👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
背景信息
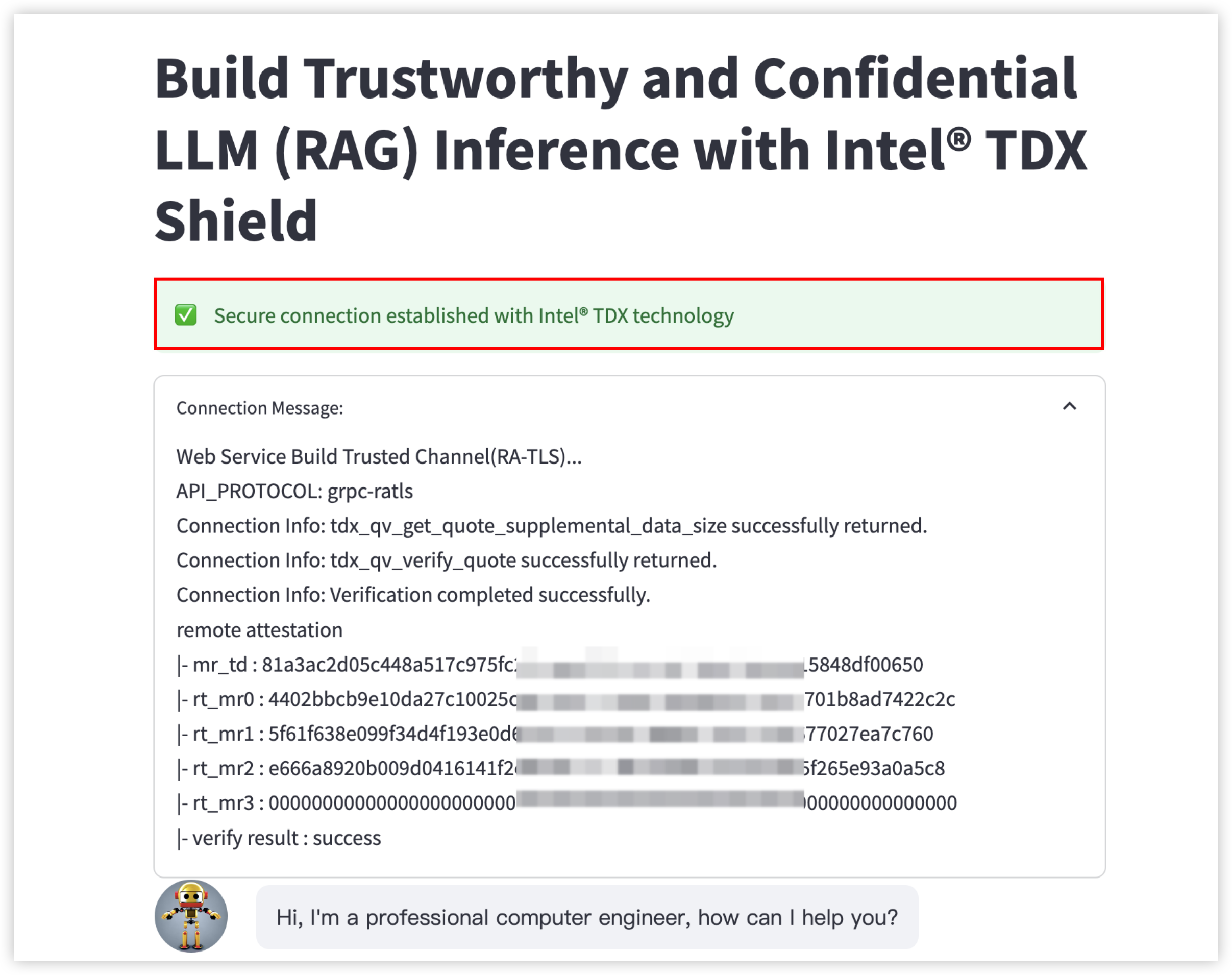
Intel® TDX
RAG
信息检索:在生成答案前,RAG会利用检索系统,从大量的文本数据(例如本地文档、互联网、企业数据库等)中查找与输入的问题或提示相关的信息。
文本生成:在获取到相关检索结果后,RAG会将检索到的文档片段与用户问题结合输入生成式AI模型(例如大型语言模型LLM),模型会将这些检索到的信息作为额外的上下文信息,与输入的问题或提示一起进行处理,然后生成相应的回答或内容。
Llama-2-7b-chat-hf模型
操作步骤
步骤一:环境准备
创建支持Intel® TDX能力的云服务器实例。操作详情可查看购买云服务器。
实例规格:本文选择安全增强通用型g3ilt(ecs.g3ilt.8xlarge)规格。
云盘:推荐系统盘容量不低于100GiB。
镜像:本文选择Ubuntu 24.04 64位。
网络:需要绑定公网IP,操作详情可查看绑定公网IP。
修改安全组配置。
登录实例控制台。
在顶部导航栏选择目标实例所在地域与项目。
单击目标实例名称进入详情页。
选择“安全组”页签。
单击“配置规则”按钮。
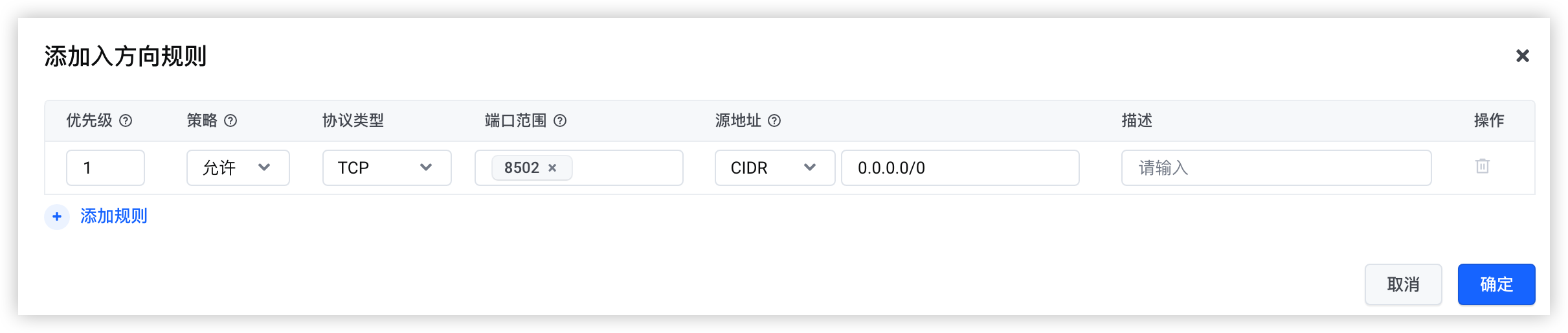
参考下图新增“入方向”规则,单击“确定”按钮完成操作。
