

用BML评价短文本相似度:以新冠疫情相似句对判定为例
短文本相似度简介
亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅!
短文本相似度,即求解两个短文本之间的相似程度;它是文本匹配任务或文本蕴含任务的一种特殊形式,返回文本之间相似程度的具体数值。在工业界中,短文本相似度计算占有举足轻重的地位。
例如:在问答系统任务(问答机器人)中,我们往往会人为地配置一些常用并且描述清晰的问题及其对应的回答,我们将这些配置好的问题称之为“标准问”。当用户进行提问时,常常将用户的问题与所有配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
下文中将以新冠疫情相似句对判定任务为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的短文本相似度评价模型。
新冠疫情相似句对判定任务简介:
面对疫情抗击,疫情知识问答应用得到普遍推广。如何通过自然语言技术将问答进行相似分类仍然是一个有价值的问题。如识别患者相似问题,有利于理解患者真正诉求,帮助快速匹配准确答案,提升患者获得感;归纳医生相似答案,有助于分析答案规范性,保证疫情期间问诊规范性,避免误诊。
平台入口
BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据
准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限.
本文采用新冠疫情相似句对数据集进行示例,数据链接:新冠疫情相似句对判定。
下面来介绍数据规范与相关操作步骤。
数据规范
本地上传数据规范:
- 可支持单个txt文本文件上传、Excel上传,或将多个文本文件以压缩包的方式统一上传。
- 压缩包内的一个文本文件将作为一个样本上传,压缩包格式为.zip格式,压缩包内文件类型支持txt,编码仅支持UTF-8
- 上传过程中存在文本内容完全一样的样本,将会做去重处理。
- 文本文件类型为txt,单次上传限制100个文本文件。
- 单个文本大小限制在4M以内,文本文件大小限制长度最大4096个UTF-8字符。
- 文本文件内数据格式要求为"文本内容\n"(即每行一个未标注样本,使用回车换行),每一行表示一组数据,每组数据的字符数建议不超过512个,超出将被截断。
