👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
本文主要介绍如何在云服务器实例中部署不同参数量级的DeepSeek-R1-Distill模型并使用CPU进行推理,以及通过Intel xFasterTransformer实现推理过程加速的方案。
背景信息
DeepSeek-R1-Distill模型
模型名称 | 参数量级 |
DeepSeek-R1-Distill-Qwen-1.5B | 1.5B |
DeepSeek-R1-Distill-Qwen-7B | 7B |
DeepSeek-R1-Distill-Llama-8B | 8B |
DeepSeek-R1-Distill-Qwen-32B | 32B |
xFasterTransformer
oneCCL
oneDNN
使用场景
低成本体验
开发和调试
轻量级模型需求
操作步骤
步骤一:准备环境
配置项 | 推荐配置 |
基础配置 | |
计算规格 | ecs.c3il.2xlarge 说明 若您期望部署不同参数规模的DeepSeek-R1-Distill模型,可参考如下推荐选用实例:
|
镜像 | Ubuntu 22.04 64 bit |
存储 |
说明 本文使用的DeepSeek-R1-Distill-Qwen-1.5B模型参数量为1.5B,您可以根据实际部署的模型参数量级调整云盘容量。推荐配置如下:
|
网络配置 | |
弹性公网IP | 勾选“分配弹性公网IP”。 |
步骤二:部署模型
方案 | 支持模型 | 说明 |
通过Docker部署(推荐) |
|
|
手动部署 |
|
|
通过Docker部署:
登录目标实例。
执行如下命令,安装Docker。
sudo apt update sudo apt install -y docker.io
执行如下命令,启动Docker和模型服务。
docker run -d --network host --privileged --shm-size 15g -v /data00/models:/data00/models -e MODEL_PATH=/data00/models -e PORT=8000 -e MODEL_NAME=DeepSeek-R1-Distill-Qwen-7B -e DTYPE=bf16 -e KV_CACHE_DTYPE=fp16 ai-containers-cn-beijing.cr.volces.com/deeplearning/xft-vllm:1.8.2.iaas bash /llama2/entrypoint.sh
MODEL_PATH:模型存储路径,默认为/data/models。
MODEL_NAME:待部署的模型名称,默认值为DeepSeek-R1-Distill-Qwen-7B。取值支持:DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-32B。
PORT:服务监听的端口号,默认值8000。
DTYPE:模型量化类型,默认值为bf16。取值支持:auto、half、float16、bfloat16、float、float32、fp16、bf16、int8、w8a8、int4、nf4、bf16_fp16、bf16_int8、bf16_w8a8、bf16_int4、bf16_nf4、w8a8_int8、w8a8_int4、w8a8_nf4。
KV_CACHE_DTYPE:KV_CACHE量化类型,默认值为fp16。取值支持:auto、fp8、fp8_e5m2、fp8_e4m3、fp16、int8。
执行如下命令,通过Docker日志确认容器及模型是否成功启动。
查看容器ID。
docker ps
查看对应容器的运行日志。
docker logs --since 30m <CONTAINER_ID>
执行如下命令,查看端口启动情况。
netstat -lntp | grep 8000
手动部署:
登录目标实例。
(可选)安装依赖工具及软件。
执行如下命令,确认GCC版本。
gcc --version
若版本不低于10,请继续后续步骤。

若版本低于10,请执行如下命令,升级GCC版本。
sudo apt update sudo apt install -y gcc
执行如下命令,安装Git。
sudo apt update sudo apt install -y git
执行如下命令,安装oneCCL。
git clone https://github.com/oneapi-src/oneCCL.git /tmp/oneCCL \ && cd /tmp/oneCCL \ && git checkout 2021.9 \ && sed -i 's/cpu_gpu_dpcpp/./g' cmake/templates/oneCCLConfig.cmake.in \ && mkdir build \ && cd build \ && cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local/oneCCL \ && make -j install \ && cd ~ \ && rm -rf /tmp/oneCCL \ && echo "source /usr/local/oneCCL/env/setvars.sh" >> ~/.bashrc
