👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
NCCL(Nvidia Collective multi-GPU Communication Library,读作 "Nickel")是一个提供GPU间通信基元的库,它具有拓扑感知能力,可以轻松集成到应用程序中。NCCL做了很多优化,以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。NCCL支持安装在单个节点或多个节点上的大量GPU卡上,并可用于单进程或多进程(如MPI)应用。
如需查看高性能计算GPU实例的GPU、RDMA等配置信息,请参见实例规格介绍。其中,ebmhpcpni3l、hpcpni3h实例正在邀测中,如需使用,请联系客户经理申请。
性能指标
准备环境
您已拥有一台或多台高性能计算GPU实例。本文以两台实例为例,分别命名为node1、node2,每台实例的基本配置如下:
已绑定公网IP,使其具备访问公网的能力。
本文GPU实例的镜像以Ubuntu 20.04为例,您也可以任选其它镜像。
参考登录Linux实例登录各节点,并完成下述操作。
已安装GPU驱动和CUDA工具包。
nvidia-smi/usr/local/cuda/bin/nvcc -V
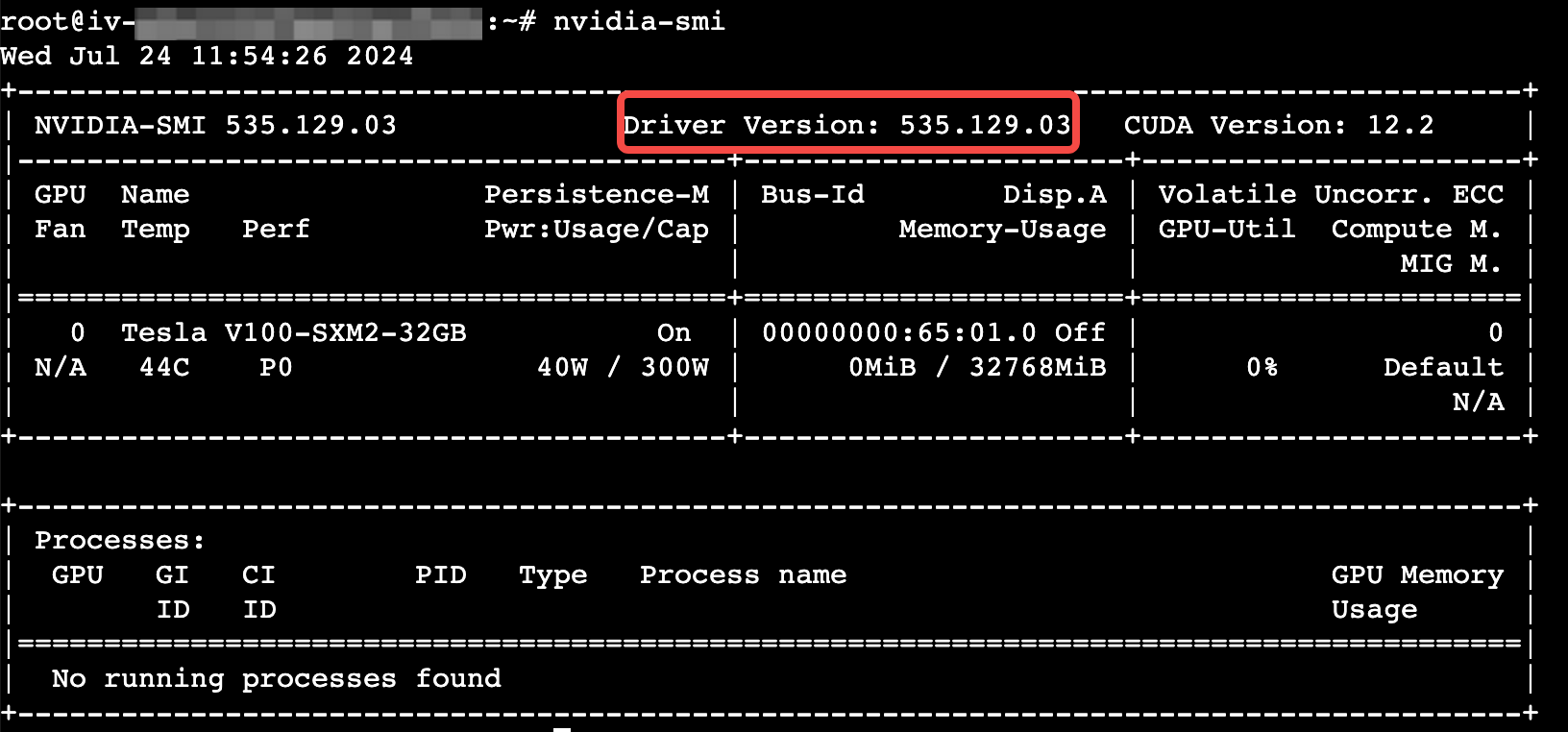

已安装NVIDIA Container Toolkit,具体操作请参见Nvidia官方指导。
确定资源占用。
lsof -i:22223 # 查看占用目标端口的进程信息kill <PID> # 将<PID>替换为占用目标端口的实际进程ID
操作步骤
步骤一:启动并进入容器
在各节点上,分别执行以下命令,启动容器。
node1上执行:
docker run -itd \--gpus all --net=host \--shm-size=100g \--ulimit memlock=-1 \--ulimit stack=67108864 \--privileged --ipc=host \--security-opt seccomp=unconfined \--cap-add=ALL \-v /var/run/nvidia-topologyd/:/var/run/nvidia-topologyd/ \iaas-gpu-cn-beijing.cr.volces.com/iaas_health/easy_nccl:ubuntu2204_cuda121_python310_nccl221_p22223 bash
node2上执行:
docker run -itd \--gpus all --net=host \--shm-size=100g \--ulimit memlock=-1 \--ulimit stack=67108864 \--privileged --ipc=host \--security-opt seccomp=unconfined \--cap-add=ALL \-v /var/run/nvidia-topologyd/:/var/run/nvidia-topologyd/ \iaas-gpu-cn-beijing.cr.volces.com/iaas_health/easy_nccl:ubuntu2204_cuda121_python310_nccl221_p22223 bash
