I | A1-I | A2-B | A2-I | A2-I | A3-B | A3-I | A3-I | A4-B | A4-I | A4-I | A4-I | A4-I | A4-I |
注意到“张“,”三”在这里表示成了“P-B” 和 “P-I”,反过来讲,得到“P-B”和“P-I”这样的序列,也可以合并成“P” 这个标签。这样重新组合后可以得到以下信息抽取结果:
| 张三 | 18625584663 | 广东省 | 深圳市 | 南山区 | 百度国际大厦 |
|---|---|---|---|---|---|
| P | T | A1 | A2 | A3 | A4 |
在您任务配置过程中需要注意,如果您使用了ERNIE预训练模型,您需要对每一条样本进行字粒度的分词处理;如果您使用了非ERNIE的预置网络进行模型训练,则您需要对每一条样本进行词粒度的分词处理。
对于IO、IOBES、IOE三种标注体系,标注过程都类似,您可以根据您手中的训练集,在平台选择对应的标注体系进行数据集的上传。
3. 对应平台的数据集准备
将数据集上传平台,需要将上述2.1中的标签集合和标注文本以压缩包的形式上传。
在2.1中的标签集合为{P-B, P-I, T-B, T-I, A1-B, A1-I, A2-B, A2-I, A3-B, A3-I, A4-B, A4-I, O},对应的标签映射文件见下方(注意,平台对标签映射文件的文件名有要求,必须为”label_map.json“):
{
"P-B":0,
"P-I":1,
"T-B":2,
"T-I":3,
"A1-B":4,
"A1-I":5,
"A2-B":6,
"A2-I":7,
"A3-B":8,
"A3-I":9,
"A4-B":10,
"A4-I":11,
"O":12
}对2.2中的标注数据逐行保存,第一列为切词后的文本token,第二列为标注标签label。两列以制表符tab分开,即 token\tlabel\n,一行标注数据样例如下:
张 三 1 8 6 2 5 5 8 4 6 6 3 广 东 省 深 圳 市 南 山 区 百 度 国 际 大 厦 P-B P-I T-B T-I T-I T-I T-I T-I T-I T-I T-I T-I T-I A1-B A1-I A1-I A2-B A2-I A2-I A3-B A3-I A3-I A4-B A4-I A4-I A4-I A4-I A4-I 

 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477