安装oneDNN。
执行如下命令,安装oneDNN。
cd /usr/local wget https://github.com/oneapi-src/oneDNN/releases/download/v0.21/mklml_lnx_2019.0.5.20190502.tgz \ && tar -xzf mklml_lnx_2019.0.5.20190502.tgz \ && rm -f mklml_lnx_2019.0.5.20190502.tgz \ && echo 'export LD_LIBRARY_PATH=/usr/local/mklml_lnx_2019.0.5.20190502/lib:$LD_LIBRARY_PATH' >> ~/.bashrc
执行如下命令,验证安装结果。
cat ~/.bashrc | grep '/usr/local/mklml_lnx_2019.0.5.20190502/lib:$LD_LIBRARY_PATH'
如下图所示时,表示已成功安装oneDNN。

若未成功安装,请重新执行安装命令进行安装。
安装xFasterTransformer。
(可选)若您配置了加速代理,请执行如下命令移除代理。
unset https_proxy unset http_proxy
执行如下命令,安装xFasterTransformer。
apt update apt install wget curl numactl -y pip install torch==2.0.1+cpu --index-url https://download.pytorch.org/whl/cpu pip install cmake==3.26.1 sentencepiece==0.1.99 tokenizers==0.13.3 accelerate==0.23.0 pip install xfastertransformer pip install gradio protobuf google pip install transformers==4.44.0
执行如下命令,安装vllm-xft。
pip install vllm-xft
(可选)若您的实例使用Intel® Granite Rapids(GNR)处理器,请执行如下命令下载额外依赖。
if lscpu | grep -q "6986P-C"; then pip install xfastertransformer-gnr fi
下载模型文件。
Qwen模型:
执行如下命令,配置密钥并安装依赖工具。
wget -qO - https://mirrors.ivolces.com/extra-tools/debian/GPG-KEY-system | apt-key add - echo 'deb http://mirrors.ivolces.com/extra-tools/debian buster main' > /etc/apt/sources.list.d/volctools.list apt update && apt install -y onion-ai-data
执行如下命令,下载模型。
region_id=`curl 100.96.0.96/latest/region_id`
allowed_regions="cn-beijing cn-shanghai cn-guangzhou ap-southeast-1"
if ! echo "$allowed_regions" | grep -wq "$region_id";then
region_id="cn-beijing"
fi
export REGION=${region_id}
mkdir -p /data/models
cd /data/models
export BUCKET=iaas-public-model-${region_id}
oniond download model DeepSeek-R1-Distill-Qwen-7B
export BUCKET=iaas-public-xfast-${region_id}
oniond download model DeepSeek-R1-Distill-Qwen-7B-xft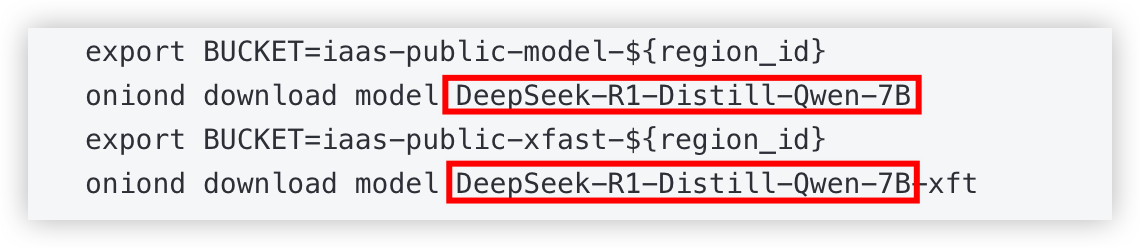
运行推理服务。
执行如下命令,创建startds.sh文件。
vim /root/startds.sh
按i键进入编辑模式,将如下内容粘贴入文件中。
#!/bin/bash
MODEL_PATH=${MODEL_PATH:-"/data/models"}
MODEL_NAME=${MODEL_NAME:-"DeepSeek-R1-Distill-Qwen-7B"}
PORT=${PORT:-8000}
DTYPE=${DTYPE:-"bf16"}
KV_CACHE_DTYPE=${KV_CACHE_DTYPE:-"fp16"}
declare -a groups
#The server needs to be bound to physical cores when starting
function get_bind_core
{
RUN_NODE=$(ls -d /sys/devices/system/node/node* | wc -l)
