| 百度智能云全功能AI开发平台BML-用BML实现序列标注 |
|
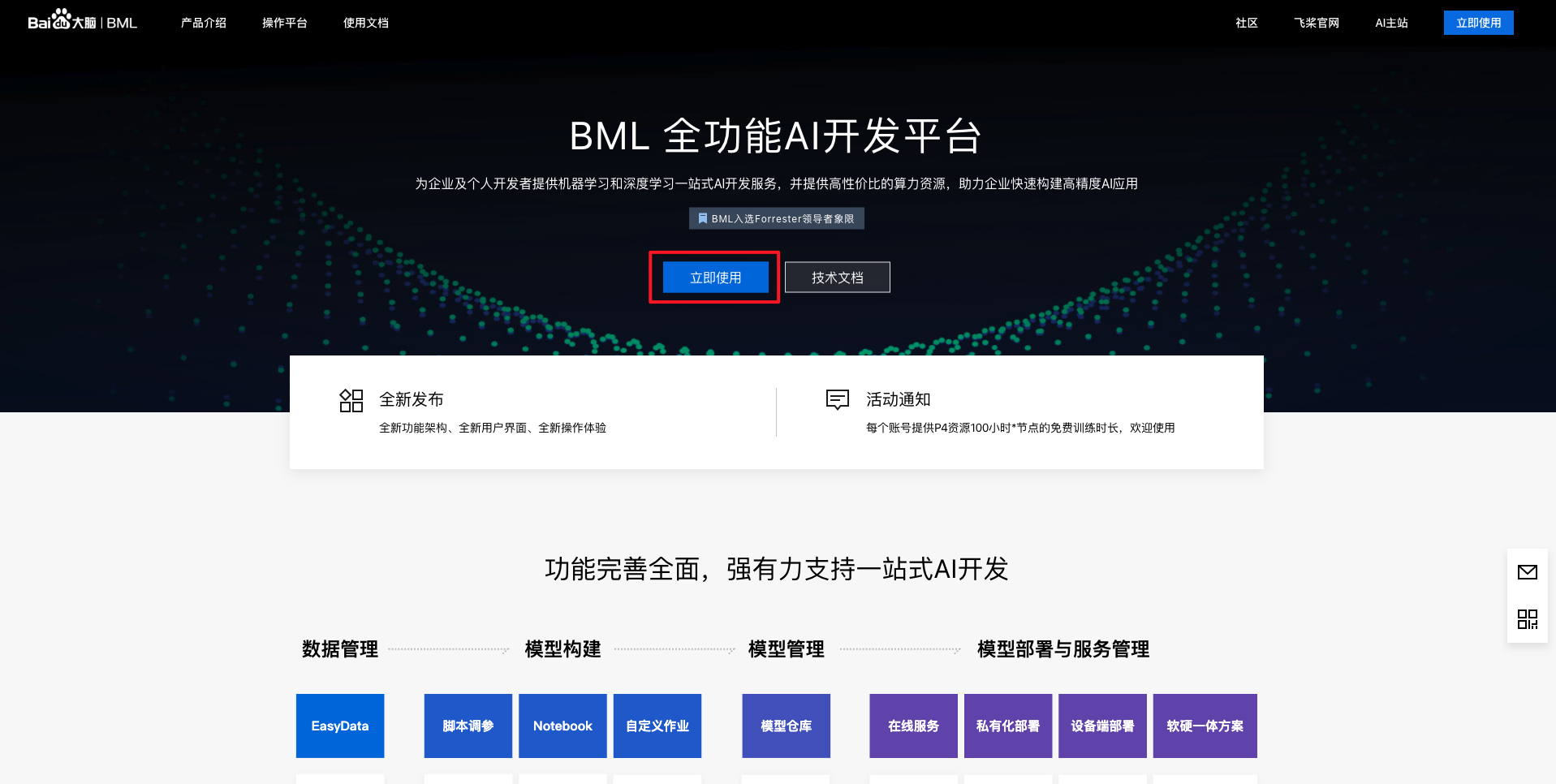
百度智能云全功能AI开发平台BML-用BML实现序列标注 用BML实现序列标注:以快递单信息处理为例序列标注简介亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅! 序列标注(Sequence Tagging)是NLP中最基础的任务,应用十分广泛,如分词、词性标注(POS tagging)、命名实体识别(Named Entity