👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
本文主要介绍如何在Docker环境中进行端到端单机/多机GPT训练来判断GPU性能是否达标。
背景信息
在处理GPU性能问题时,如果执行了HostDiagnose、Easy_NCCL等操作后仍无法定位到异常或者需要模拟真实业务场景时,您可以通过端到端单机/多机GPT训练,模拟用户真实业务来判断GPU性能是否达标,从而节省依赖安装、编译、配置端口、免密等繁琐步骤。
说明
除HostDiagnose、Easy_NCCL等实例内部的操作之外,您也可以在实例诊断控制台一键诊断GPU设备,并根据指引完成异常修复(如有)。相关文档请参见实例诊断,该功能正在邀测中,如需使用,请联系客户经理申请。
GPT(Generative Pre-trained Transformer )指OpenAI发布的一系列大型语言模型,它们在大型文本数据集上训练,可被用于文本生成,翻译,分类等任务。GPT系列包括GPT-3,GPT-4等。
机型限制
单机训练:支持GPU计算型和高性能计算GPU型实例。
多机训练:仅支持高性能计算GPU型实例,且不包括hpcg1ve和hpcpni3h。其中,hpcpni3h实例正在邀测中,如需使用,请联系客户经理申请。
有关实例机型的更多信息,请参见实例规格介绍。
准备环境
您已拥有一台或多台GPU实例,本文分别命名为node1、node2。每台实例的基本配置如下:
云盘空闲容量在90GiB以上。
已绑定公网IP,使其具备访问公网的能力。
本文GPU实例的镜像以Ubuntu 20.04为例,您也可以任选其它镜像。
参考登录Linux实例登录各节点,并完成下述操作。
已安装GPU驱动和CUDA工具包。
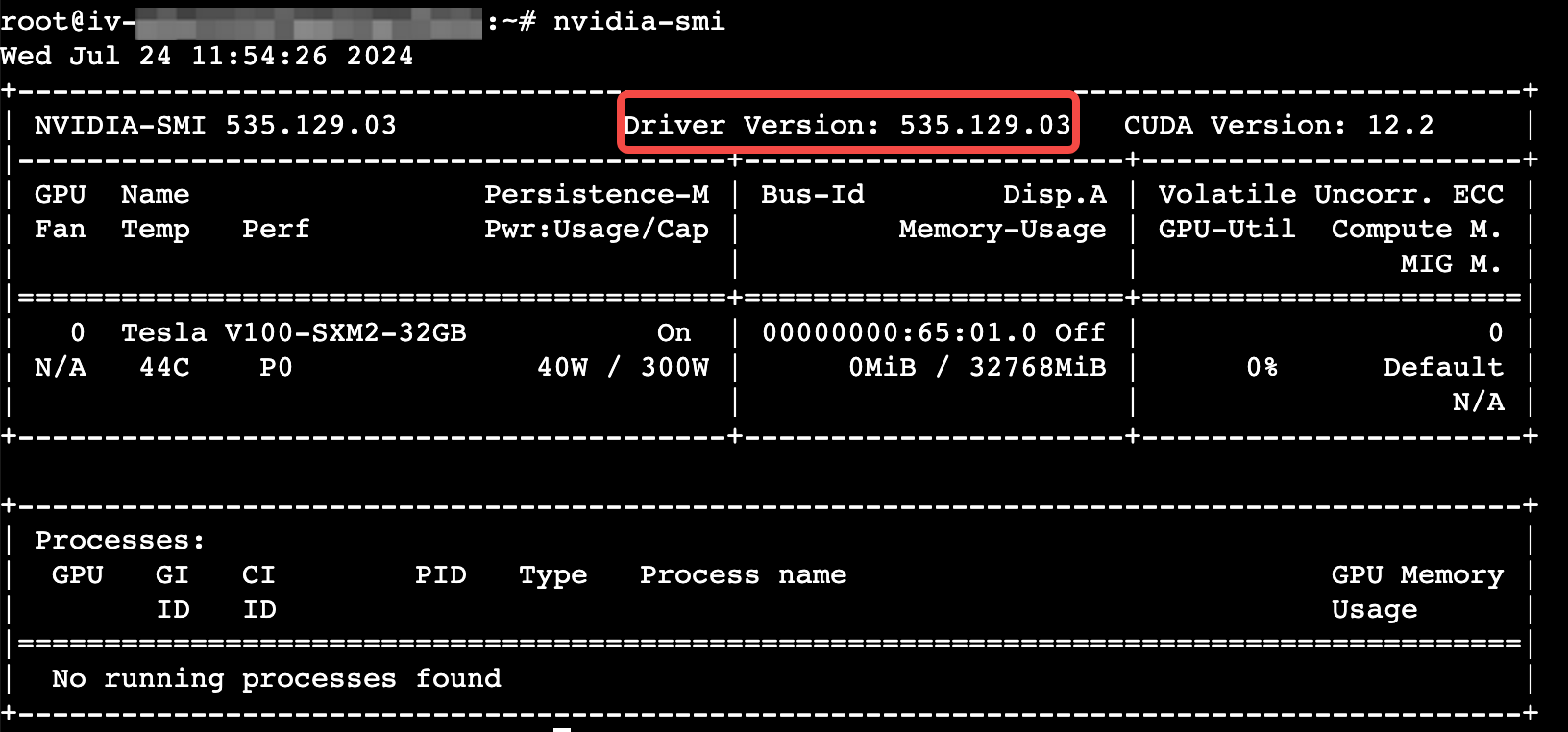
