

atop配置
atop简介
- atop是一款功能非常强大的Linux服务器监控工具。它能定期记录系统运行状态,并采集系统资源(如CPU、内存、磁盘、网络)的使用情况,同时还会监控进程的运行情况。通过将这些数据保存为日志文件的方式,我们可以在服务器出现问题时获取相应的atop日志文件进行详细分析。无论是查看系统资源的使用情况,还是追踪特定进程的运行状况,atop都能提供有用的信息。
- 使用atop工具,系统管理员可以及时发现服务器的性能瓶颈、异常情况以及资源利用率等问题,从而更好地管理和优化服务器的运行。
CentOS 8系列操作系统atop配置方法
通过远程登录或本地登录的方式登录弹性云主机。
下载atop安装包。命令如下。
# wget https://www.atoptool.nl/download/atop-2.6.0-1.el8.x86_64.rpm
执行以下命令安装atop。
# rpm -ivh atop-2.6.0-1.el8.x86_64.rpm
编辑配置文件,修改采样周期,atop配置文件为/etc/default/atop。
# vi /etc/default/atop
可以根据自己的实际需求修改如下配置参数,修改后保存并退出。
LOGINTERVAL=15 LOGGENERATIONS=7 LOGPATH=/var/log/atop/
参数说明:
LOGINTERVAL:监控周期,单位为秒,默认600s采集一次数据,建议修改为15s。
LOGGENERATIONS:日志保留时间,单位为天,默认保留时间为28天,建议修改为7天,避免大量占用磁盘空间。
LOGPATH:日志保存路径。默认路径为/var/log/atop/。
重启atop服务。
# systemctl restart atop
可以设置atop服务自启动(根据实际情况设置)。
# systemctl enable atop
检查是否启动成功,active(running)表示运行正常。
# systemctl status atop
CTyunOS 、CentOS 7、EulerOS、Anolis、KylinOS系列操作系统atop配置方法
通过远程登录或本地登录的方式登录弹性云主机。
下载atop安装包。
# wget https://www.atoptool.nl/download/atop-2.6.0-1.el7.x86_64.rpm
执行以下命令安装atop。
# rpm -ivh atop-2.6.0-1.el7.x86_64.rpm --nodeps
编辑配置文件,修改采样周期,atop配置文件为/etc/default/atop。
# vi /etc/default/atop
可以根据自己的实际需求修改如下配置参数,修改后保存并退出。
LOGINTERVAL=15 LOGGENERATIONS=7 LOGPATH=/var/log/atop/
参数说明:
LOGINTERVAL:监控周期,单位为秒,默认600s采集一次数据,建议修改为15s。
LOGGENERATIONS:日志保留时间,单位为天,默认保留时间为28天,建议修改为7天,避免大量占用磁盘空间。
LOGPATH:日志保存路径。默认路径为/var/log/atop/。
重启atop服务。
# systemctl restart atop
可以设置atop服务自启动(根据实际情况设置)。
# systemctl enable atop
检查是否启动成功,active(running)表示运行正常。
# systemctl status atop
使用源码方式安装(适用于Fedora、Debian、Ubuntu等系列操作系统)
下载atop源码。
# wget https://www.atoptool.nl/download/atop-2.6.0.tar.gz
执行以下命令解压源码atop。
# tar -zxvf atop-2.6.0.tar.gz
执行以下命令查看systemctl版本。
# systemctl –version
如果版本大于等于220,直接进行下一步。
否则需要修改atop的Makefile文件,删除--now参数。
# vi atop-2.6.0/Makefile
删除systemctl命令后的--now参数。
安装编译atop依赖软件包。
Fedora系列操作系统执行以下命令安装:
# yum install make gcc zlib-devel ncurses-devel -y
Debian9、Debian10、Ubuntu系列操作系统执行以下命令安装:
# apt install make gcc zlib1g-dev libncurses5-dev libncursesw5-dev –y
执行以下命令编译并安装atop。