Recognition,NER)、关键词抽取、语义角色标注(Semantic Role Labeling)、槽位抽取(Slot Filling)等实质上都属于序列标注的范畴。 序列标注问题可以认为是分类问题的一个推广,或者是更复杂的结构预测(structure prediction)问题的简单形式。序列标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测。 下文中将以快递单信息处理为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的序列标注模型。 快递单信息处理任务简介: 平台入口BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限。 数据规范本地上传数据规范:
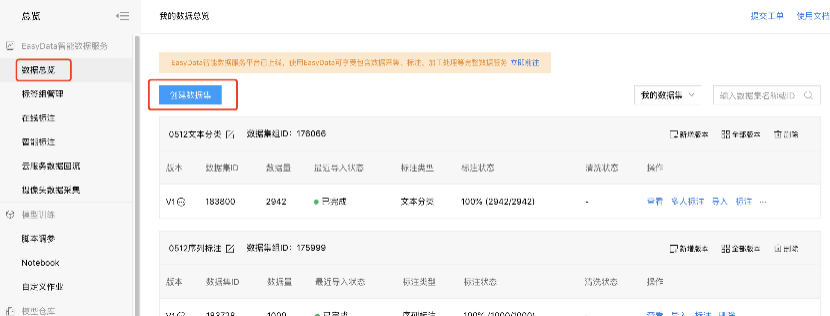
创建及导入数据集1、在官网界面点击【数据总览】,进入数据集操作界面。
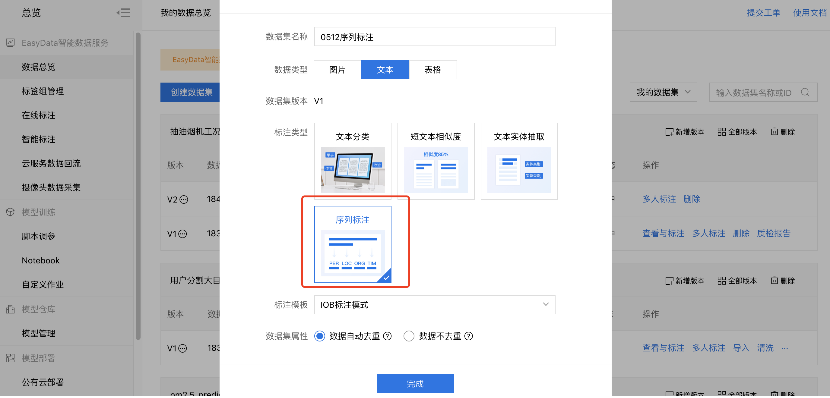
2、进入创建数据集界面,选择好数据类型和标注类型等信息,点击完成。
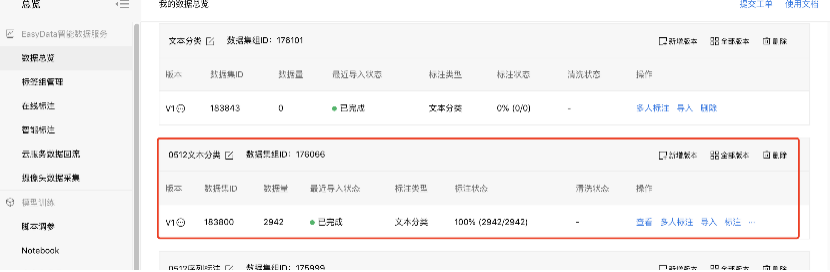
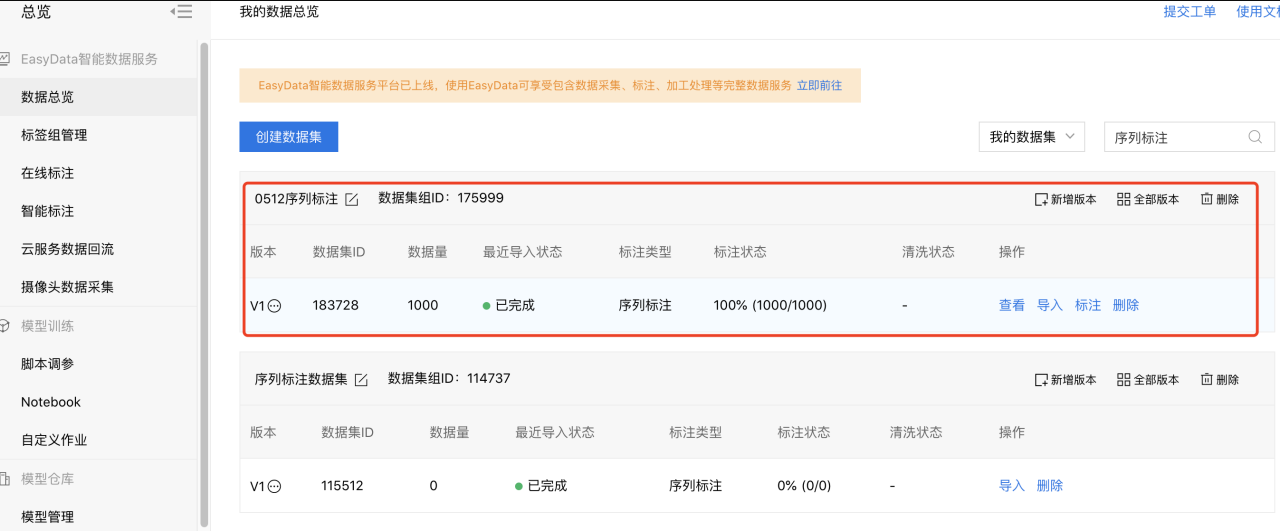