在node1和node2上,执行以下命令,进入容器的bash环境。
docker exec -it <container_id> bash
步骤二:运行NCCL测试
命令中的NCCL相关参数介绍如下:
环境变量 | 说明 |
NCCL_IB_HCA | 指定使用哪些RDMA网卡进行通信,请根据机型的RDMA配置填写对应的值,例如:8卡套餐为mlx5_1:1 ~ mlx5_8:1,4卡为mlx5_1:1 ~ mlx5_4:1,单卡为mlx5_1:1。各机型的推荐配置详见下述命令。 |
NCCL_IB_DISABLE | 是否关闭RDMA通信,设置为1表示启用TCP通信(非RDMA),设置为0(推荐)表示启用RDMA通信。 |
NCCL_SOCKET_IFNAME | 指定用于通信的IP接口,设置成主机的host网卡(如eth0),可通过ip a命令查找。 |
NCCL_IB_GID_INDEX | 设置RDMA通信优先级,执行show_gids命令确认对应的RoCE网卡的gid index(组标识符索引)。 |
NCCL_DEBUG | NCCL输出的调试日志级别,推荐INFO(信息级别)。 |
请将-H后的IP替换为每台实例主网卡的私网IP地址。格式为:<node1的IP>:8,<node2的IP>:8,顺序可以互换。如何查看私网IP地址,请参考查看实例信息。
ebmhpcpni2l / ebmhpcpni2 / ebmhpchfpni2 / hpcpni2
机型配置 | node1操作 | node2操作 |
两机16卡 | mpirun--mca plm_rsh_no_tree_spawn 1-mca btl_tcp_if_include eth0-bind-to socket-mca pml ob1 -mca btl '^uct'-x NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1-x NCCL_IB_DISABLE=0-x NCCL_SOCKET_IFNAME=eth0-x NCCL_IB_GID_INDEX=3-x NCCL_DEBUG=INFO-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH--allow-run-as-root-H <node1的私网IP>:8,<node2的私网IP>:8/root/nccl-tests/build/all_reduce_perf -b 256M -e 8G -f 2 -g 1 | 无操作 |
单机8卡 | mpirun--mca plm_rsh_no_tree_spawn 1-mca btl_tcp_if_include eth0-bind-to socket-mca pml ob1 -mca btl '^uct'-x NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1-x NCCL_IB_DISABLE=0-x NCCL_SOCKET_IFNAME=eth0-x NCCL_IB_GID_INDEX=3-x NCCL_DEBUG=INFO-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH--allow-run-as-root-H <node1的私网IP>:8/root/nccl-tests/build/all_reduce_perf -b 256M -e 8G -f 2 -g 1 |