为目标实例安装依赖工具、软件。
登录目标实例。
执行如下命令,更新APT软件源。
apt update
执行如下命令,安装依赖的工具、软件。
apt install docker.io git cryptsetup -y
执行如下命令,下载confidential-computing-zoo代码。
git clone https://github.com/intel/confidential-computing-zoo.git
(可选)创建镜像代理。
登录镜像仓库控制台。
在左侧目录树选择“实例列表 > 远端代理”。
选择创建“小微版远端代理仓”。
单击“创建远端代理仓”按钮,配置如下信息。
参数 | 说明 | 取值样例 |
域名 | 自定义代理仓的域名。本文配置为tdxdocker。 | tdxdocker |
计费类型 | 选择按量计费:后付费模式。可随开随停,按实际使用时长计费。计费详情参见产品计费。 | 按量计费 |
规格 | 选择小微版。 | 小微版 |
查看实例规格对比和配置费用,确认无误后,单击“确认订单”按钮。
仔细阅读并勾选“我已阅读并同意《镜像仓库专用服务条款》”,单击“确定”按钮提交订单,开始创建远端代理仓。
创建完成后,请记录该远端代理仓的访问域名。

单击您创建的代理仓名称进入详情页。
在左侧目录树选择“命名空间”。
单击“创建命名空间”按钮,配置如下信息。
参数 | 说明 | 取值样例 |