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID。
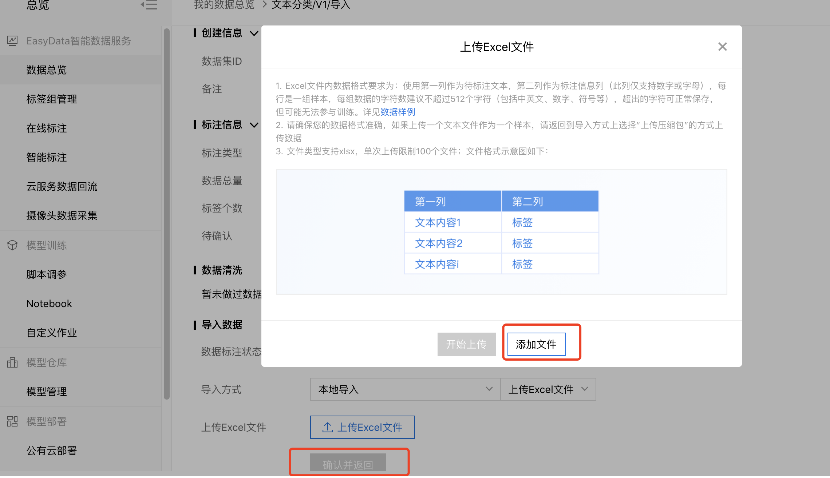
4、点击【导入】,将自己要训练的数据集导入,如这里选择本地导入Excel文件方式导入数据集,点击添加文件,然后确认并返回,完成数据集的导入。
5、回到数据总览界面,可实时查看导入状态信息和标注状态,最终成功则显示已完成。
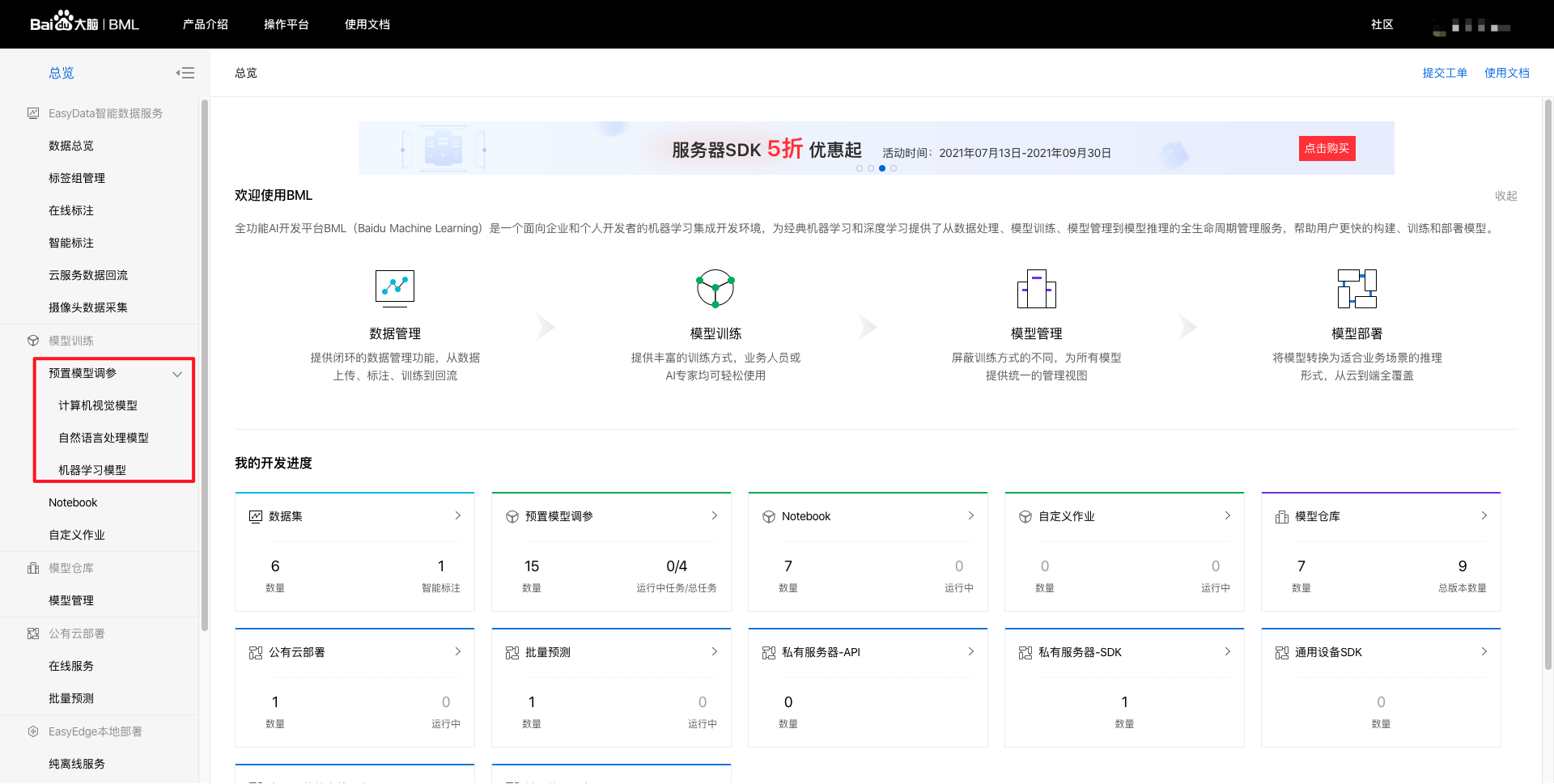
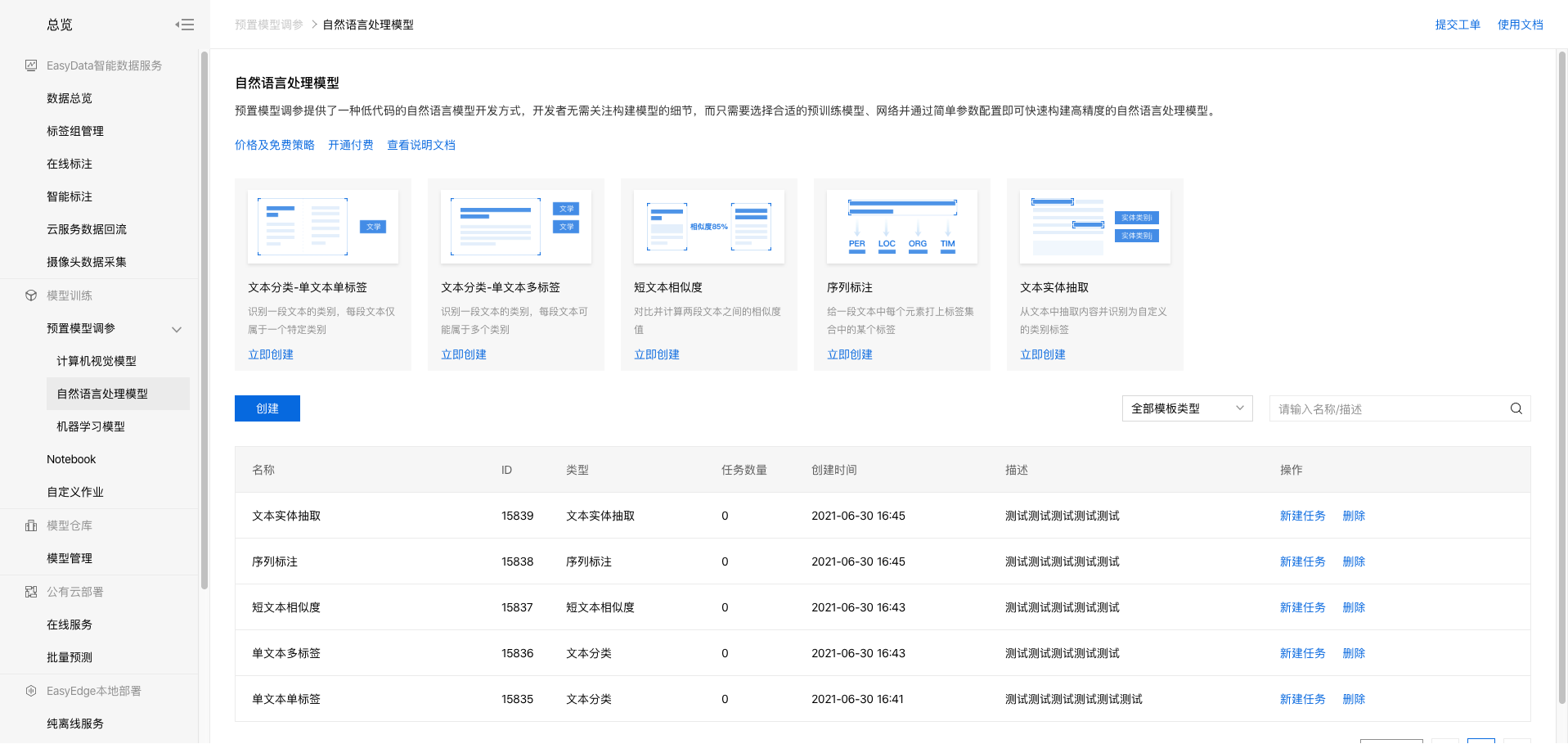