- 单个数据集大小限制为10万文本文件,超出后会被忽略。
创建及导入数据集
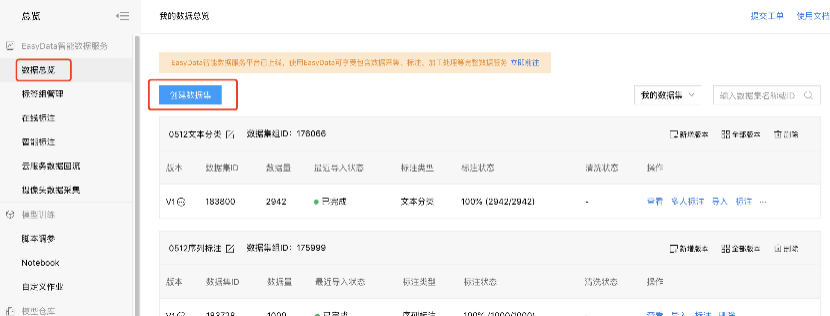
1、在官网界面点击【数据总览】,进入数据集操作界面。
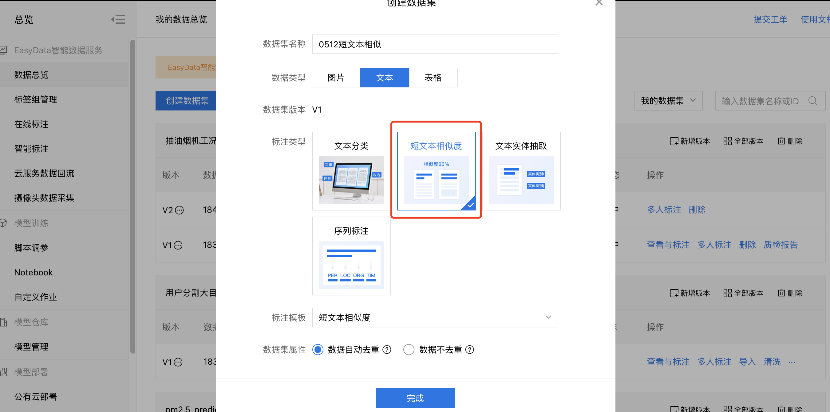
2、进入创建数据集界面,选择好数据类型和标注类型等信息,点击完成。
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID。
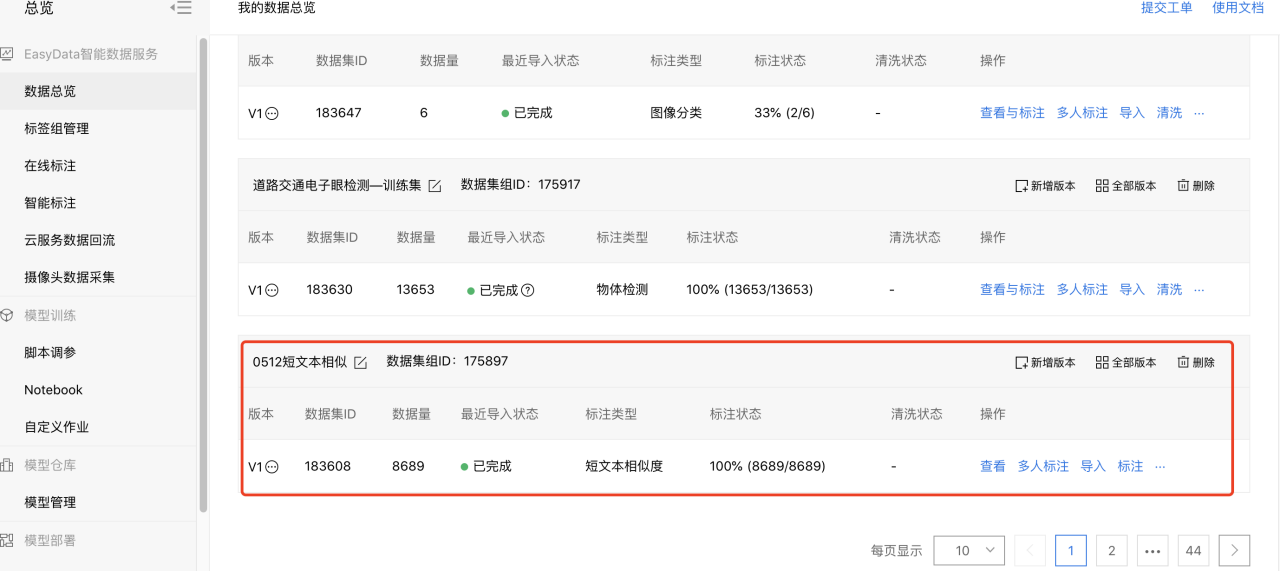