名称 | 自定义命名空间的名称。本文配置为library。 | library |
默认仓库类型 | 设置该命名空间下制品仓库的默认为公有类型。 | 公有 |
单击“确定”按钮,完成操作。
步骤二:构建镜像
步骤三:创建加密分区
登录目标实例。
执行如下命令,进入luks_tools目录。
cd /root/confidential-computing-zoo/cczoo/rag/luks_tools
执行如下命令,创建加密分区。
./create_encrypted_vfs.sh 50G /home/vfs
输入YES,并按回车键确认。
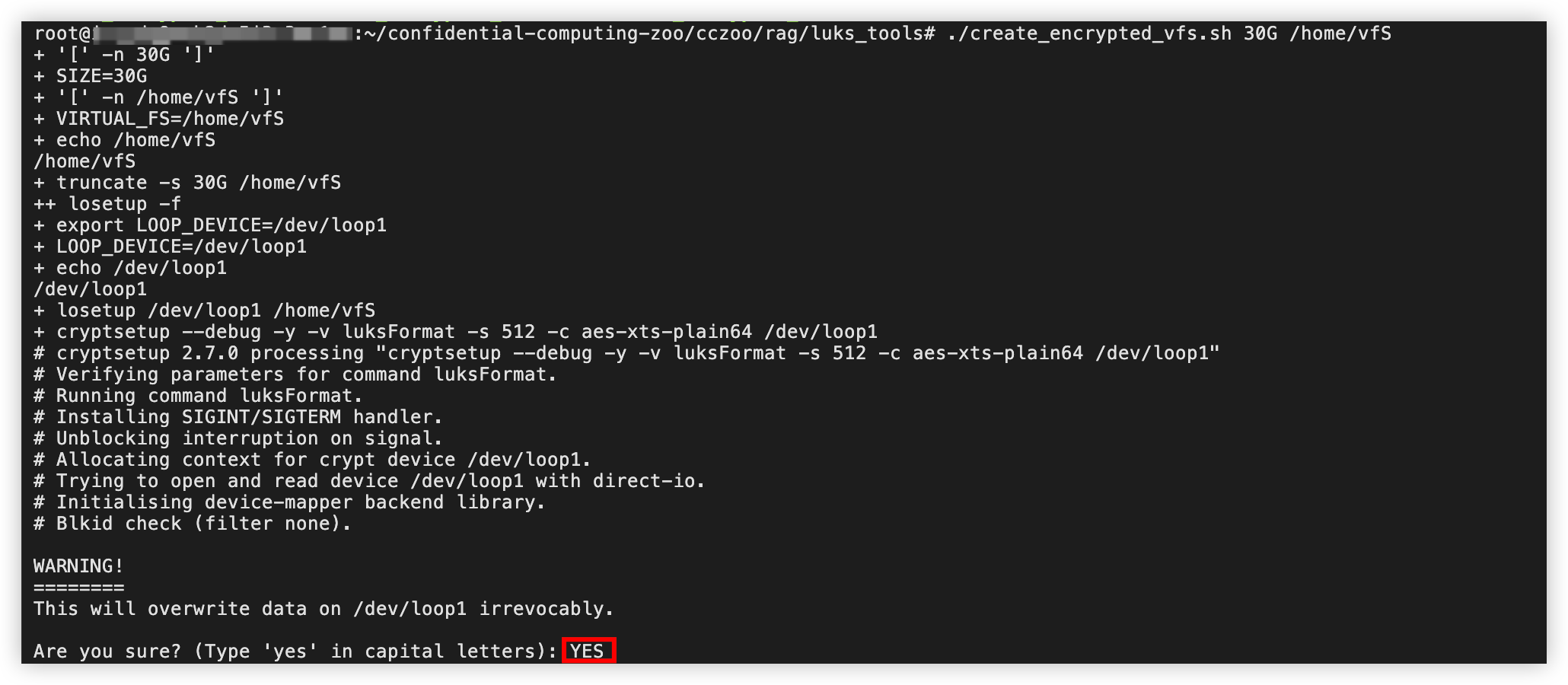
输入访问加密分区的密码,并按回车键确认。
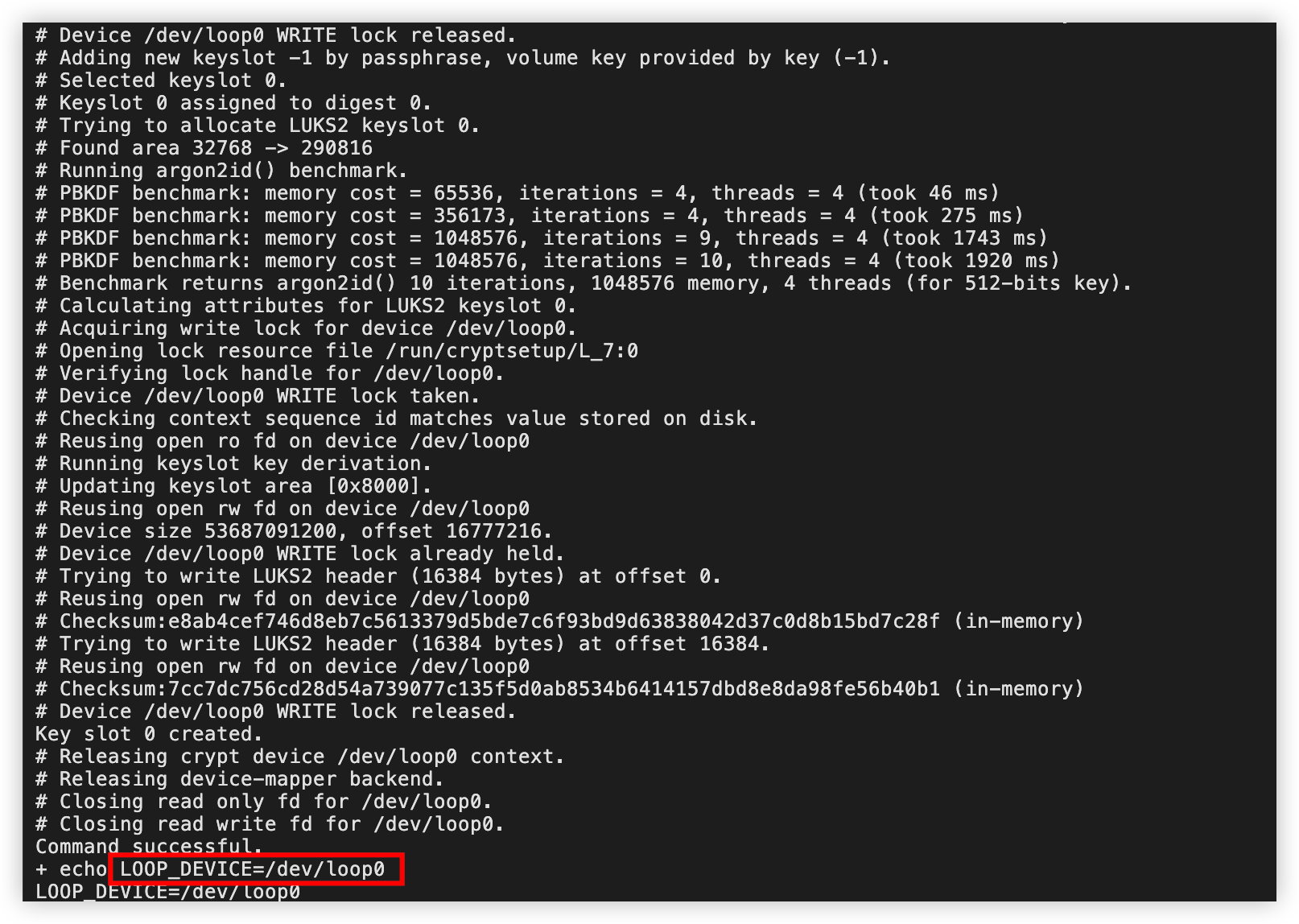
执行如下命令,设置循环设备的环境变量。
export LOOP_DEVICE=/dev/loop0
执行如下命令,创建用于存储加密数据的目录。
mkdir /home/encrypted_storage
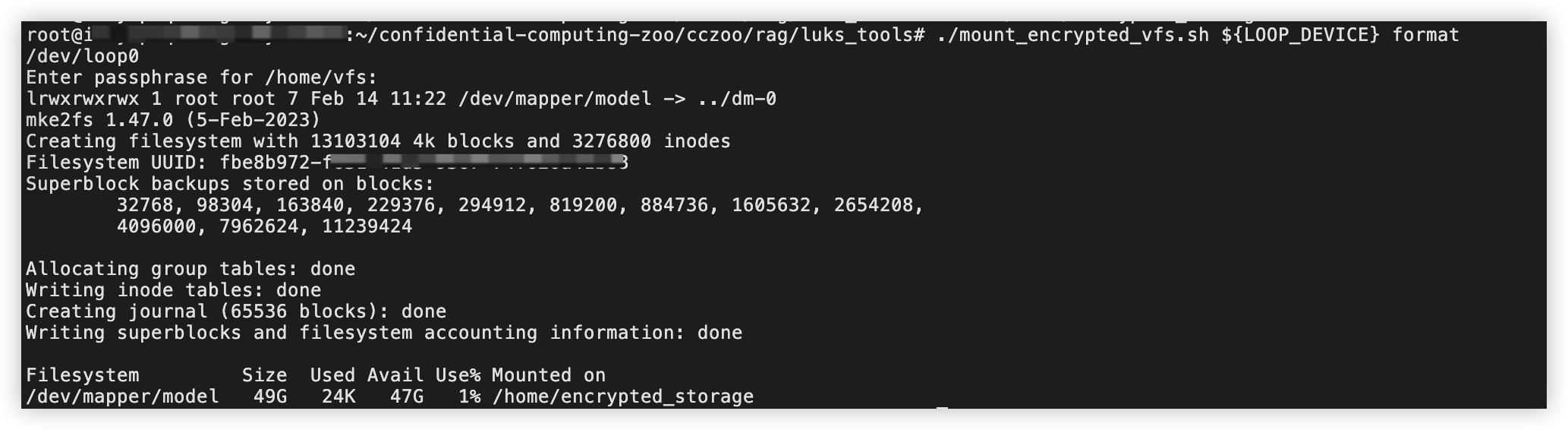
执行如下命令,将块循环设备格式化为ext4。
./mount_encrypted_vfs.sh ${LOOP_DEVICE} format根据指引输入访问加密分区的密码,按回车键确认。
步骤四:下载Llama-2-7b-chat-hf模型
获取下载授权。