ebmhpcpni3l / hpcpni3ln
机型配置 | node1操作 | node2操作 |
两机16卡 | mpirun--mca plm_rsh_no_tree_spawn 1-mca btl_tcp_if_include eth0-bind-to socket-mca pml ob1 -mca btl '^uct'-x NCCL_IB_HCA=mlx5_-x NCCL_IB_DISABLE=0-x NCCL_SOCKET_IFNAME=eth0-x NCCL_IB_GID_INDEX=3-x NCCL_DEBUG=INFO-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH--allow-run-as-root-H <node1的私网IP>:8,<node2的私网IP>:8/root/nccl-tests/build/all_reduce_perf -b 1G -e 8G -f 2 -g 1 | 无操作 |
hpcpni3h
机型配置 | node1操作 | node2操作 |
两机16卡 | mpirun--mca plm_rsh_no_tree_spawn 1-mca btl_tcp_if_include eth0-bind-to socket-mca pml ob1 -mca btl '^uct'-x NCCL_IB_HCA=mlx5_-x NCCL_IB_DISABLE=0-x NCCL_SOCKET_IFNAME=eth0-x NCCL_IB_GID_INDEX=3-x NCCL_DEBUG=INFO-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH--allow-run-as-root-H <node1的私网IP>:8,<node2的私网IP>:8/root/nccl-tests/build/all_reduce_perf -b 1G -e 8G -f 2 -g 1 | 无操作 |
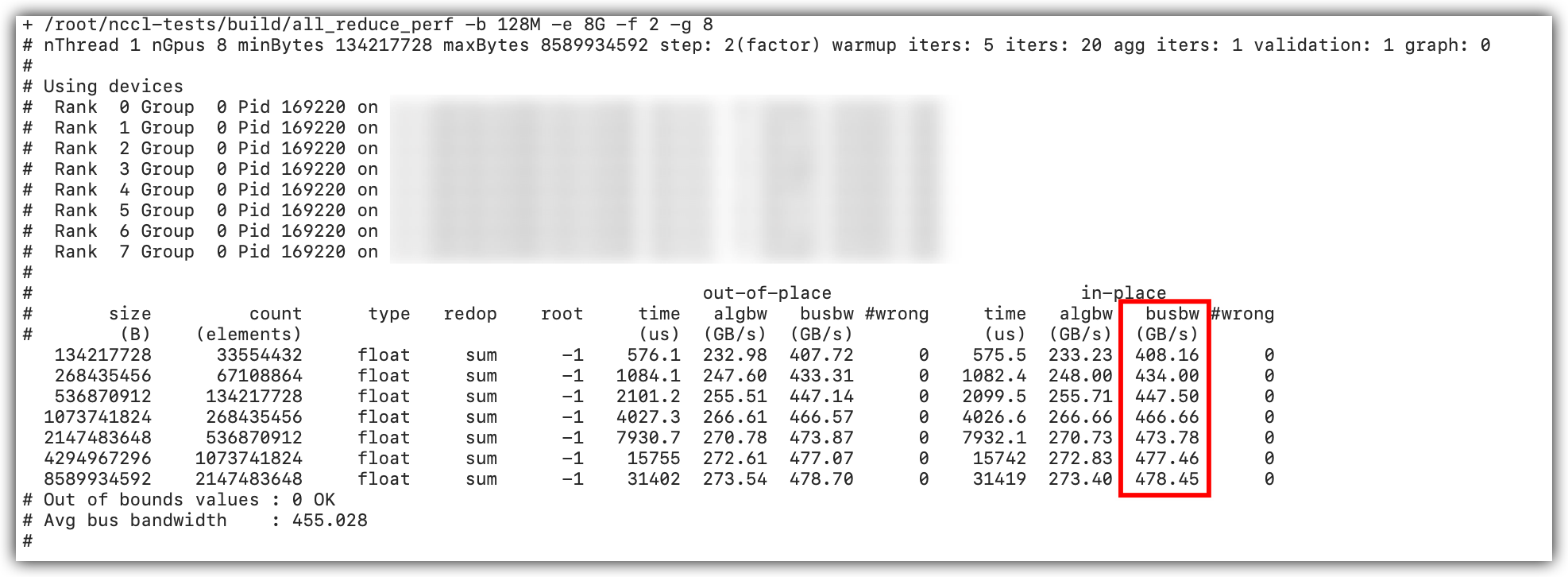
示例基线
ebmhpcpni2 / ebmhpchfpni2 / hpcpni2
实例数量 | 操作类型 | 总线带宽busbw(GB/s) |
2 | allreduce | 97.42 |
alltoall | 22.77 | |
reduce_scatter | 97.44 | |
all_gather | 96.96 | |
1 | allreduce | 233.59 |
alltoall | 219.25 | |
reduce_scatter | 229.07 | |
all_gather | 222.43 | |
sendrecv | 149.83 |
ebmhpcpni2l
实例数量 | 操作类型 | 总线带宽busbw(GB/s) |
64 | allreduce | 97.04 |