BIND_CORENUM=`cat /proc/cpuinfo | grep -E 'processor|core id|physical id' | sed 'N;N;s/\n/ /g' | sort -k 7 -k 11 -u | wc -l`
THREAD_PER_CORE=`lscpu | grep 'Thread(s) per core' | awk '{print $NF}'`
if [ $THREAD_PER_CORE -gt 1 ]; then
if grep ',' /sys/devices/system/cpu/cpu0/topology/core_cpus_list &> /dev/null; then
BIND_CORE_JOINER=","
elif grep '-' /sys/devices/system/cpu/cpu0/topology/core_cpus_list &> /dev/null; then
BIND_CORE_JOINER="-"
else
echo ">>> Get unknown CPU topo: `cat /sys/devices/system/cpu/cpu0/topology/core_cpus_list`, please check" && exit 255
fi
bind_cores=`cat /sys/devices/system/cpu/cpu*/topology/core_cpus_list | awk -F "$BIND_CORE_JOINER" '{print $1}' | sort -n | uniq | head -n ${BIND_CORENUM} | xargs`
last_bind=""
for c in $bind_cores; do
if [ -z "$bind_core_set" ]; then
bind_core_set+="$c"
last_bind=$c
else
if [ $((last_bind+1)) -eq $c ]; then
((last_bind+=1))
if [ $c == `echo $bind_cores | awk '{print $NF}'` ]; then
if [ $bind_core_set == `echo $bind_cores | awk '{print $1}'` ]; then
bind_core_set+="-$c"
else
bind_core_set+="$c"
fi
else
bind_core_set+="-"
fi
else
bind_core_set+=",$c"
last_bind=$c
fi
fi
bind_core_set=`echo $bind_core_set | sed 's/-\+/-/g'`
done
else
bind_core_set="0-$((BIND_CORENUM-1))"
fi
input=$bind_core_set
group_count=$RUN_NODE
IFS=',' read -r -a array <<< "$input"
if [[ $input == *-* ]]; then
IFS='-' read -r start end <<< "$input"
range_size=$(( (end - start + 1) / group_count ))
for ((i = 0; i < group_count; i++)); do
group_start=$(( start + i * range_size ))
group_end=$(( group_start + range_size - 1 ))
if [[ $i -eq $((group_count - 1)) ]]; then
group_end=$end
fi
groups[$i]="$group_start-$group_end"
done
else
array_length=${#array[@]}
group_size=$(( (array_length + group_count - 1) / group_count ))
for ((i = 0; i < group_count; i++)); do
group_start=$(( i * group_size ))
group_elements=("${array[@]:group_start:group_size}")
if [ ${#group_elements[@]} -gt 0 ]; then
groups[$i]=$(IFS=,; echo "${group_elements[*]}")
fi
done
fi
output="["
for ((i = 0; i < ${#groups[@]}; i++)); do
if [[ $input == *-* ]]; then
output+="${groups[$i]}"
else
output+="'${groups[$i]}'"
fi
if [ $i -ne $(( ${#groups[@]} - 1 )) ]; then
output+=","
fi
done
output+="]"
echo "core bind : $output"
}
get_bind_core