4、点击【导入】,将自己要训练的数据集导入,如这里选择本地导入Excel文件方式导入数据集,点击添加文件,然后确认并返回,完成数据集的导入。
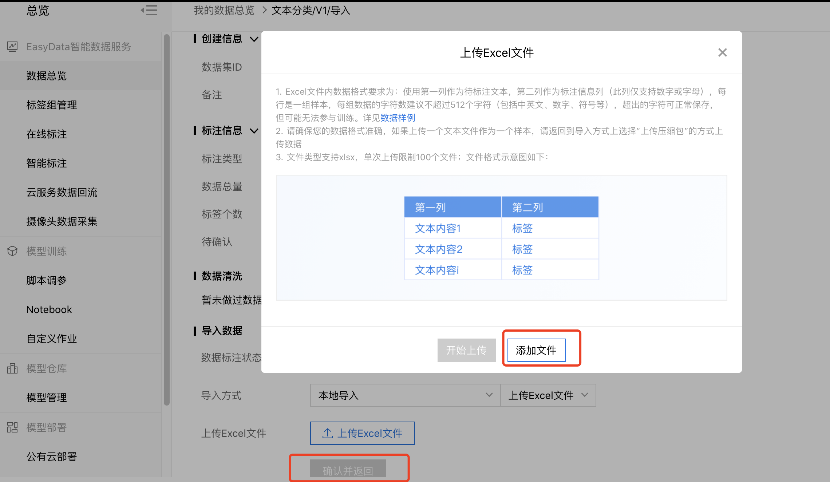
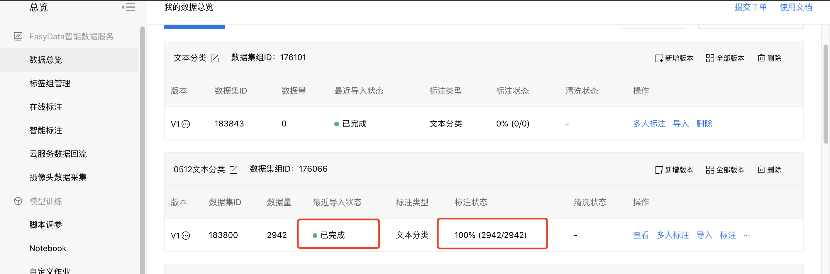
5、回到数据总览界面,可实时查看导入状态信息和标注状态,最终成功则显示已完成。
训练模型
BML上提供了预置模型调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。
当前NLP方向仅支持使用者最多的预置模型调参,后续将陆续支持NoteBook建模、自定义作业开发模式。
本文将采用预置模型调参开发模式示意训练模型的基本步骤。