alltoall | 9.57 | |
reduce_scatter | 97.33 | |
all_gather | 96.32 | |
sendrecv | 11.63 | |
broadcast | 75.64 | |
32 | allreduce | 96.42 |
alltoall | 10.66 | |
reduce_scatter | 97.29 | |
all_gather | 96.01 | |
sendrecv | 11.64 | |
16 | allreduce | 97.28 |
alltoall | 12.80 | |
reduce_scatter | 97.35 | |
all_gather | 97.29 | |
sendrecv | 11.63 | |
broadcast | 90.73 | |
8 | allreduce | 97.41 |
sendrecv | 11.62 | |
broadcast | 94.06 | |
4 | allreduce | 97.40 |
alltoall | 15.44 | |
reduce_scatter | 97.34 | |
all_gather | 97.23 | |
sendrecv | 11.62 | |
broadcast | 95.77 | |
2 | allreduce | 97.16 |
allreduce_splitmask7 | 12.23 | |
alltoall | 22.75 | |
reduce_scatter | 97.28 | |
all_gather | 96.85 | |
sendrecv | 21.92 | |
1 | allreduce | 155.77 |
alltoall | 149.73 | |
reduce_scatter | 155.87 | |
all_gather | 151.52 | |
sendrecv | 149.83 |
ebmhpcpni3l
实例数量 | 操作类型 | 总线带宽busbw(GB/s) |
1 | allreduce | 478.7 |
alltoall | 320.27 | |
allgather | 367.63 | |
reduce_scatter | 363.01 | |
sendrecv | 332.88 | |
broadcast | 364.05 | |
2 | allreduce | 480 |
reduce_scatter | 374.89 | |
broadcast | 333.88 |
hpcpni3ln
实例数量 | 操作类型 | 总线带宽busbw(GB/s) |
2 | allreduce | 317.99 |
alltoall | 45.55 | |
allgather | 194.13 | |
reduce_scatter | 194.35 | |
sendrecv | 34.31 | |
broadcast | 192.43 | |
4 | allreduce | 189.85 |
alltoall | 30.81 | |
allgather | 193.82 | |
reduce_scatter | 194.18 | |
sendrecv | 34.58 | |
broadcast | 190.65 |