RUN_NODE=$(ls -d /sys/devices/system/node/node* | wc -l)
BIND_CORENUM=`cat /proc/cpuinfo | grep -E 'processor|core id|physical id' | sed 'N;N;s/\n/ /g' | sort -k 7 -k 11 -u | wc -l`
physical_core_count=$(($BIND_CORENUM/$RUN_NODE))
#mpirun performances better on multi-numa instance
numa_count=$(ls -d /sys/devices/system/node/node* | wc -l)
export $(python3 -c 'import xfastertransformer as xft; print(xft.get_env())')
export MODEL_PATH_XFT="$MODEL_PATH/${MODEL_NAME}-xft"
export TOKEN_PATH="$MODEL_PATH/$MODEL_NAME"
if [ "$numa_count" -gt 1 ]; then
export LD_PRELOAD=/usr/local/lib/python3.10/dist-packages/xfastertransformer/libiomp5.so && source /usr/local/oneCCL/env/setvars.sh
if [ "$numa_count" -eq 2 ]; then
OMP_NUM_THREADS=$physical_core_count mpirun \
-n 1 numactl --all -C ${groups[0]} 0 -m 0 python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH_XFT --tokenizer $TOKEN_PATH --dtype $DTYPE --kv-cache-dtype $KV_CACHE_DTYPE --served-model-name xft --port $PORT --trust-remote-code \
: -n 1 numactl --all -C ${groups[1]} -m 1 python3 -m vllm.entrypoints.slave --dtype $DTYPE --model $MODEL_PATH_XFT --kv-cache-dtype $KV_CACHE_DTYPE
elif [ "$numa_count" -eq 3 ]; then
OMP_NUM_THREADS=$physical_core_count mpirun \
-n 1 numactl --all -C ${groups[0]} -m 0 python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH_XFT --tokenizer $TOKEN_PATH --dtype $DTYPE --kv-cache-dtype $KV_CACHE_DTYPE --served-model-name xft --port $PORT --trust-remote-code \
: -n 1 numactl --all -C ${groups[1]} -m 1 python3 -m vllm.entrypoints.slave --dtype $DTYPE --model $MODEL_PATH_XFT --kv-cache-dtype $KV_CACHE_DTYPE \
: -n 1 numactl --all -C ${groups[2]} -m 2 python3 -m vllm.entrypoints.slave --dtype $DTYPE --model $MODEL_PATH_XFT --kv-cache-dtype $KV_CACHE_DTYPE
fi
else
OMP_NUM_THREADS=$physical_core_count numactl -C ${groups[0]} -m 0 python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH_XFT --tokenizer $TOKEN_PATH --dtype $DTYPE --kv-cache-dtype $KV_CACHE_DTYPE --served-model-name xft --port $PORT --trust-remote-code
fi根据实际情况,修改文首如下参数的参数值。
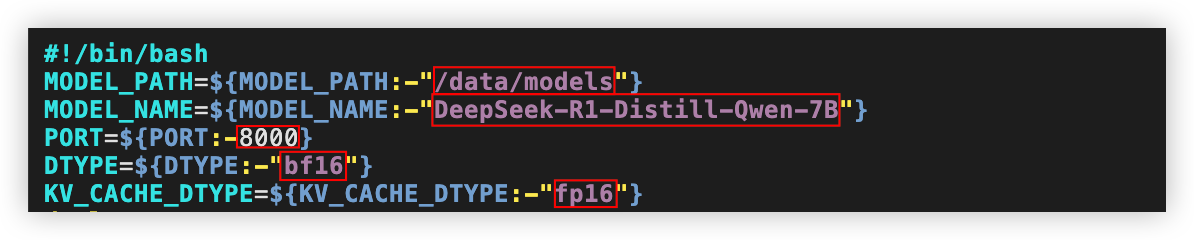
MODEL_PATH:模型存储路径,默认为/data/models。
MODEL_NAME:待部署的模型名称,默认值为DeepSeek-R1-Distill-Qwen-7B。取值支持:DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B、DeepSeek-R1-Distill-Qwen-32B。
PORT:服务监听的端口号,默认值8000。