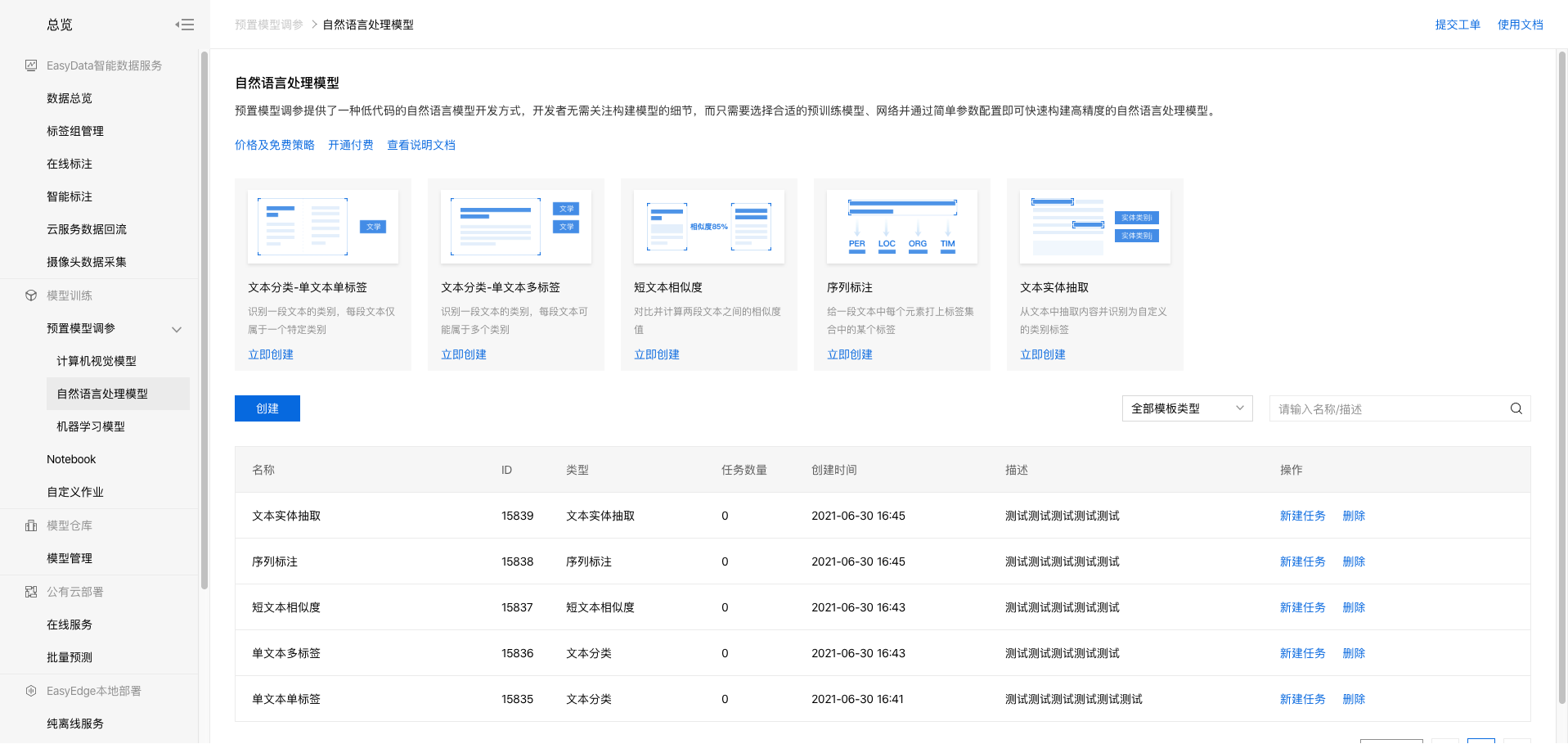
1、进入bml官方平台点击立即使用预置模型调参,点击【预置模型调参】-【自然语言处理模型】,进入操作台。
2、点击创建模型。
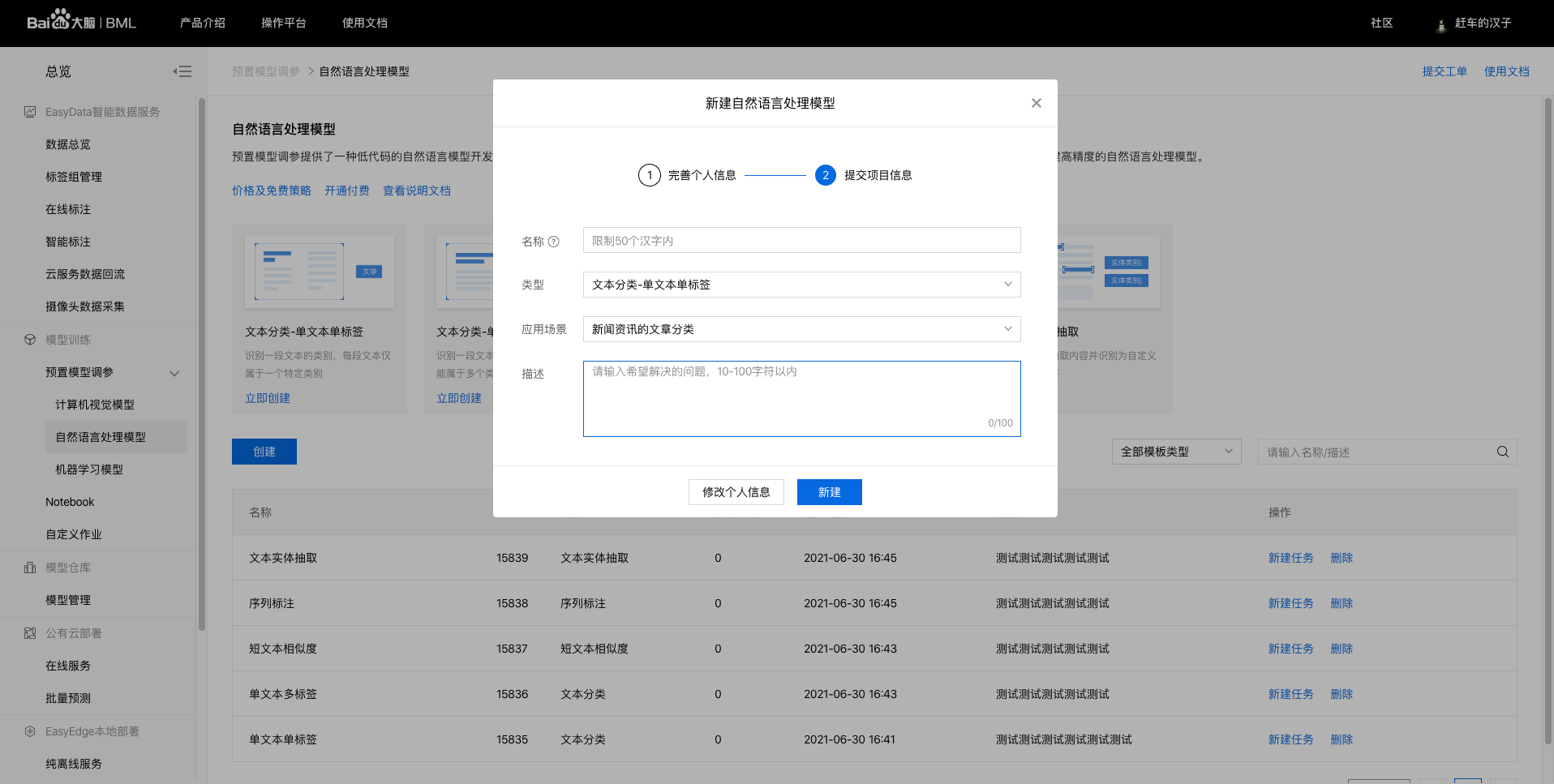
选择训练类型为短文本相似度,填写模型信息(名称、描述信息等)后,点击【创建】。
3、在模型列表下可看到所建模型信息,若平台已上传好数据集,则点击新建任务跳转至创建训练任务。
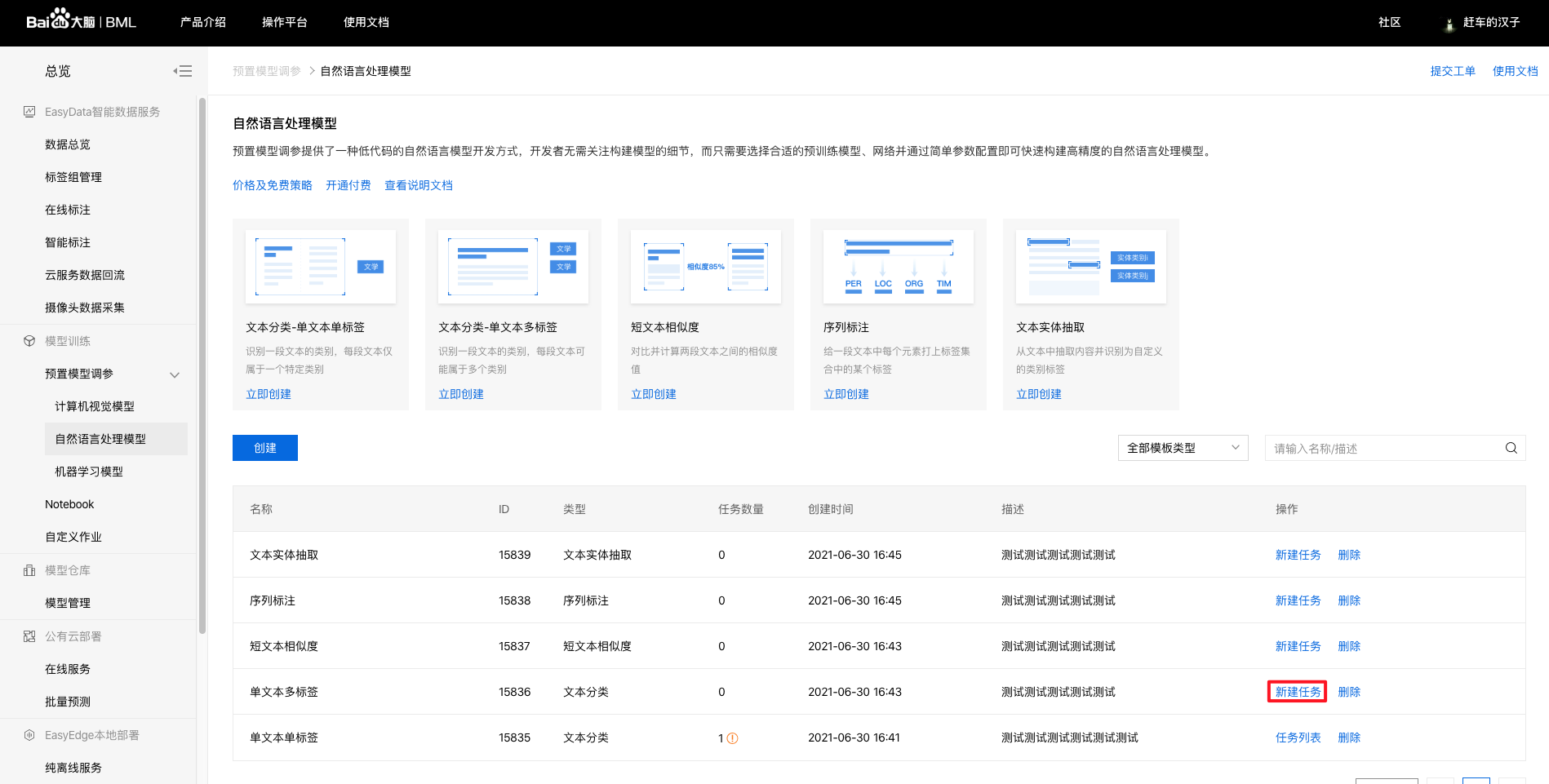
4、配置NLP分类训练任务。
之前已经建立好训练模型,现在开始配置NLP训练训练,点击【新建任务】。