访问Huggingface官方meta-llama/Llama-2-7b-chat-hf模型页面。
下划阅读模型使用许可协议,并填写所需信息,单击“Submit”按钮提交申请。
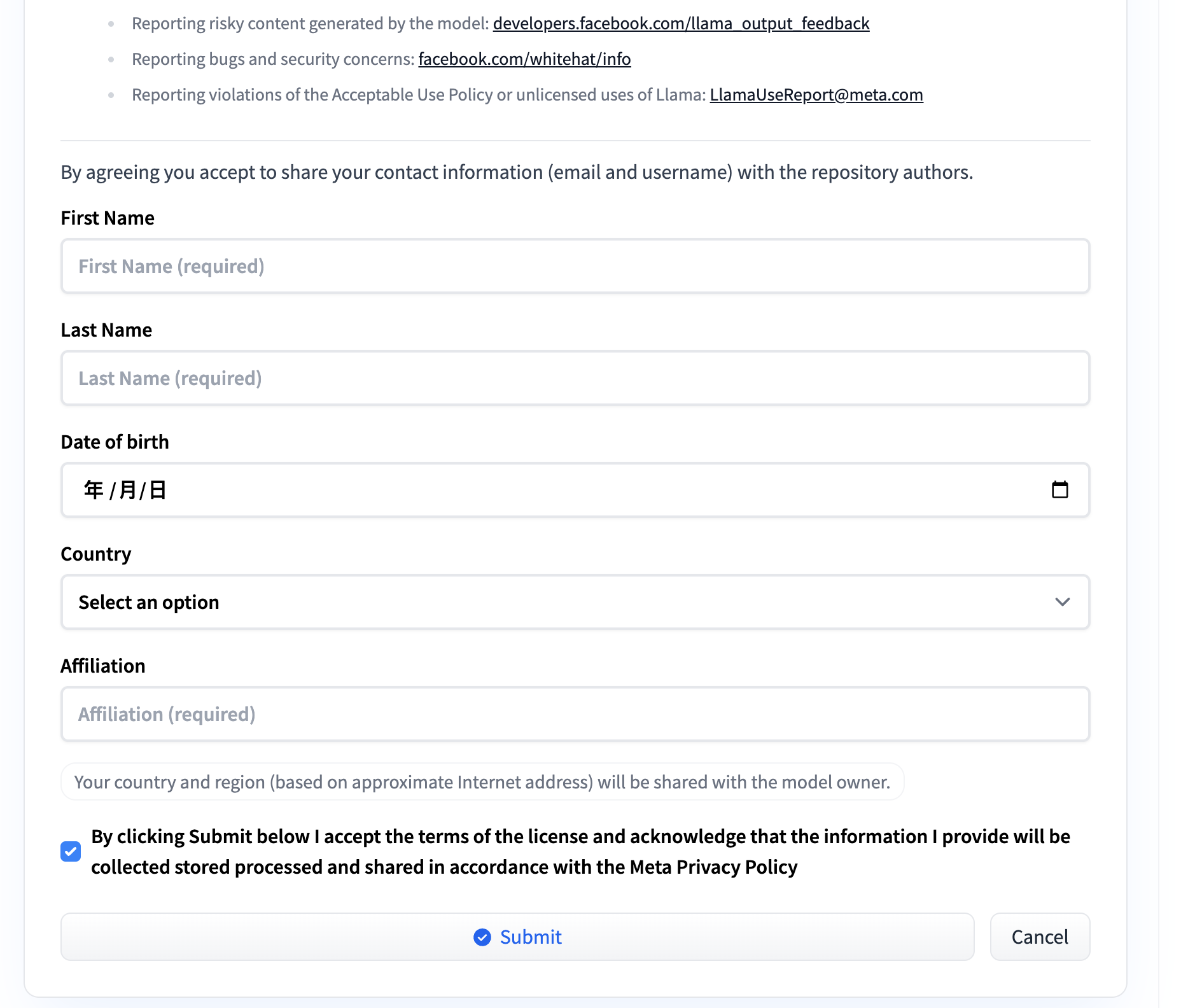
申请通过后,请登录HuggingFace Token页面,获取您有下载权限的Token。详情可查看User access tokens。
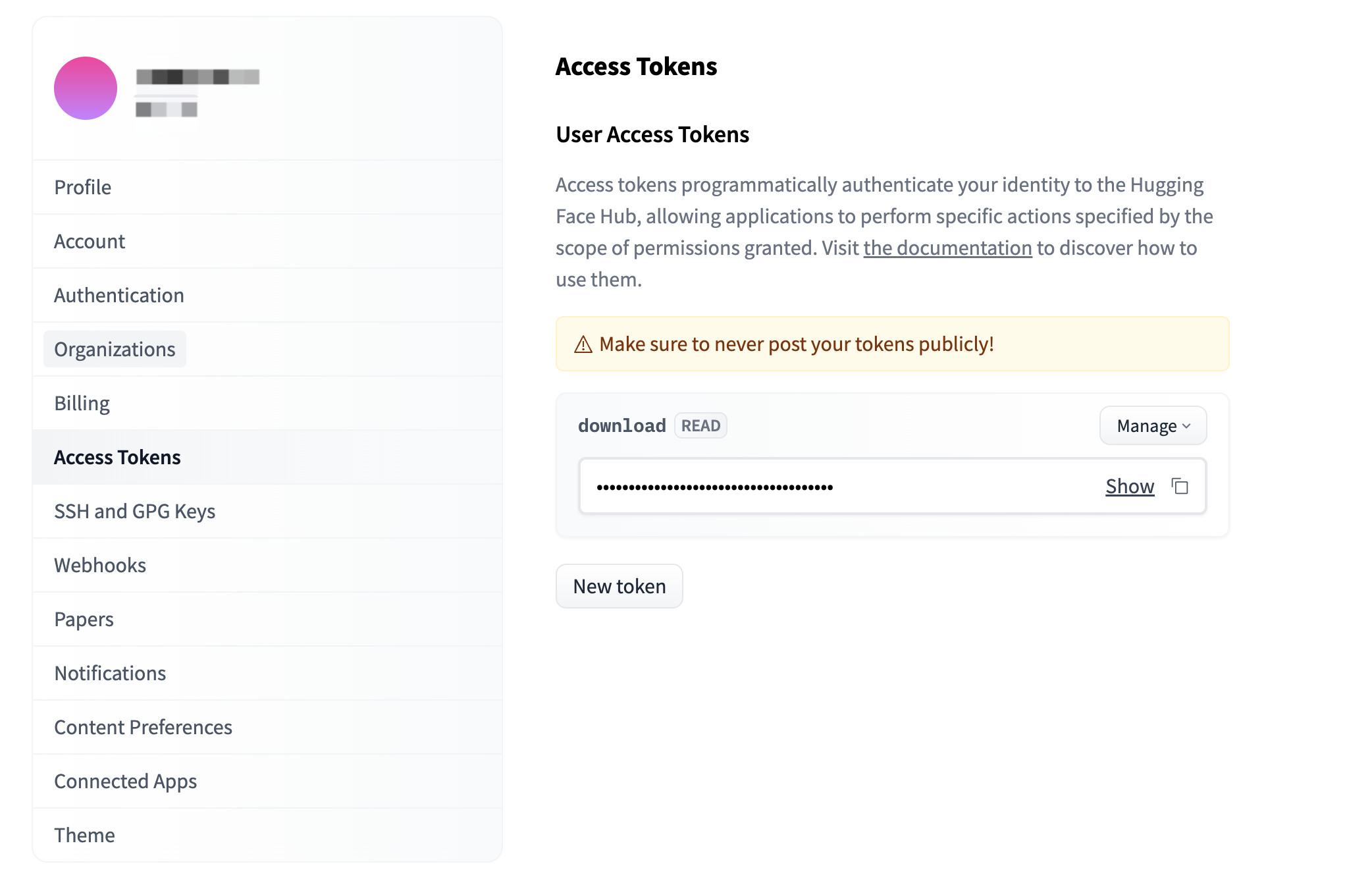
登录目标实例。
执行如下命令,进入加密分区。
cd /home/encrypted_storage
执行如下命令,安装HuggingFace下载工具。
pip install -U huggingface_hub --break-system-packages
执行如下命令,配置环境变量。
export HF_ENDPOINT=https://hf-mirror.com
下载模型文件。
执行如下命令,下载Llama-2-7b-chat-hf模型。
huggingface-cli download --resume-download --local-dir-use-symlinks False meta-llama/Llama-2-7b-chat-hf --local-dir Llama-2-7b-chat-hf --token <your_token>