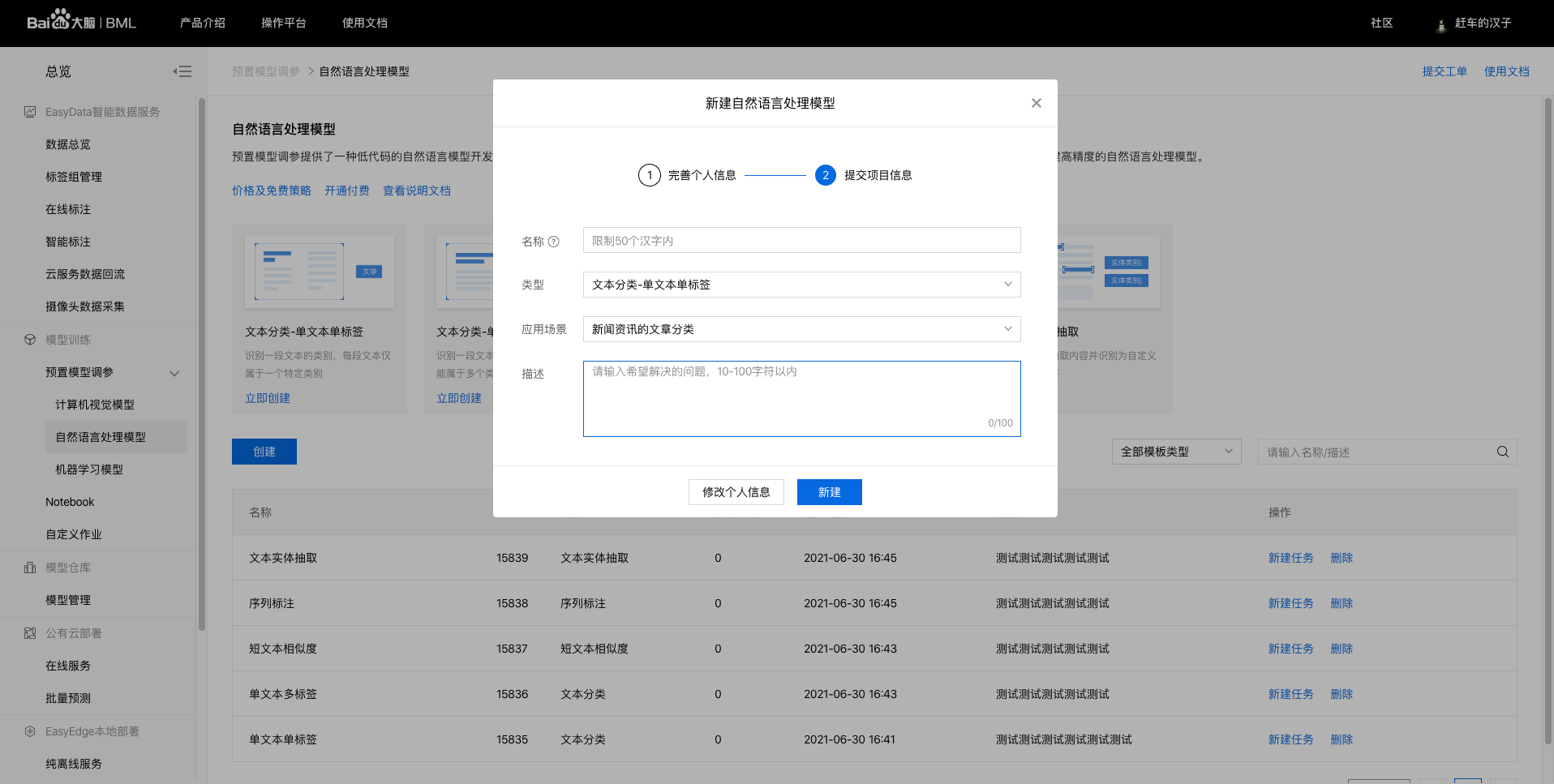
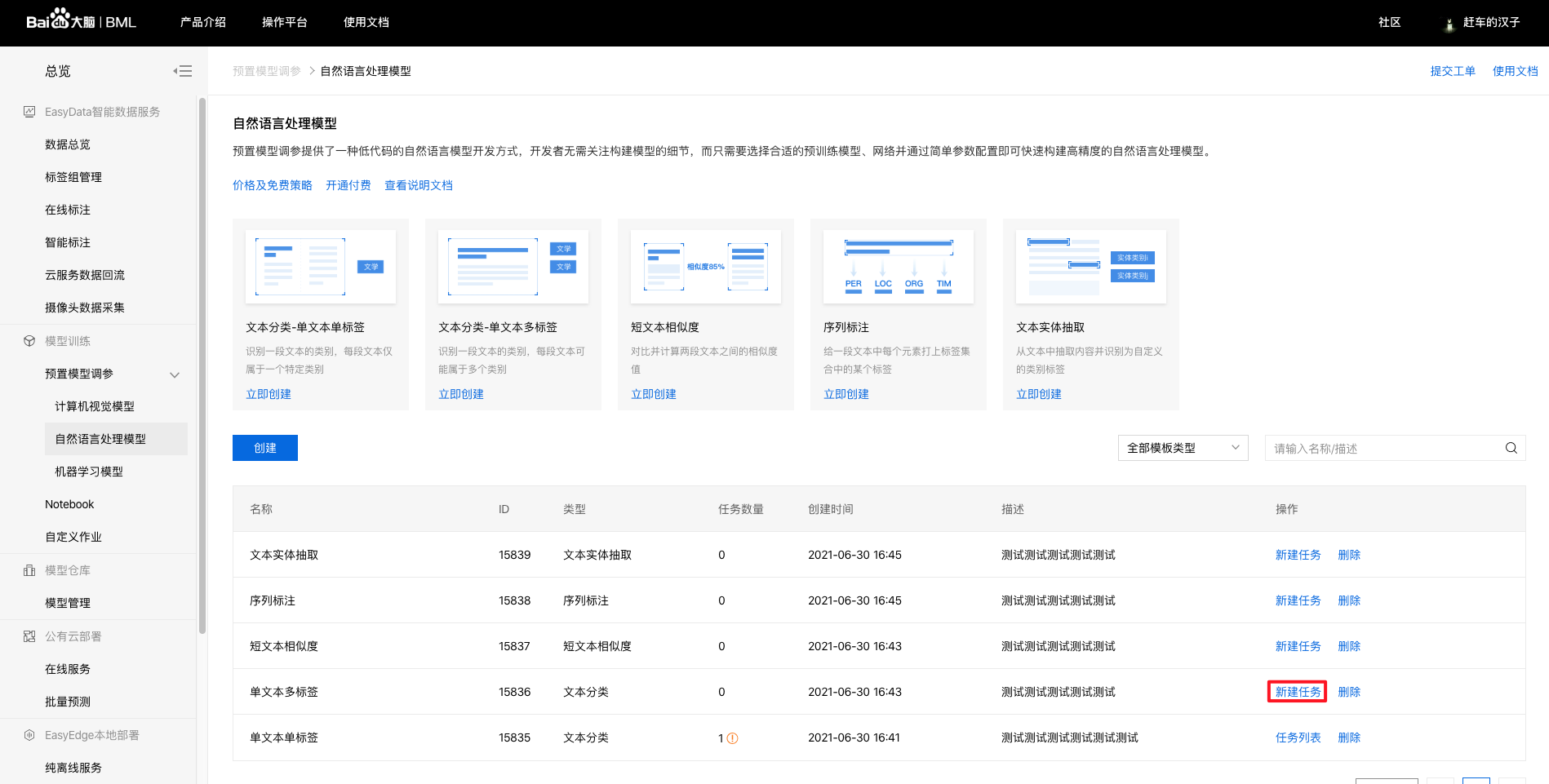
训练模型BML上提供了预置模型调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。 当前NLP方向仅支持使用者最多的预置模型调参,后续将陆续支持NoteBook建模、自定义作业开发模式。 本文将采用预置模型调参开发模式示意训练模型的基本步骤。 1、进入bml官方平台点击立即使用预置模型调参,点击【预置模型调参】-【自然语言处理模型】,进入操作台。