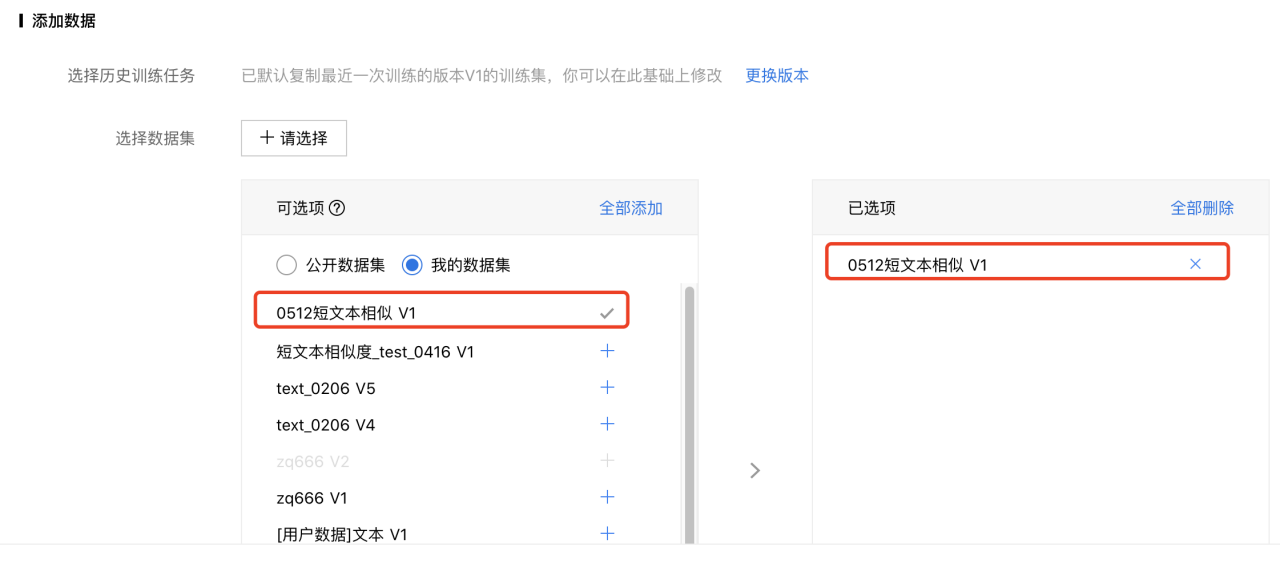
在新建任务面板中,可查看相关项目“基本信息”、“配置任务类型”、“添加数据”、“配置网络”等操作,在添加任务时添加刚才数据集确定添加。
配置模型网络,选择显卡类型和是否启用分布式训练等。
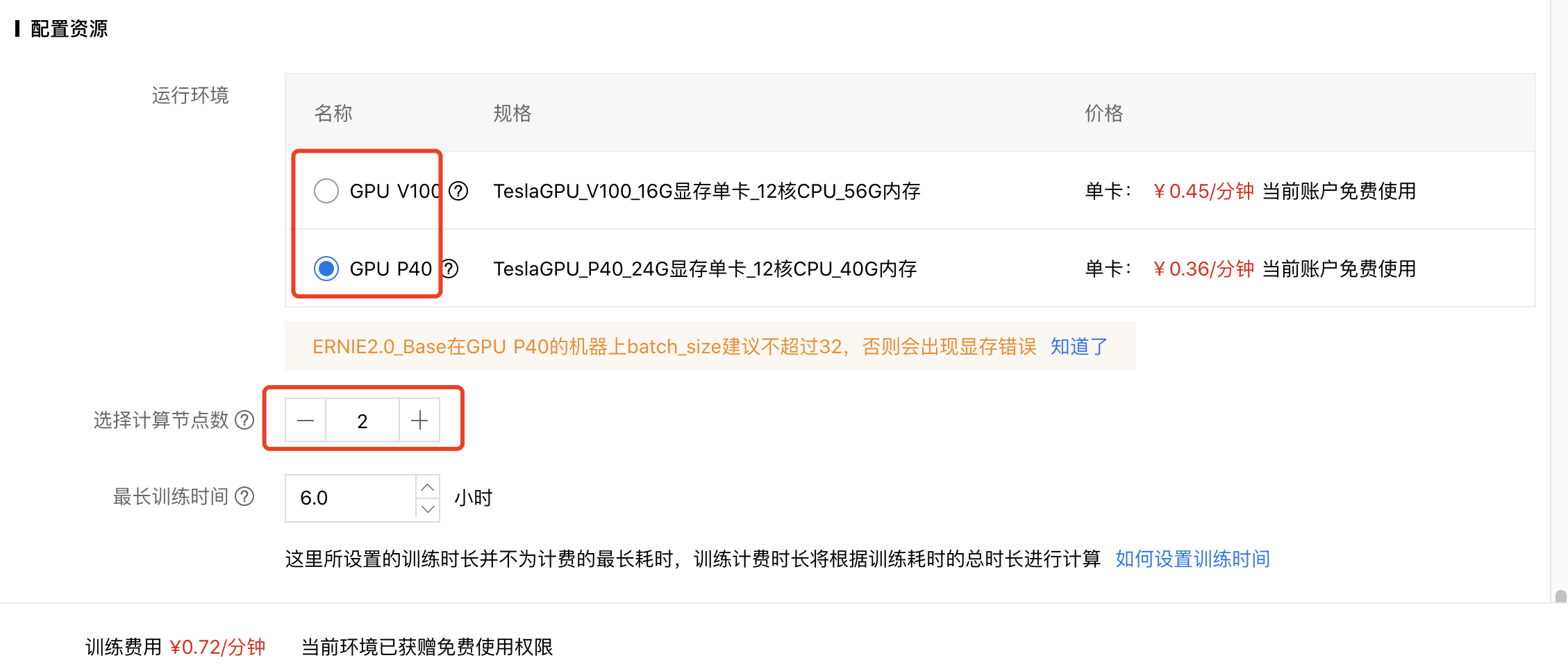
配置好后,可提交训练任务开始训练。
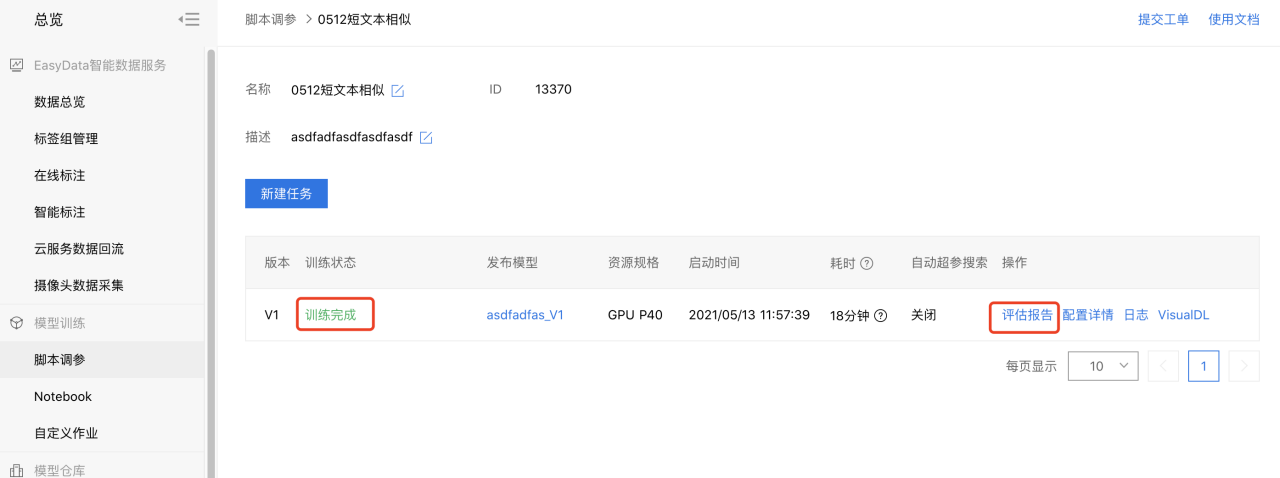
5、训练完成。
等待训练过程,完成后显示训练完成,用户可查看训练时长,训练结果的评估报告等信息。
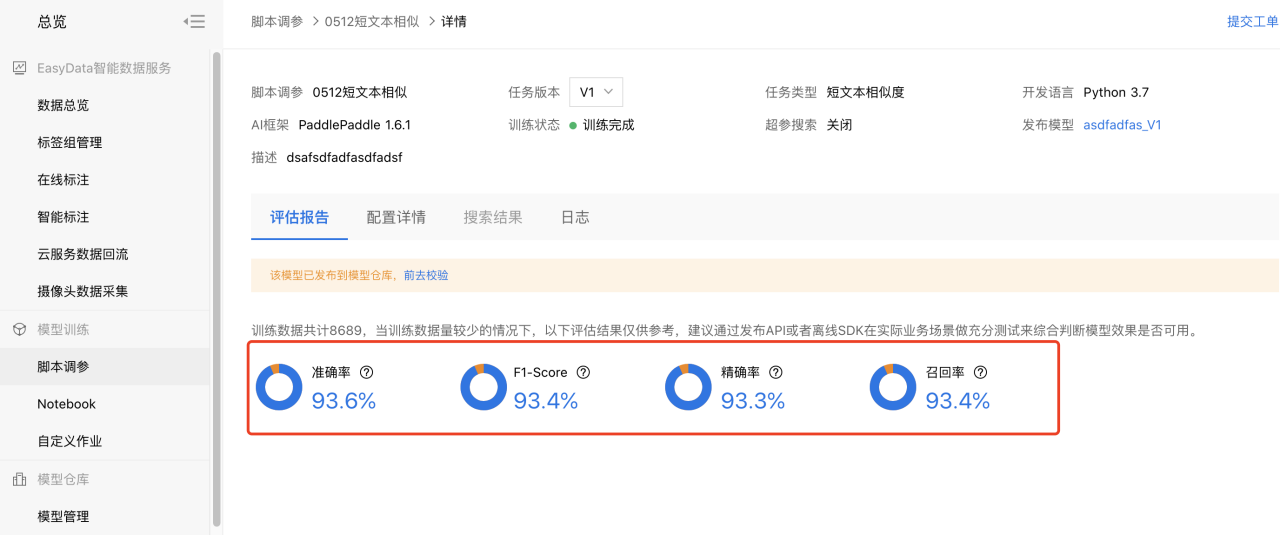
在评估报告中可查看本次训练过程的准确率,精确率等指标报告信息。