执行如下命令,下载ms-marco-MiniLM-L-12-v2模型。
huggingface-cli download --resume-download --local-dir-use-symlinks False cross-encoder/ms-marco-MiniLM-L-12-v2 --local-dir ms-marco-MiniLM-L-12-v2
执行如下命令,下载dpr-ctx_encoder-single-nq-base模型。
huggingface-cli download --resume-download --local-dir-use-symlinks False facebook/dpr-ctx_encoder-single-nq-base --local-dir dpr-ctx_encoder-single-nq-base
执行如下命令,下载dpr-question_encoder-single-nq-base模型。
huggingface-cli download --resume-download --local-dir-use-symlinks False facebook/dpr-question_encoder-single-nq-base --local-dir dpr-question_encoder-single-nq-base
步骤五:配置数据库
登录目标实例。
执行如下命令,拉取MySQL数据库官方镜像。
docker pull <your_remote_proxy>/library/mysql
请将<your_remote_proxy>替换为远端代理仓访问域名。
若您未使用火山引擎远端代理仓,请执行docker pull mysql命令拉取镜像。
(可选)修改启动脚本。
执行如下命令,进入rag目录。
cd /root/confidential-computing-zoo/cczoo/rag
执行如下命令,打开启动脚本。
vim run.sh
按i键进入编辑模式,将mysql:latest修改为<your_remote_proxy>/library/mysql:latest。
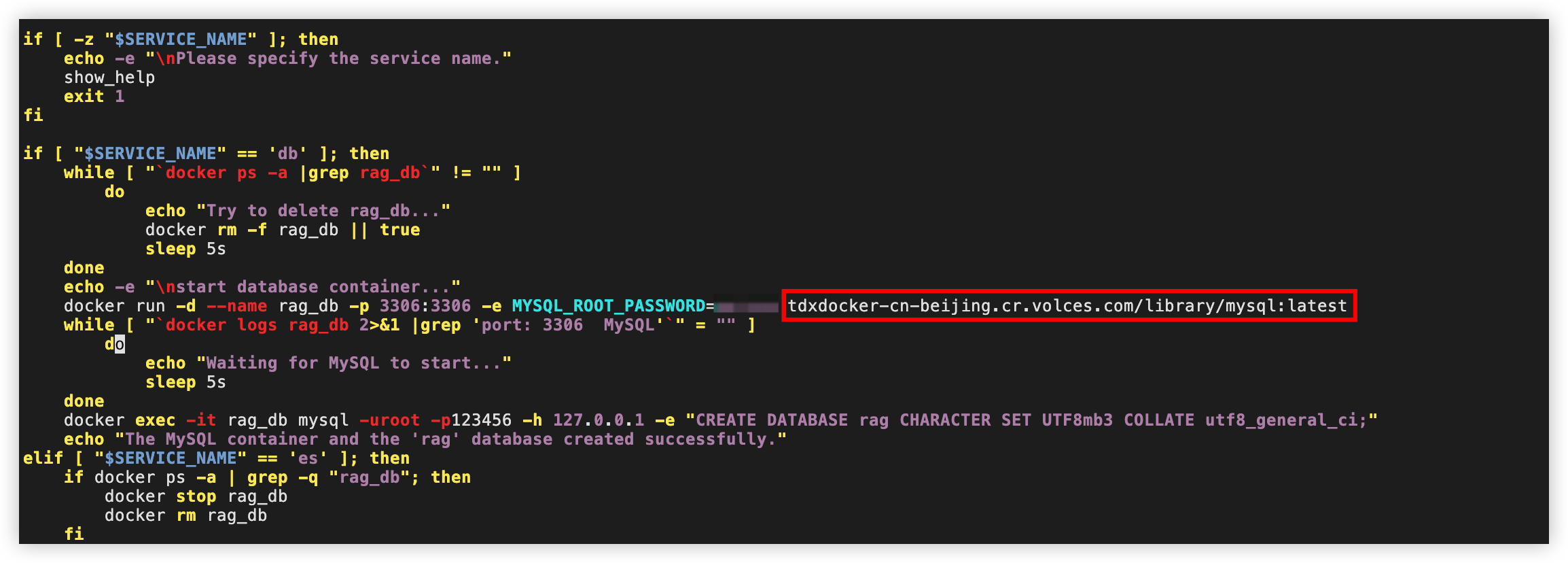
按esc键退出编辑模式,输入:wq按回车键,保存并退出文件。
步骤六:运行Llama-2-7b-chat-hf模型
登录目标实例。
启动后端推理服务。
执行如下命令,进入rag目录。
cd /root/confidential-computing-zoo/cczoo/rag
执行如下命令,启动推理后端服务。
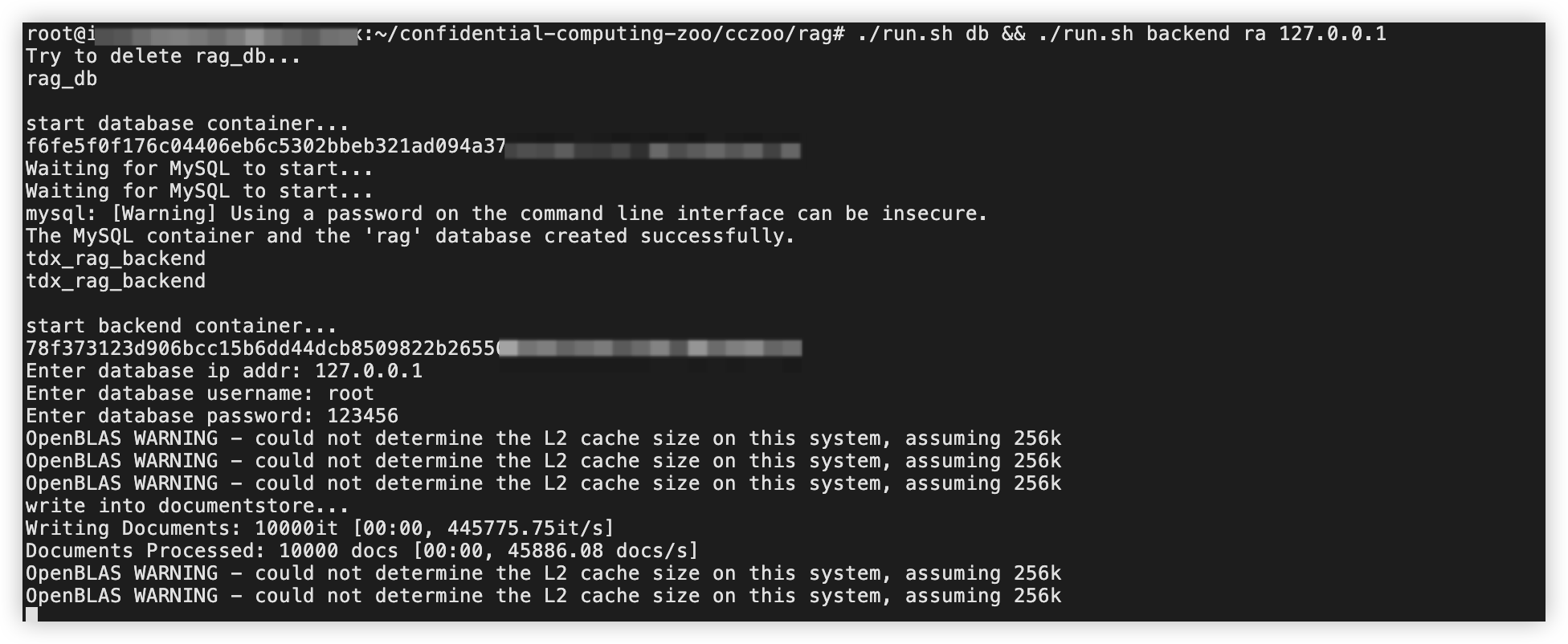
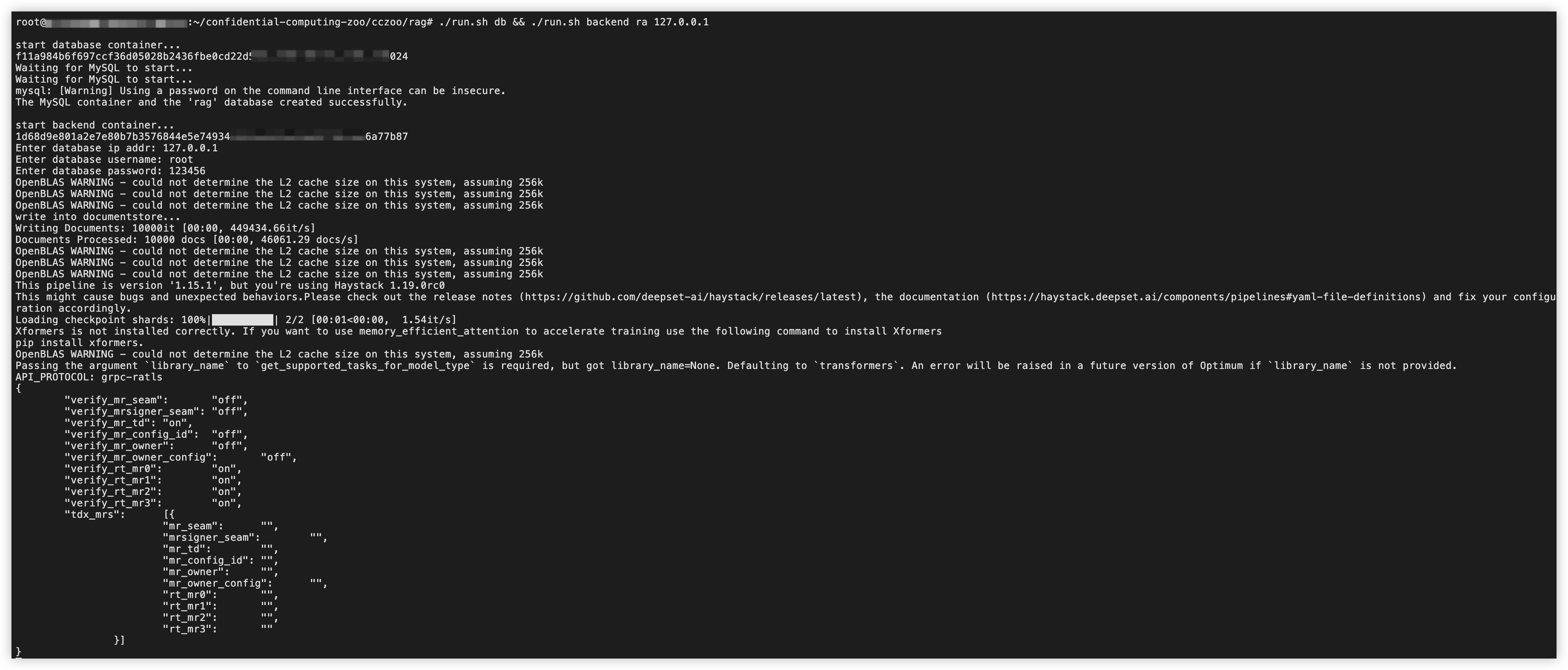
./run.sh db && ./run.sh backend ra 127.0.0.1
输入127.0.0.1按回车键。
