| 百度文心千帆大模型平台使用指南-怎么创建强化学习训练任务? | ||||||||
|
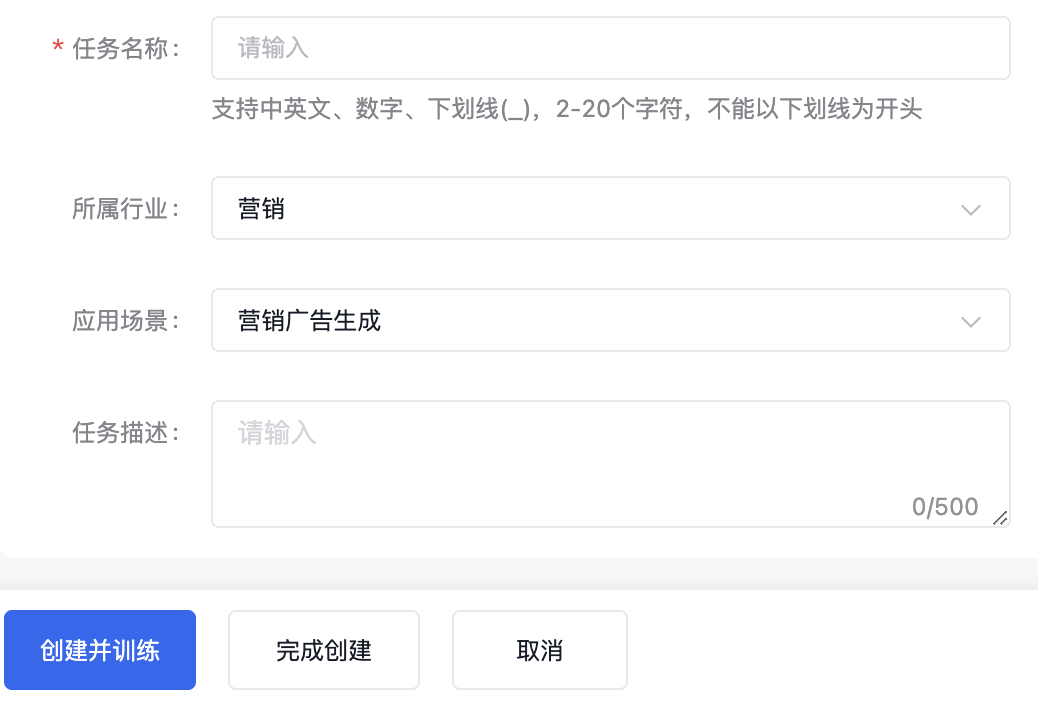
百度文心千帆大模型平台使用指南-怎么创建强化学习训练任务? 强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能代理(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。 强化学习主要是训练对象每一步如何进行决策,采用什么样的行动可以完成特定的目的或者使收益最大化。 登录到文心千帆大模型操作台,在左侧功能列RLHF训练中选择强化学习训练,进入强化学习训练主任务界面。 创建任务您需要在强化学习训练任务界面,选择“创建训练任务”按钮。 填写好任务名称后,在范围内选择所属行业和应用场景,再进行500字内的业务描述即可。
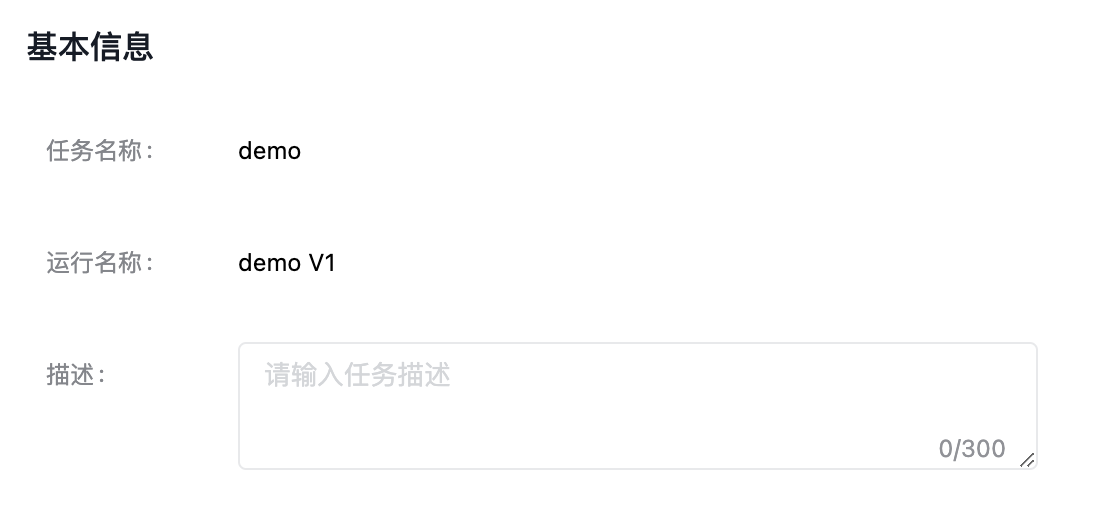
创建并训练创建并训练直接开启训练模型的运行配置界面;“完成创建”仅创建任务不创建训练模型的运行。 新建运行您可以在创建任务时选择“创建并训练”,或者在强化学习训练任务列表中,选择指定任务的“新建运行”按钮。