校验模型
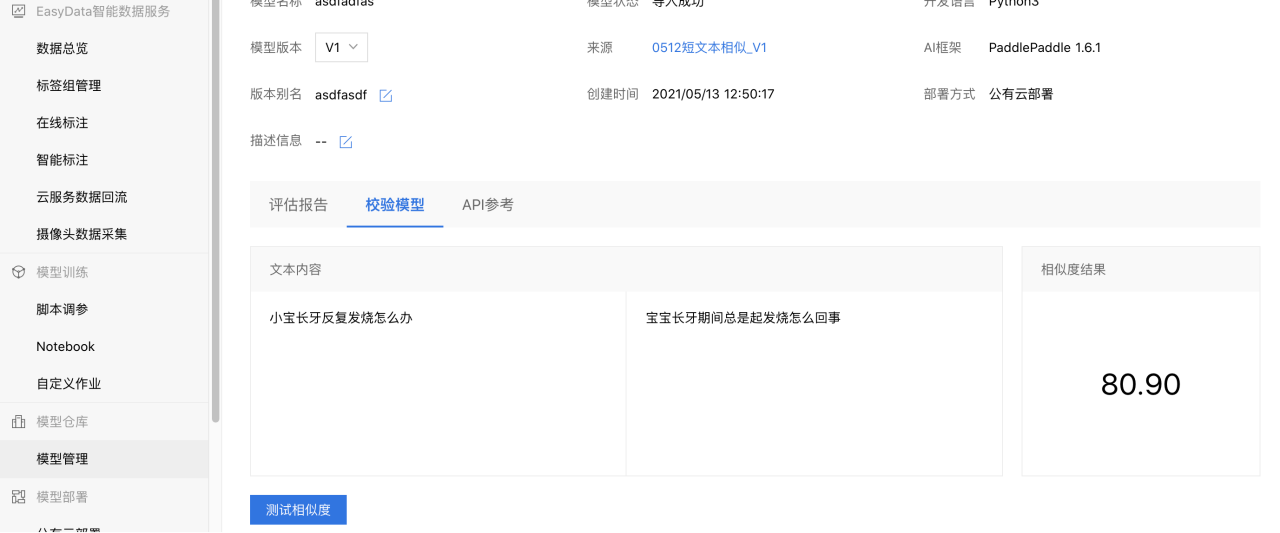
启动模型校验。
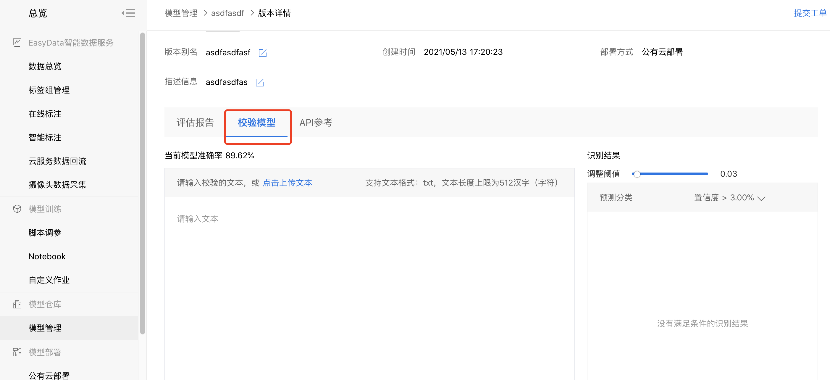
用训练好的模型对输入的文本进行相似度校验。
部署模型
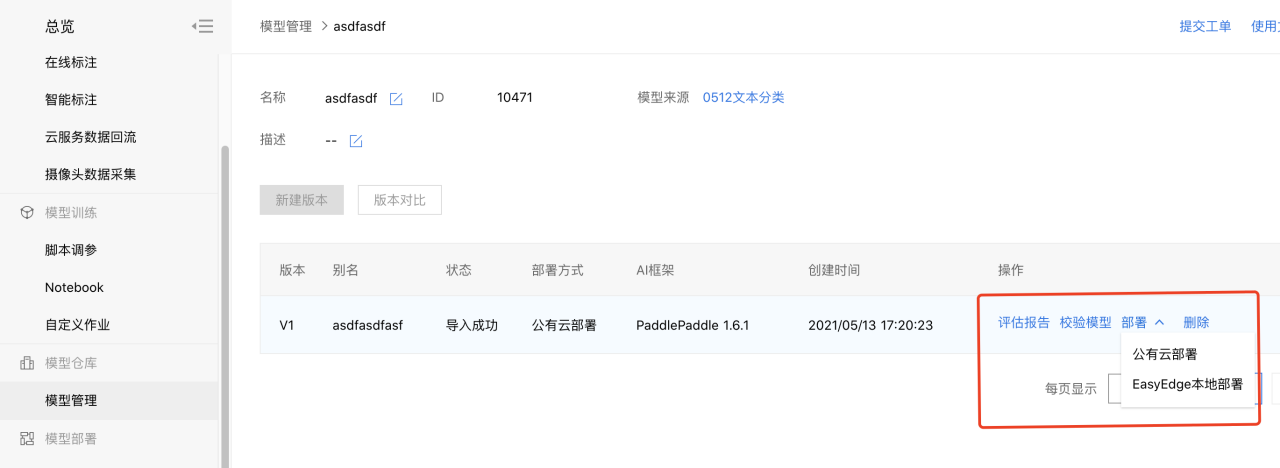
1、在模型管理中,可选择公有云和本地部署两种方式发布模型。
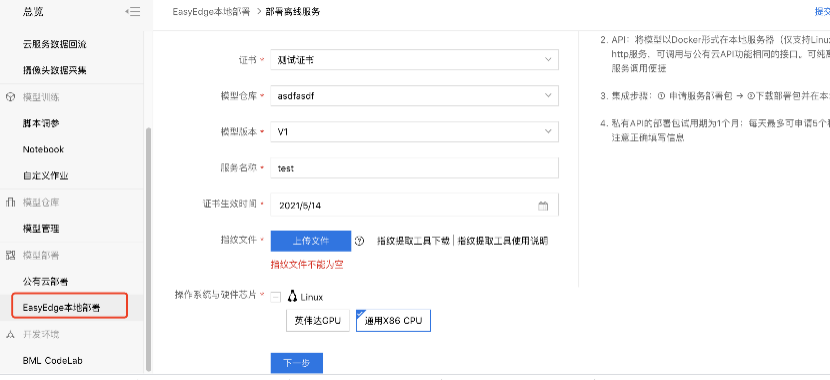
2、在模型部署中,用户按照自己情况填写信息完成模型部署。


 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477