2、在模型列表下点击创建模型。
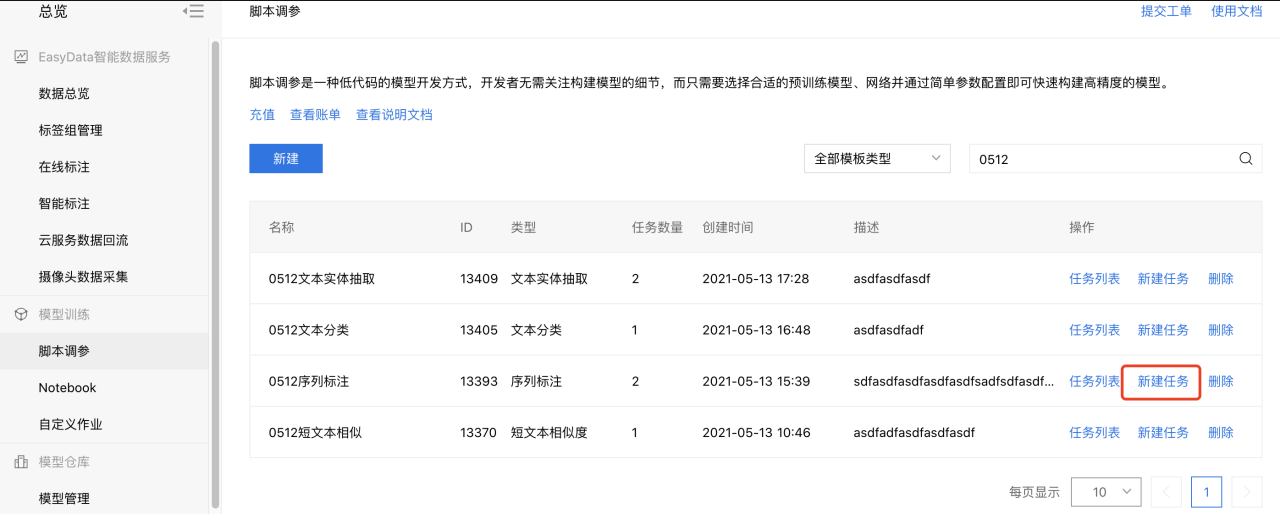
选择训练类型为序列标注,填写模型信息(名称、描述信息等)后,点击【创建】。 3、在模型列表下可看到所建模型信息,若平台已上传好数据集,则点击新建任务跳转至创建训练任务。
4、配置NLP分类训练任务。 之前已经建立好训练模型,现在开始配置NLP训练训练,点击【新建任务】。
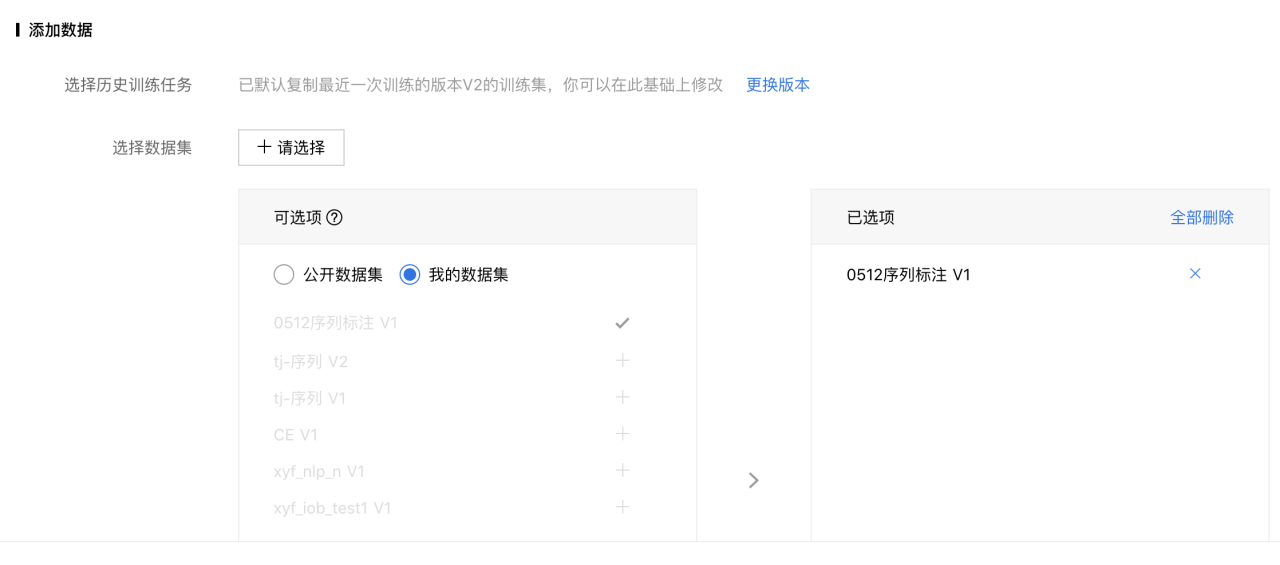
在新建任务面板中,可查看相关项目“基本信息”、“配置任务类型”、“添加数据”、“配置网络”等操作,在添加任务时添加刚才数据集确定添加。