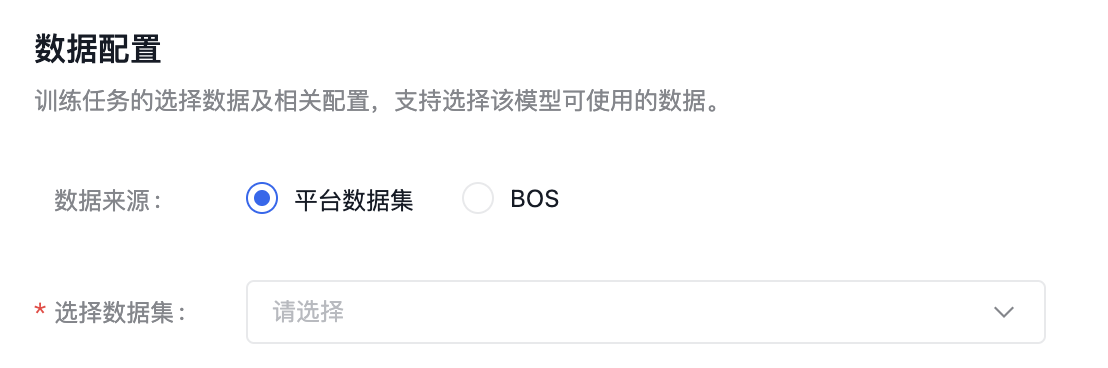
数据配置选择训练任务的数据及相关配置,强化学习训练任务匹配query问题集。 建议数据集总条数在1000条以上,训练模型更加精准。
数据集来源可以为千帆平台已发布的数据集版本,也可以为已有数据集的BOS地址,详细内容可查看数据集部分内容。 需注意:当选择BOS目录导入数据集时,数据放在jsonl文件夹下。您需要选择jsonl的父目录:
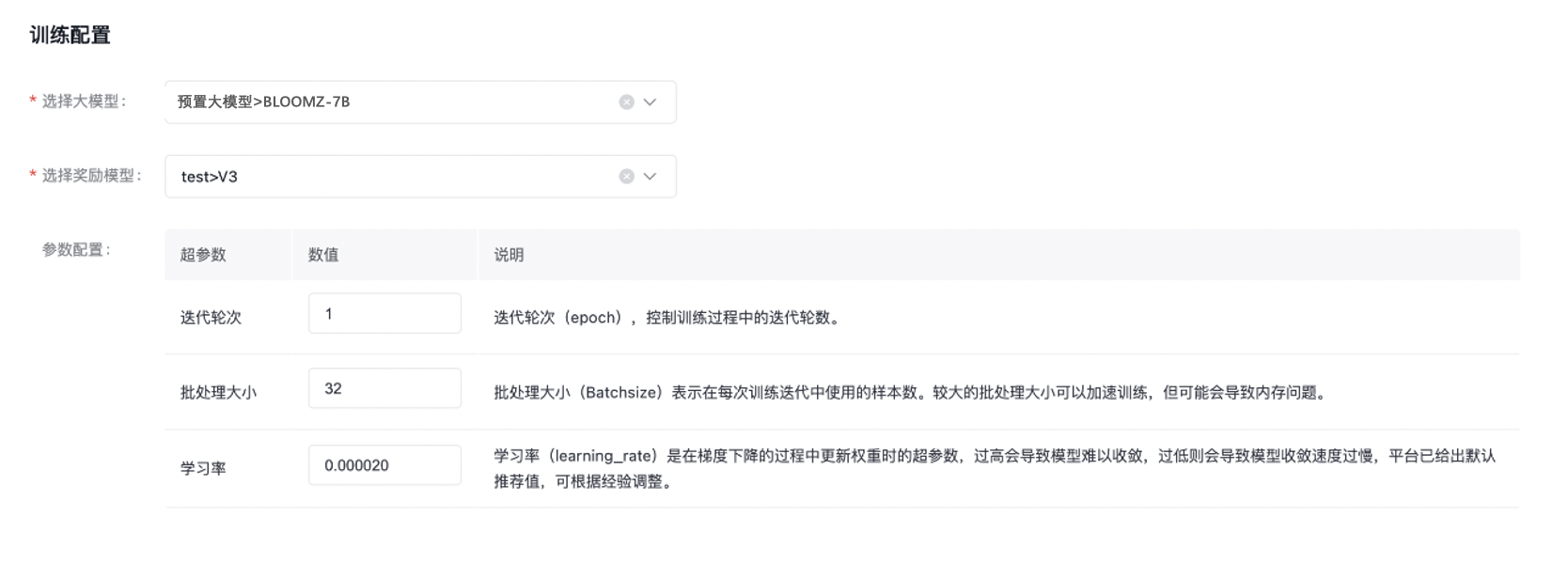
百度BOS服务开通申请。 训练配置
以上所有操作完成后,点击“确定”,则发起模型训练的任务。 |




 工信部ICP备案号:湘ICP备2022009064号-1
工信部ICP备案号:湘ICP备2022009064号-1 湘公网安备 43019002001723号
湘公网安备 43019002001723号 统一社会信用代码:91430100MA7AWBEL41
统一社会信用代码:91430100MA7AWBEL41 《增值电信业务经营许可证》B1-20160477
《增值电信业务经营许可证》B1-20160477