DTYPE:模型量化类型,默认值为bf16。取值支持:auto、half、float16、bfloat16、float、float32、fp16、bf16、int8、w8a8、int4、nf4、bf16_fp16、bf16_int8、bf16_w8a8、bf16_int4、bf16_nf4、w8a8_int8、w8a8_int4、w8a8_nf4。
KV_CACHE_DTYPE:KV_CACHE量化类型,默认值为fp16。取值支持:auto、fp8、fp8_e5m2、fp8_e4m3、fp16、int8。
按esc键退出编辑,输入:wq按回车键,保存并退出文件。
执行如下命令,为startds.sh文件添加可执行权限。
sudo chmod +x /root/startds.sh
执行如下命令,启动推理服务。
sudo /root/startds.sh

Llama模型:
获取下载授权。
访问Huggingface官方meta-llama/Llama-3.1-8B模型页面。
下划阅读模型使用许可协议,并填写所需信息,单击“Submit”按钮提交申请。
申请通过后,请登录HuggingFace Token页面,获取您有下载权限的Token。详情可查看User access tokens。
登录目标实例。
执行如下命令,安装HuggingFace下载工具。
pip install -U huggingface_hub
执行如下命令,配置环境变量。
export HF_ENDPOINT=https://hf-mirror.com
执行如下命令,下载DeepSeek-R1-Distill-Llama-8B模型文件。
mkdir -p /data/models cd /data/models huggingface-cli download --resume-download --local-dir-use-symlinks False deepseek-ai/DeepSeek-R1-Distill-Llama-8B --local-dir DeepSeek-R1-Distill-Llama-8B --token <your_token>
执行如下命令,转换模型文件。
python3 -c 'import xfastertransformer as xft; xft.LlamaConvert().convert("/data/models/DeepSeek-R1-Distill-Llama-8B","/data/models/DeepSeek-R1-Distill-Llama-8B-xft")'运行推理服务。
执行如下命令,创建startds.sh文件。
vim /root/startds.sh
按i键进入编辑模式,将如下内容粘贴入文件中。
#!/bin/bash
MODEL_PATH=${MODEL_PATH:-"/data/models"}
MODEL_NAME=${MODEL_NAME:-"DeepSeek-R1-Distill-Qwen-7B"}
PORT=${PORT:-8000}
DTYPE=${DTYPE:-"bf16"}
KV_CACHE_DTYPE=${KV_CACHE_DTYPE:-"fp16"}
declare -a groups
#The server needs to be bound to physical cores when starting
function get_bind_core
{
RUN_NODE=$(ls -d /sys/devices/system/node/node* | wc -l)
BIND_CORENUM=`cat /proc/cpuinfo | grep -E 'processor|core id|physical id' | sed 'N;N;s/\n/ /g' | sort -k 7 -k 11 -u | wc -l`
THREAD_PER_CORE=`lscpu | grep 'Thread(s) per core' | awk '{print $NF}'`
if [ $THREAD_PER_CORE -gt 1 ]; then
if grep ',' /sys/devices/system/cpu/cpu0/topology/core_cpus_list &> /dev/null; then
BIND_CORE_JOINER=","
elif grep '-' /sys/devices/system/cpu/cpu0/topology/core_cpus_list &> /dev/null; then
BIND_CORE_JOINER="-"
else
echo ">>> Get unknown CPU topo: `cat /sys/devices/system/cpu/cpu0/topology/core_cpus_list`, please check" && exit 255
fi
bind_cores=`cat /sys/devices/system/cpu/cpu*/topology/core_cpus_list | awk -F "$BIND_CORE_JOINER" '{print $1}' | sort -n | uniq | head -n ${BIND_CORENUM} | xargs`
last_bind=""
for c in $bind_cores; do
if [ -z "$bind_core_set" ]; then