分别执行以下命令,确认GPU驱动和CUDA是否安装。若未安装,请安装CUDA工具包、安装GPU驱动。
nvidia-smi/usr/local/cuda/bin/nvcc -V
回显如下,表示已成功安装。

已安装Python和Docker。
分别执行以下命令,查看Python和Docker版本。若未安装,请安装python、安装docker和nvidai docker。
python --versiondocker --version

操作步骤
参考文件传输概述,将以下mlp_easy_gpt.py文件上传至云服务器实例。
在实例内部执行以下命令,运行mlp_easy_gpt.py脚本。
请将-i后的IP替换为每台实例主网卡的私网IP地址,不同IP之间用“,”分隔,顺序可以互换。如何查看私网IP地址,请参考查看实例信息。
如果是单机环境,请执行:
python3 mlp_easy_gpt.py -i <实例的私网IP地址>
如果是多机环境,请执行:
python3 mlp_easy_gpt.py -i <node1的私网IP地址,node2的私网IP地址>
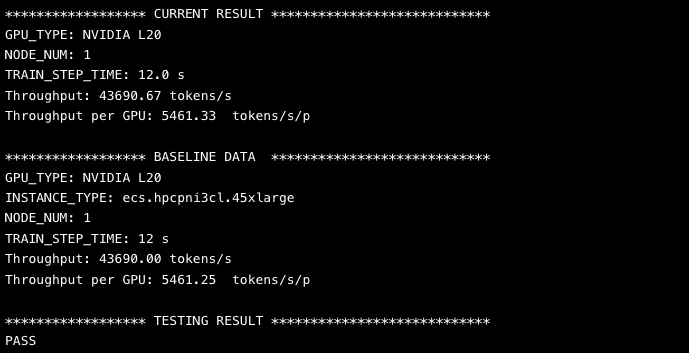
结果判定
类型 | node1(主节点) | node2 |
查看性能 | 说明 主节点输出性能数据,多节点性能数据以单节点线性扩展,计算公式如下:
其中,n为机器数量,实测性能大于Baseline,则代表机器性能符合预期。
部分错误码说明如下:
| 无操作 |
收集日志 | 主节点收集distributed_gpt.log文件:
cat distributed_gpt.log
请参考文件传输概述。 | |
查看RDMA监控流量 | 如何查看实例GPU/RDMA监控数据。 | |
|
| |