# cd atop-2.6.0 # make systemdinstall
编辑配置文件,修改采样周期,atop配置文件为/etc/default/atop。
# vi /etc/default/atop
可以根据自己的实际需求修改如下配置参数,修改后保存并退出。
LOGINTERVAL=15 LOGGENERATIONS=7 LOGPATH=/var/log/atop/
重启atop服务。
# systemctl restart atop
可以设置atop服务自启动(根据实际情况设置)。
# systemctl enable atop
检查是否启动成功,active(running)表示运行正常。
# systemctl status atop
atop结果分析
atop启动后,会将采集到的记录默认存放在/var/log/atop目录中,通过执行如下命令,查看日志文件。
atop -r /var/log/atop/atop_20230821
备注:可通过ls /var/log/atop/查看所有生成的日志文件,atop_20230821为其中的一个日志文件。
atop常用指令如下所示:
c:按照进程CPU使用率进行降序筛选。
m:按照进程内存使用率进行降序筛选。
d:按照进程磁盘使用率进行降序筛选。
a:按照进程资源综合使用率进行降序筛选。
n:按照进程网络使用率进行降序筛选,需要额外安装内核模块才支持,默认不支持。
t:跳转到下一个监控采集点。
T:跳转到上一个监控采集点。
b:指定时间点。
系统资源监控字段说明。
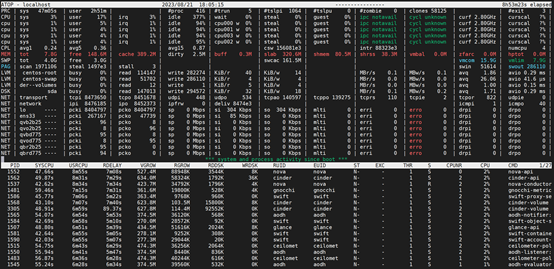
ATOP行:主机名、采样日期和时间点。
PRC行:进程整体运行情况。
sys及user:进程在内核态及用户态所占CPU的时间比例。
#proc:进程总数。
#zombie:僵死进程的数量。
#exit:atop 采样周期期间退出的进程数量。
CPU行:CPU 整体(即多核CPU作为一个整体CPU资源)的使用情况。【各字段数值相加结果为N00%,N为CPU的核数】
sys及user:CPU被用于处理进程时,进程在内核态、用户态所占 CPU 的时间比例。
irq:CPU被用于处理中断的时间比例。
idle:CPU处在完全空闲状态的时间比例。
wait:CPU处在“进程等待磁盘IO导致CPU空闲”状态的时间比例。
CPL行:CPU负载情况。
avg1、avg5 和 avg15:过去1分钟、5分钟和15分钟内运行队列中的平均进程数量。
csw:指示上下文交换次数。
intr:指示中断发生次数。
MEM行:内存的使用情况。
tot:物理内存总量。
cache:用于页缓存的内存大小。
buff:用于文件缓存的内存大小。
slab:系统内核占用的内存大小。
SWP行:交换空间的使用情况。
tot:交换区总量。
free:空闲交换空间大小。
PAG行:虚拟内存分页情况
swin及swout:换入和换出内存页数。
DSK行:磁盘使用情况,每一个磁盘设备对应一列。如果有 sdb 设备,那么增加一行 DSK 信息。
sda:磁盘设备标识。
busy:磁盘忙时比例。
read及write:读、写请求数量。
NET行:多列 NET 展示了网络状况,包括传输层(TCP 和 UDP)、IP层以及各活动的网口信息。
XXXi:各层或活动网口收包数目。
XXXo:各层或活动网口发包数目。
kdump配置
kdump简介
- kdump是Linux系统中一种用于保存系统崩溃时的内存转储(crash dump),以便进行故障诊断和调试的工具。
- 在Linux系统中,如果遇到严重的内核崩溃或死锁等问题,通常会导致系统无法继续正常运行。为了解决这种情况,kdump允许在系统崩溃时将当前内核的内存转储保存到硬盘上。kdump通过一些特定的配置和设置,可以在系统崩溃时触发一个独立的内核(用作专用的crash内核),该内核能够将系统的内存转储保存到预定义的目录中。这个转储文件可以记录包括内核代码、进程状态、内核堆栈跟踪等信息,使开发人员和系统管理员能够在崩溃发生时进行故障分析和调试。
- kdump是一种非常有用的工具,它可以帮助我们更有效地诊断系统崩溃问题,定位和解决导致系统异常的根本原因。
kdump使用须知
- 系统设置
要使用kdump功能,您的系统必须满足一些硬件和配置要求:- 必须有足够的磁盘空间来存储转储文件。
- 必须有足够的内存来容纳专用的crash内核。
- CPU必须支持物理地址扩展(PAE)或64位寻址模式。
- 内核配置:您的Linux内核必须正确配置以启用kdump功能。通常,许多发行版都已经为您设置了合适的内核配置。
- 专用的crash内核:为了执行转储过程,kdump需要一个独立的crash内核。这个crash内核是一个精简的内核,只包含用于内存转储和调试的必要组件。
- 存储位置:您需要选择一个足够大且可靠的存储位置来保存转储文件。这可能是本地磁盘、NFS共享目录或iSCSI设备等。