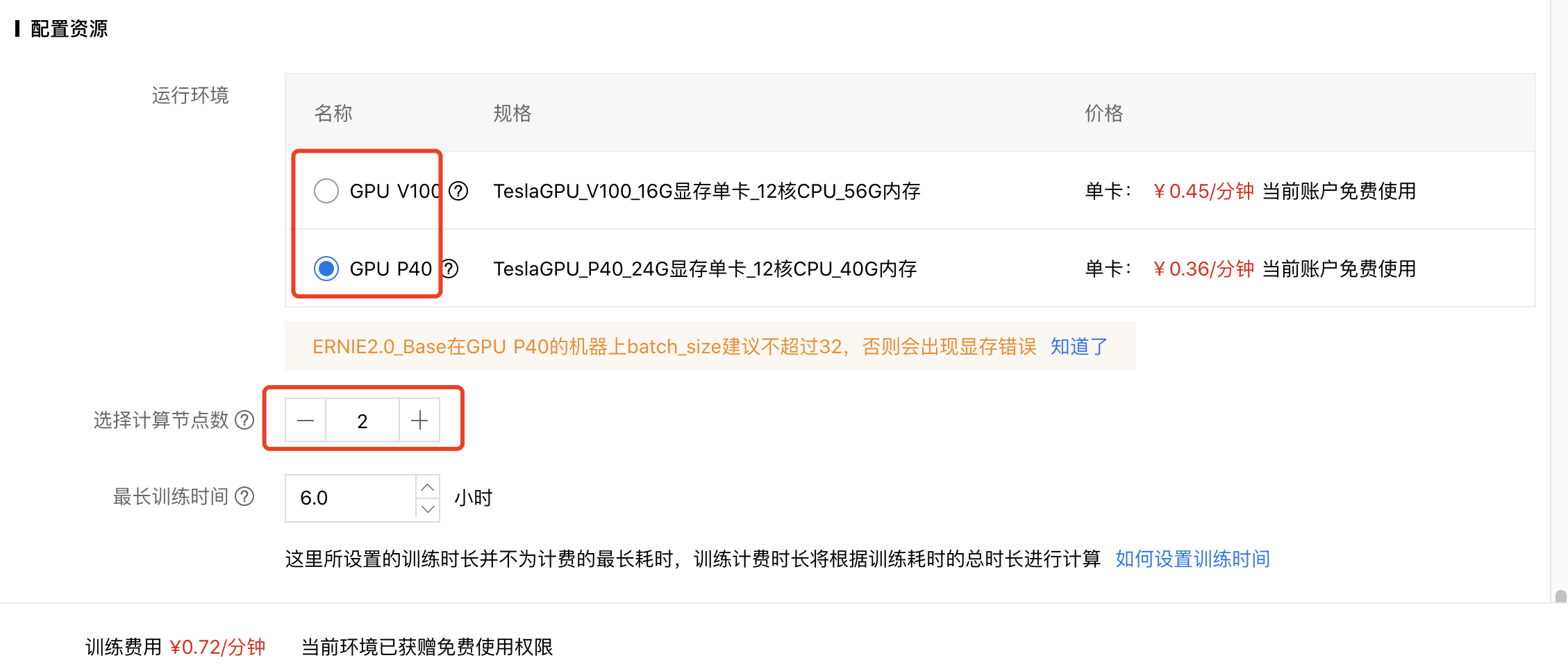
配置模型网络,选择显卡类型和是否启用分布式训练等。
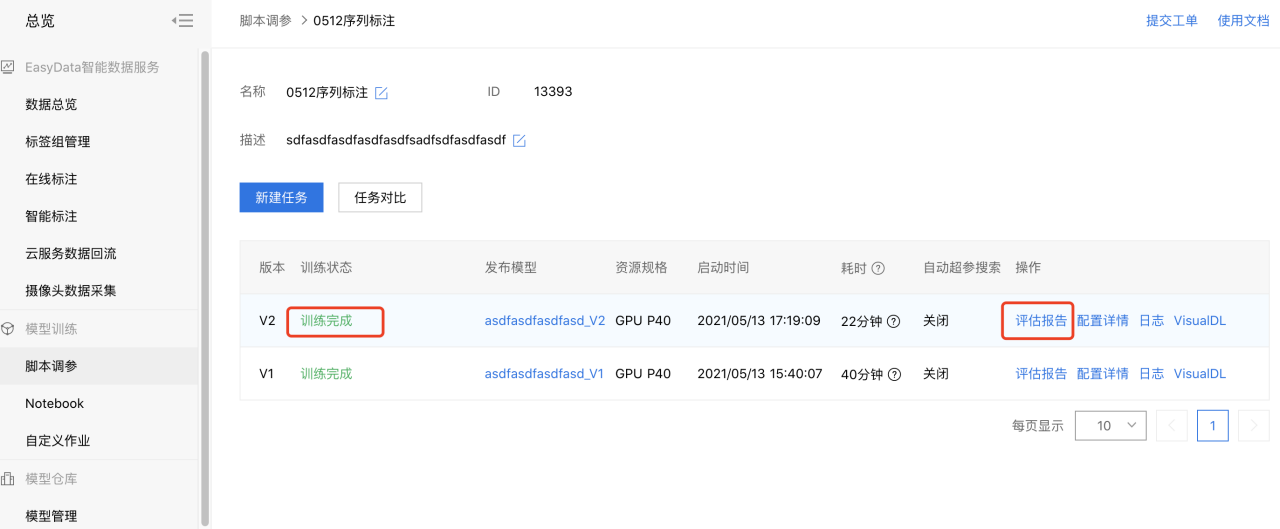
配置好后,可提交训练任务开始训练。 5、训练完成。 等待训练过程,完成后显示训练完成,用户可查看训练时长,训练结果的评估报告等信息。
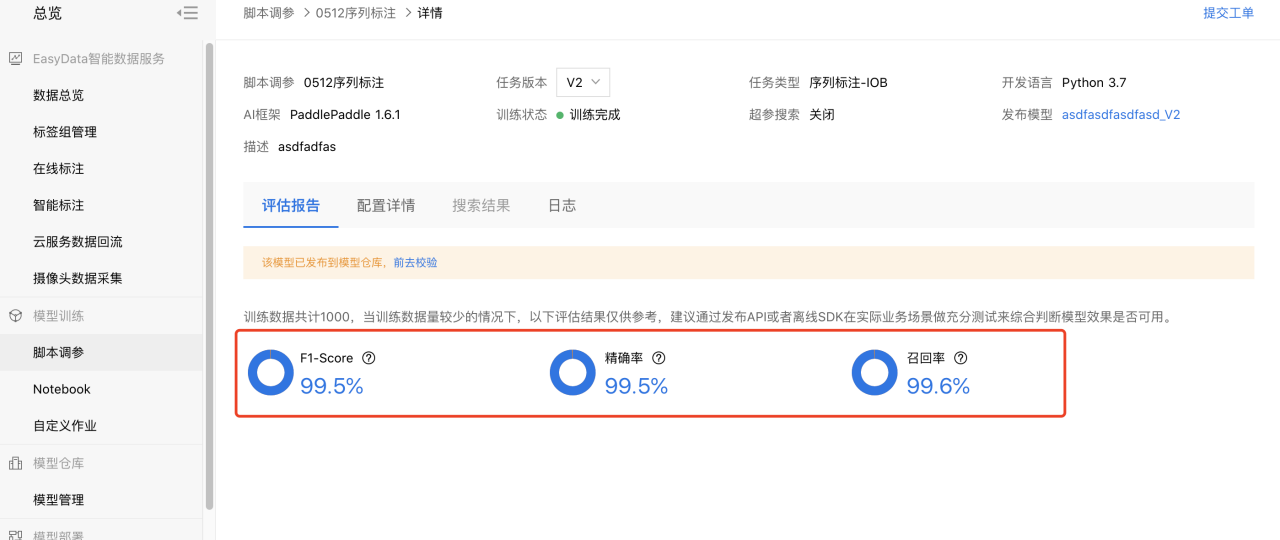
在评估报告中可查看本次训练过程的准确率,精确率等指标报告信息。
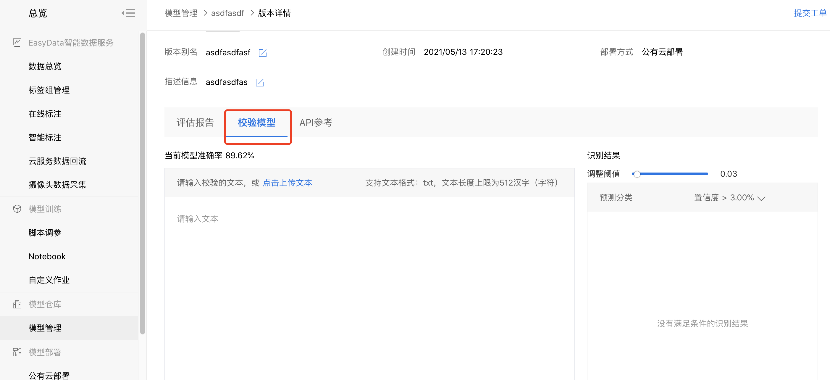
