| 阿里云服务器ECS使用教程-搭建Hadoop环境 |
|
阿里云服务器ECS使用教程-搭建Hadoop环境 本教程介绍如何在Linux操作系统的ECS实例上快速搭建Hadoop伪分布式环境。 前提条件
背景信息Hadoop是一款由Apache基金会用Java语言开发的分布式开源软件框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的能力进行高速运算和存储。Hadoop的核心部件是HDFS(Hadoop Distributed File System)和MapReduce:
更多信息,请参见Hadoop官网。 操作步骤在ECS实例上快速搭建Hadoop伪分布式环境的操作步骤如下:
步骤一:安装JDK
步骤二:安装Hadoop
步骤三:配置Hadoop
步骤四:配置SSH免密登录
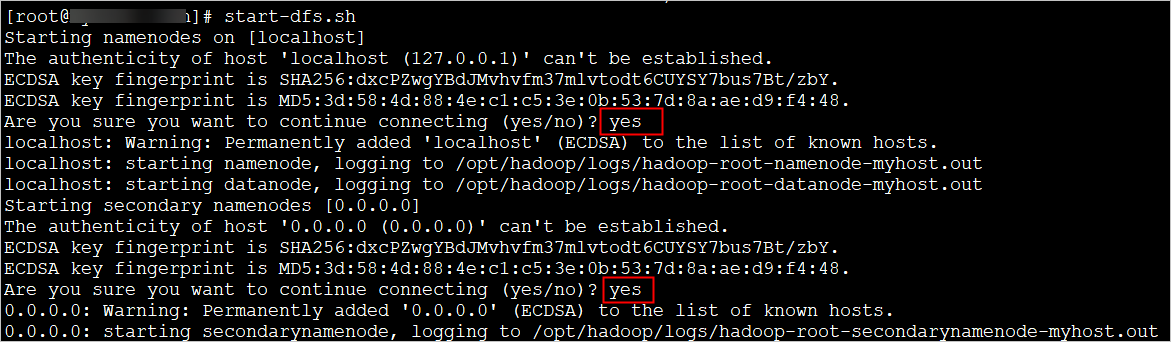
步骤五:启动Hadoop
|






 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477