- 网络配置(可选):如果您选择将转储文件发送到远程服务器进行分析,则需要配置网络连接和远程服务器的接收端。
kdump配置方法
以EulerOS以及CentOS 7/8系列Linux产品为例:
查看是否已安装kexec-tools。
# rpm -qa | grep kexec-tools
如果没有安装,执行下面命令安装kexec-tools。
# yum install -y kexec-tools
设置kdump开机启动。
# systemctl enable kdump
设置crashkernel参数,设置这个参数的目的是预留内存给捕获内核(capture kernel)。
首先查看该参数是否已经设置。# grep crashkernel /proc/cmdline
如果有显示,则表示已经设置,如果没有显示,则需要重新设置。
编辑/etc/default/grub文件,此文件通常包含如下内容:
GRUB_TIMEOUT=5 GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=rhel00/root rd.lvm.lv=rhel00/swap rhgb quiet" GRUB_DISABLE_RECOVERY="true"
在GRUB_CMDLINE_LINUX一行添加crashkernel=auto。
更新grub,执行更新grub命令,使配置生效。命令如下。
# grub2-mkconfig -o /boot/grub2/grub.cfg
打开/etc/kdump.conf文件中找到“path”参数,添加以下内容。
path /var/crash
默认是保存在/var/crash目录下,如果要保存到其他目录,则改成对应的目录,例如保存在/home/kdump下,则改成:
path /home/kdump ## 请确保指定的路径有足够的空间保存vmcore,建议剩余空间不小于物理内存(RAM)的大小,也可以保存在SAN,NFS等共享设备上。
设置转存vmcore级别,查看/etc/kdump.conf文件,是否存在以下设置,如果存在则无需添加。
core_collector makedumpfile -d 31 -c
-c:表示压缩vmcore文件,
-d:表示过滤掉部分无效的内存数据,可以根据需要调整,一般31即可,31是由如下的值与计算而成。
zero pages= 1
cache pages = 2
cache private = 4
user pages= 8
free pages= 16
设置内核参数(可选)。
为了控制在哪些场景下触发kdump,内核提供了一些参数,建议设置以下参数:
kernel.hardlockup_panic=1
kernel.panic=5
kernel.panic_on_oops=1
kernel.softlockup_panic=1
kernel.unknown_nmi_panic=1
kernel.nmi_watchdog=1
将以上配置参数写入/etc/sysctl.conf文件并保存。另外,可以选择添加如下几个参数到/etc/sysctl.conf文件中。
kernel.panic_on_io_nmi=1
kernel.panic_on_warn=1
进入天翼云控制台-云主机详情页,对当前云主机进行重启,使以上配置生效
Kdump配置生效验证
执行以下命令,确认回显信息中crashkernel=auto。
# cat /proc/cmdline |grep crashkernel
执行以下命令,并确认回显信息中的配置信息正确。
# grep core_collector /etc/kdump.conf |grep -v ^"#" core_collector makedumpfile -l --message-level 1 -d 31
执行以下命令,并确认回显信息中的配置信息正确。
# grep path /etc/kdump.conf |grep -v ^"#" path /var/crash
执行以下命令,并确认回显信息中的Active的状态为active (exited)。
# systemctl status kdump
执行测试命令。
# echo c > /proc/sysrq-trigger
这会触发kdump,重新启动,并将生成的vmcore文件保存的path参数指定的位置。
检查vmcore是否生成。
到所在环境path参数所指定的路径查看是否有vmcore文件生成,例如/var/crash/目录。# ll /var/crash/
可以看到生成了一个文件夹,里面有vmcore文件。


 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477