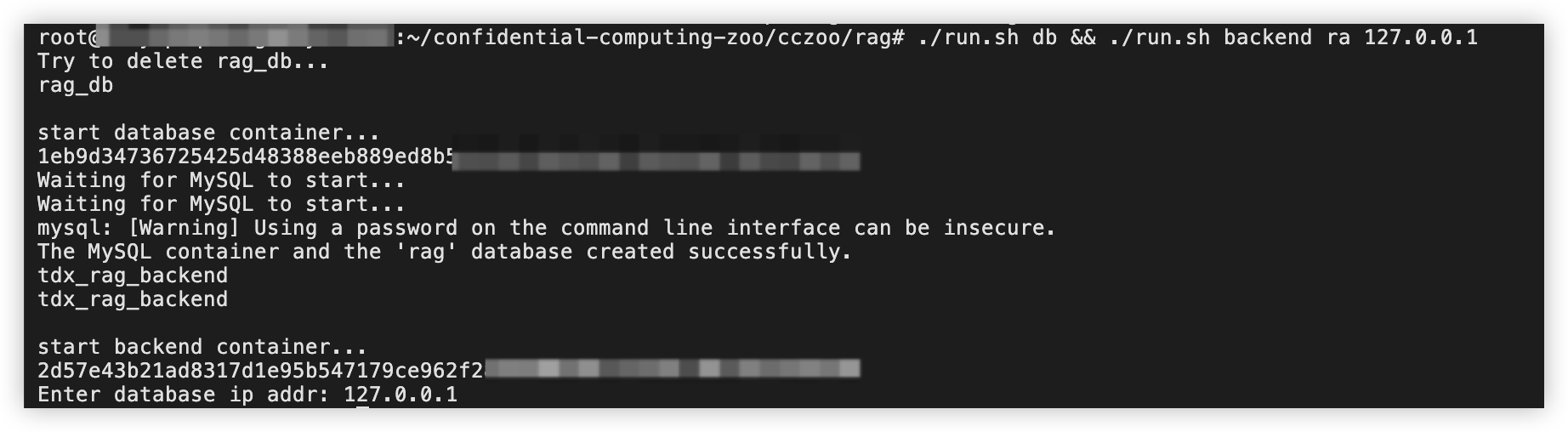
输入您配置的MySQL数据库登录用户及密码(默认用户名:root;默认登录密码 123456),按回车键确认。
启动推理前端服务。
请保留运行后端服务的终端,在浏览器中新建页面并再次登录目标实例。
在新终端中执行如下命令,进入rag目录。
cd /root/confidential-computing-zoo/cczoo/rag
在新终端中执行如下命令,启动推理前端服务。
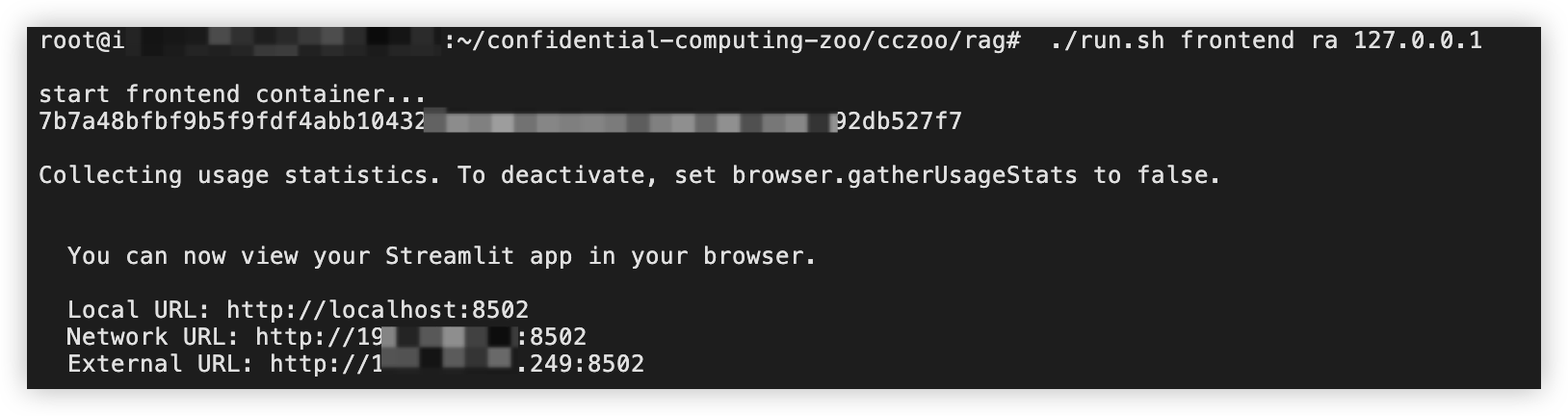
./run.sh frontend ra 127.0.0.1
待前、后端推理服务成功启动后,请分别在运行前、后端服务的终端中,分别按ctrl + c 按钮,中止服务运行。
前端启动完成示例:
后端启动完成示例:
在任意终端中,按如下步骤配置dynamic_config.json文件。
配置前端dynamic_config.json文件。
执行如下命令,获取参数值。
docker exec -it tdx_rag_backend bash -c "cd /usr/bin && ./tdx_report_parser"

执行如下命令,打开前端dynamic_config.json文件。
vim /root/confidential-computing-zoo/cczoo/rag/frontend/chatbot-rag/dynamic_config.json