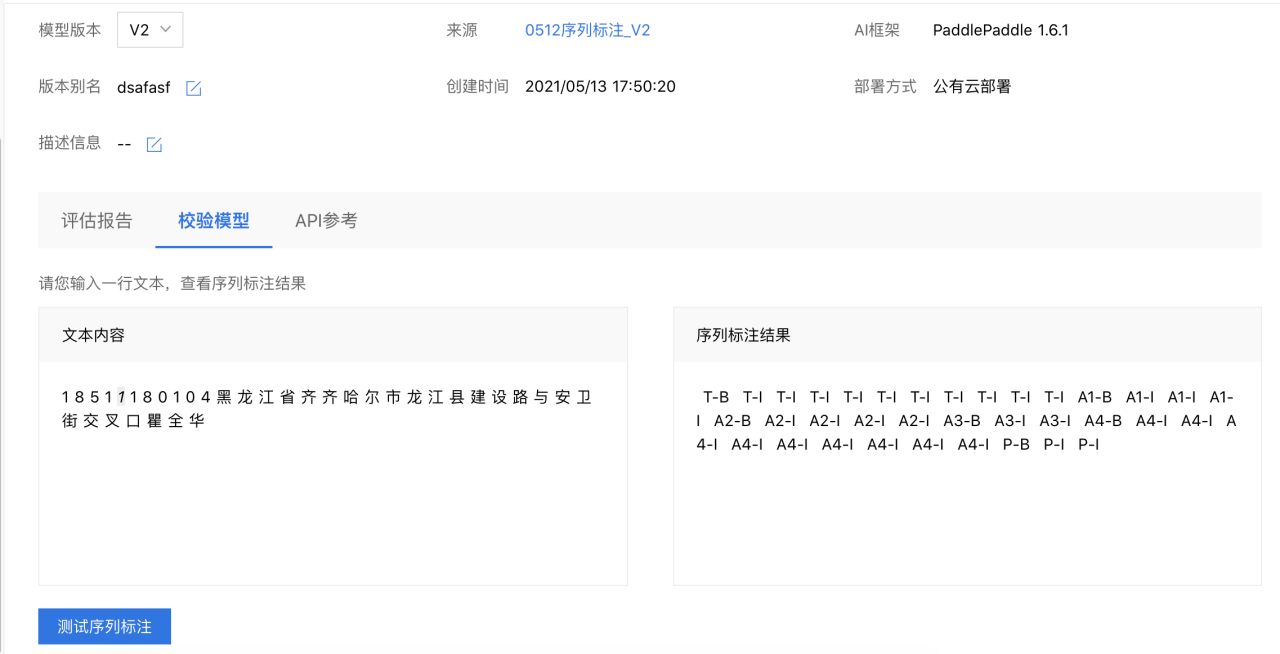
校验模型启动模型校验。
用训练好的模型对输入的文本进行相似度校验。
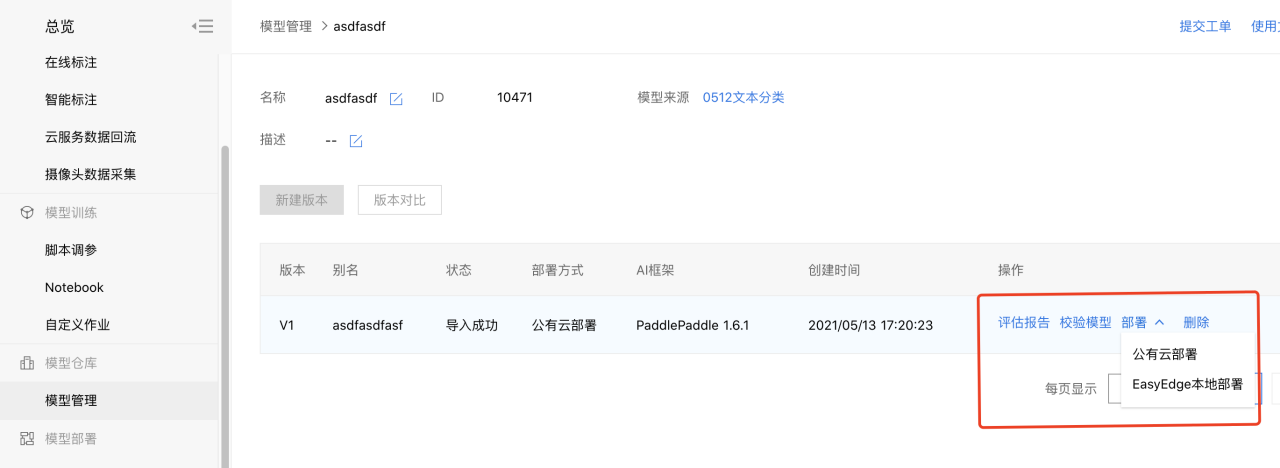
部署模型1、在模型管理中,可选择公有云和本地部署两种方式发布模型。
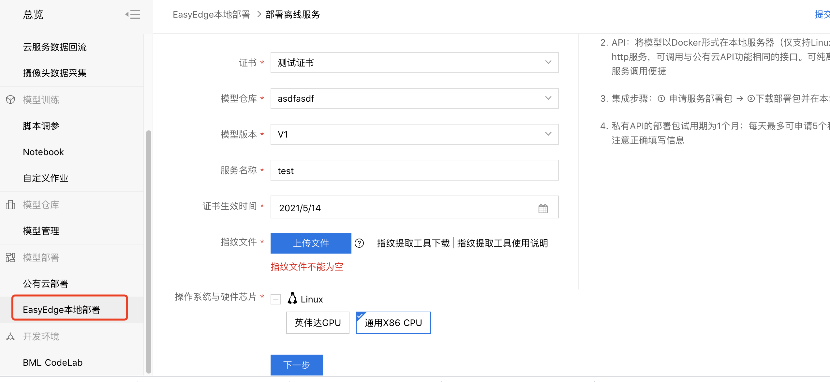
2、在模型部署中,用户按照自己情况填写信息完成模型部署。
|




 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477