bind_core_set+="$c"
last_bind=$c
else
if [ $((last_bind+1)) -eq $c ]; then
((last_bind+=1))
if [ $c == `echo $bind_cores | awk '{print $NF}'` ]; then
if [ $bind_core_set == `echo $bind_cores | awk '{print $1}'` ]; then
bind_core_set+="-$c"
else
bind_core_set+="$c"
fi
else
bind_core_set+="-"
fi
else
bind_core_set+=",$c"
last_bind=$c
fi
fi
bind_core_set=`echo $bind_core_set | sed 's/-\+/-/g'`
done
else
bind_core_set="0-$((BIND_CORENUM-1))"
fi
input=$bind_core_set
group_count=$RUN_NODE
IFS=',' read -r -a array <<< "$input"
if [[ $input == *-* ]]; then
IFS='-' read -r start end <<< "$input"
range_size=$(( (end - start + 1) / group_count ))
for ((i = 0; i < group_count; i++)); do
group_start=$(( start + i * range_size ))
group_end=$(( group_start + range_size - 1 ))
if [[ $i -eq $((group_count - 1)) ]]; then
group_end=$end
fi
groups[$i]="$group_start-$group_end"
done
else
array_length=${#array[@]}
group_size=$(( (array_length + group_count - 1) / group_count ))
for ((i = 0; i < group_count; i++)); do
group_start=$(( i * group_size ))
group_elements=("${array[@]:group_start:group_size}")
if [ ${#group_elements[@]} -gt 0 ]; then
groups[$i]=$(IFS=,; echo "${group_elements[*]}")
fi
done
fi
output="["
for ((i = 0; i < ${#groups[@]}; i++)); do
if [[ $input == *-* ]]; then
output+="${groups[$i]}"
else
output+="'${groups[$i]}'"
fi
if [ $i -ne $(( ${#groups[@]} - 1 )) ]; then
output+=","
fi
done
output+="]"
echo "core bind : $output"
}
get_bind_core
RUN_NODE=$(ls -d /sys/devices/system/node/node* | wc -l)
BIND_CORENUM=`cat /proc/cpuinfo | grep -E 'processor|core id|physical id' | sed 'N;N;s/\n/ /g' | sort -k 7 -k 11 -u | wc -l`
physical_core_count=$(($BIND_CORENUM/$RUN_NODE))
#mpirun performances better on multi-numa instance
numa_count=$(ls -d /sys/devices/system/node/node* | wc -l)
export $(python3 -c 'import xfastertransformer as xft; print(xft.get_env())')
export MODEL_PATH_XFT="$MODEL_PATH/${MODEL_NAME}-xft"
export TOKEN_PATH="$MODEL_PATH/$MODEL_NAME"
if [ "$numa_count" -gt 1 ]; then
export LD_PRELOAD=/usr/local/lib/python3.10/dist-packages/xfastertransformer/libiomp5.so && source /usr/local/oneCCL/env/setvars.sh
if [ "$numa_count" -eq 2 ]; then
OMP_NUM_THREADS=$physical_core_count mpirun \