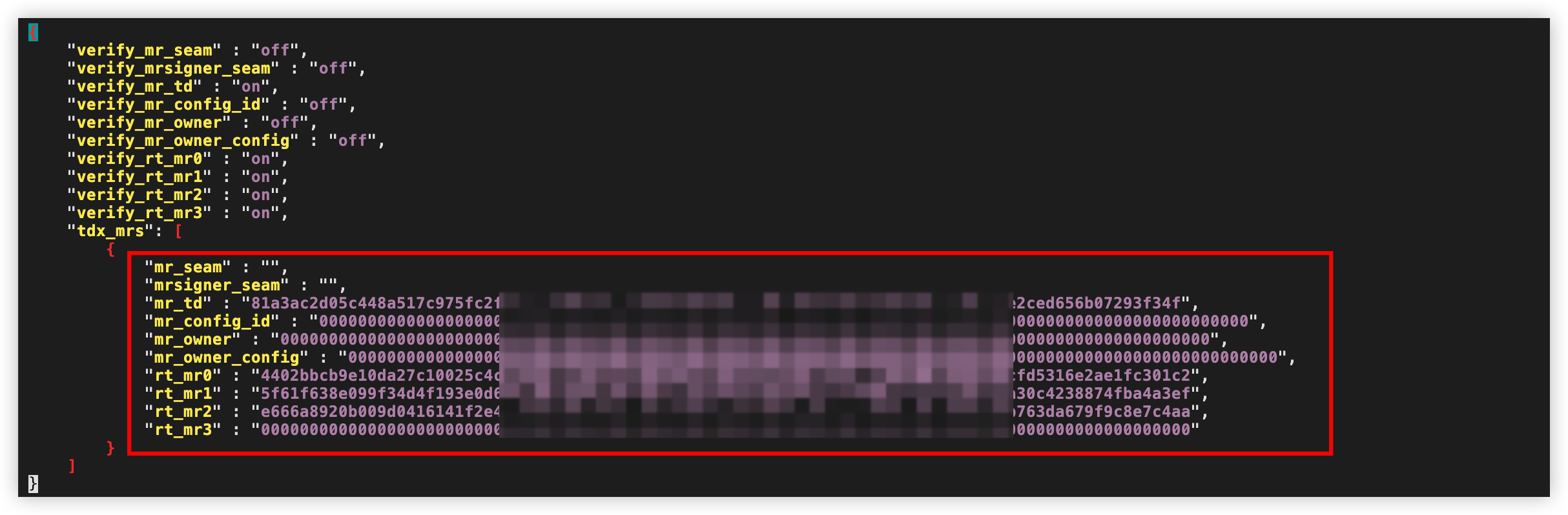
按i键进入编辑模式,将第一步获取的各参数值填入对应位置。
配置前示例:

配置后示例:
按esc键退出编辑,输入:wq按回车键,保存并退出文件。
配置后端dynamic_config.json文件。
执行如下命令,获取参数值。
docker exec -it tdx_rag_frontend bash -c "cd /usr/bin && ./tdx_report_parser"

执行如下命令,打开前端dynamic_config.json文件。
vim /root/confidential-computing-zoo/cczoo/rag/backend/pipelines/dynamic_config.json
按i键进入编辑模式,将第一步获取的各参数值填入对应位置。
配置前示例:

配置后示例:
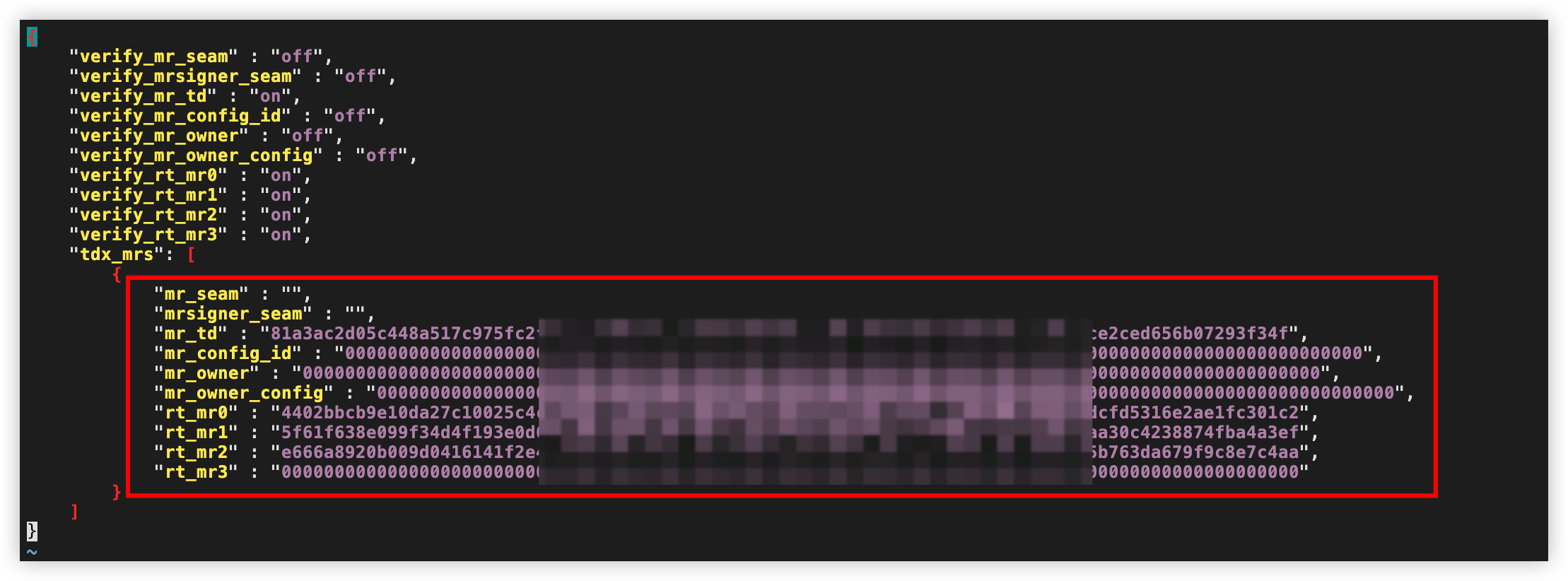
按esc键退出编辑,输入:wq按回车键,保存并退出文件。
请参考上文2、3步骤,依次启动推理后端、前端服务,并在运行前端推理服务的终端中获取External URL对应的推理页面公网访问地址。
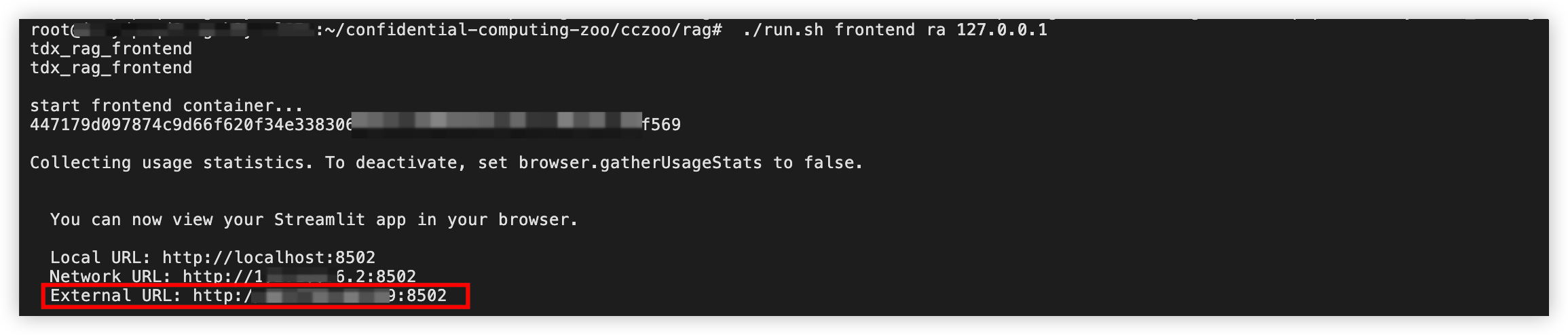
在任意可以访问公网的本地PC中,通过浏览器访问推理页面的公网访问地址即可与AI进行对话。