-n 1 numactl --all -C ${groups[0]} 0 -m 0 python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH_XFT --tokenizer $TOKEN_PATH --dtype $DTYPE --kv-cache-dtype $KV_CACHE_DTYPE --served-model-name xft --port $PORT --trust-remote-code \
: -n 1 numactl --all -C ${groups[1]} -m 1 python3 -m vllm.entrypoints.slave --dtype $DTYPE --model $MODEL_PATH_XFT --kv-cache-dtype $KV_CACHE_DTYPE
elif [ "$numa_count" -eq 3 ]; then
OMP_NUM_THREADS=$physical_core_count mpirun \
-n 1 numactl --all -C ${groups[0]} -m 0 python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH_XFT --tokenizer $TOKEN_PATH --dtype $DTYPE --kv-cache-dtype $KV_CACHE_DTYPE --served-model-name xft --port $PORT --trust-remote-code \
: -n 1 numactl --all -C ${groups[1]} -m 1 python3 -m vllm.entrypoints.slave --dtype $DTYPE --model $MODEL_PATH_XFT --kv-cache-dtype $KV_CACHE_DTYPE \
: -n 1 numactl --all -C ${groups[2]} -m 2 python3 -m vllm.entrypoints.slave --dtype $DTYPE --model $MODEL_PATH_XFT --kv-cache-dtype $KV_CACHE_DTYPE
fi
else
OMP_NUM_THREADS=$physical_core_count numactl -C ${groups[0]} -m 0 python3 -m vllm.entrypoints.openai.api_server --model $MODEL_PATH_XFT --tokenizer $TOKEN_PATH --dtype $DTYPE --kv-cache-dtype $KV_CACHE_DTYPE --served-model-name xft --port $PORT --trust-remote-code
fi根据实际情况,修改文首如下参数的参数值。
MODEL_PATH:模型存储路径,默认为/data/models。
MODEL_NAME:待部署的模型名称,默认值为DeepSeek-R1-Distill-Qwen-7B。取值支持:DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B、DeepSeek-R1-Distill-Qwen-32B。
PORT:服务监听的端口号,默认值8000。
DTYPE:模型量化类型,默认值为bf16。取值支持:auto、half、float16、bfloat16、float、float32、fp16、bf16、int8、w8a8、int4、nf4、bf16_fp16、bf16_int8、bf16_w8a8、bf16_int4、bf16_nf4、w8a8_int8、w8a8_int4、w8a8_nf4。
KV_CACHE_DTYPE:KV_CACHE量化类型,默认值为fp16。取值支持:auto、fp8、fp8_e5m2、fp8_e4m3、fp16、int8。
按esc键退出编辑,输入:wq按回车键,保存并退出文件。
执行如下命令,为startds.sh文件添加可执行权限。
sudo chmod +x /root/startds.sh
执行如下命令,启动推理服务。
sudo /root/startds.sh
步骤三:调用模型
登录目标实例。
执行如下命令安装jq,美化模型输出。
sudo apt install -y jq
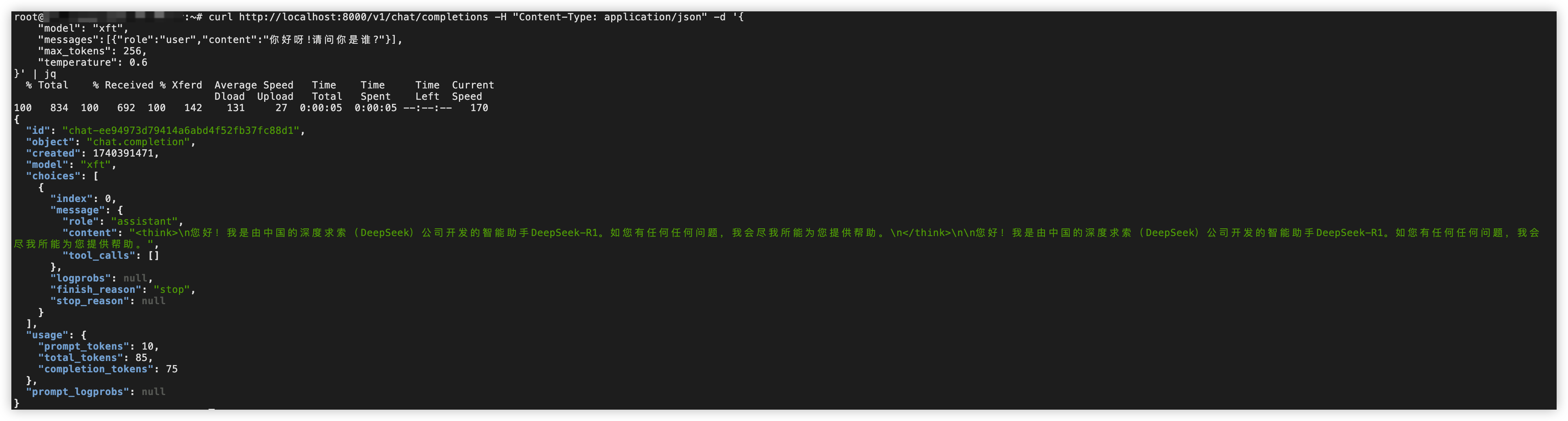
执行如下命令调用模型,确保部署的模型可以正常进行推理。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "xft","messages":[{"role":"user","content":"你好呀!请问你是谁?"}],"max_tokens": 256,"temperature": 0.6}' | jq参数名 | 说明 | 取值样例 |
model | 使用的模型名称。 | xft |
messages | 对话的消息列表。
| - |
max_tokens | 指定一次请求中模型生成Completion的最大Token数。取值:
| 100 |
temperature | 采样温度,值越高(例如1)会使输出更随机,而值越低(例如0.2)会使其更加集中和确定。取值:介于 0 和 2 之间。 | 0.7 |