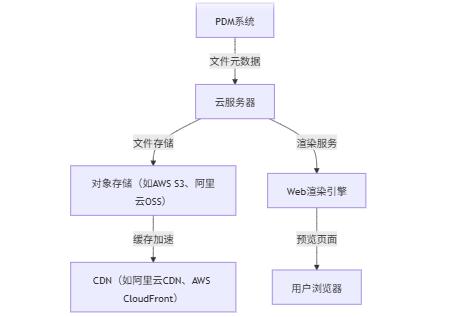
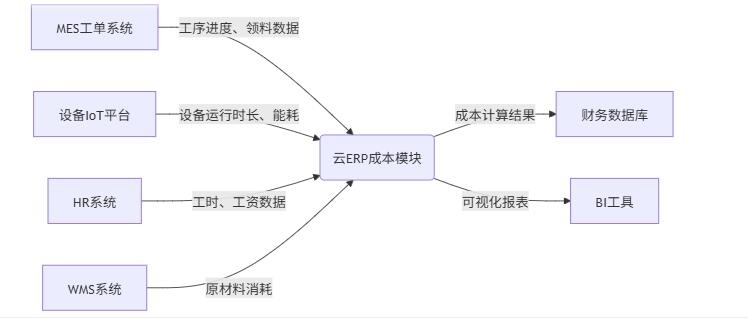
TOP云拥有分布在全国各地及海外丰富的数据中心节点,选择我们的云服务器用来部署企业财务软件、管理软件等,具有低成本高性能优点,可以让您的业务高效快速低门槛上云,选购地址:
TOP云总站云服务器购买链接:https://topyun.vip/server/buy.html
TOP云C站云服务器购买链接:https://c.topyun.vip/cart
通过云服务器日志分析优化管理软件性能,需结合日志采集、关键指标提取、根因分析、持续监控等步骤,形成闭环优化体系。以下是具体实施方案:
一、日志采集与整合
1. 全量日志收集
覆盖范围:
应用层日志:管理软件自身日志(如操作记录、错误日志、API调用日志)。
系统层日志:云服务器OS日志(如Linux /var/log/syslog、Windows事件日志)。
中间件日志:数据库(如MySQL慢查询日志)、Web服务器(如Nginx/Apache访问日志)、缓存(如Redis日志)。
云平台日志:AWS CloudTrail、Azure Monitor Logs、阿里云ActionTrail(记录API调用)。
工具选择:
开源方案:ELK Stack(Elasticsearch+Logstash+Kibana)、Fluentd+Prometheus。
云原生方案:AWS CloudWatch Logs、Azure Log Analytics、阿里云SLS(日志服务)。
2. 日志结构化处理
字段提取:
从非结构化日志中提取关键字段(如时间戳、用户ID、请求耗时、错误码),示例(Logstash配置):
filter { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log_level} %{GREEDYDATA:message}" } } json { source => "message" # 若日志为JSON格式,直接解析字段 } }标准化存储:
将日志转换为JSON或键值对格式,便于后续分析(如Elasticsearch索引)。
二、关键性能指标(KPI)提取
1. 应用性能指标
| 指标 | 日志来源 | 优化意义 |
|---|---|---|
| 请求响应时间 | 应用日志(如/api/order耗时) | 定位慢接口,优化数据库查询或缓存策略。 |
| 错误率(5xx/4xx) | 应用错误日志 | 发现系统异常(如数据库连接失败、依赖服务超时)。 |
| 并发请求数 | Web服务器日志(如Nginx active connections) | 评估负载均衡配置是否合理,是否需要扩容。 |
| 数据库查询耗时 | 数据库慢查询日志 | 优化SQL语句或添加索引。 |
2. 系统资源指标
| 指标 | 日志来源 | 优化意义 |
|---|---|---|
| CPU利用率峰值 | 系统日志(如top命令输出) | 识别计算密集型任务,优化算法或分配更多资源。 |
| 内存泄漏 | 系统日志(如OOM Killer记录) | 定位内存泄漏代码段,修复或重构。 |
| 磁盘I/O瓶颈 | 系统日志(如iowait高) | 优化频繁读写操作(如日志轮转策略、数据库表分区)。 |
三、根因分析与优化措施
1. 常见性能问题与日志特征
(1) 数据库瓶颈
日志特征:
MySQL慢查询日志中出现SELECT ... WHERE无索引查询(如rows_examined远大于rows_sent)。
数据库连接池耗尽(如HikariCP日志显示Connection timeout)。
优化措施:
添加索引(如ALTER TABLE orders ADD INDEX idx_customer_id(customer_id))。
优化SQL语句(避免SELECT *,改用字段列表)。
(2) 缓存失效
日志特征:
Redis日志频繁出现CACHE MISS,或应用日志显示重复查询相同数据。
优化措施:
调整缓存策略(如延长TTL、使用多级缓存)。
对热点数据预加载(如定时任务预热缓存)。
(3) 网络延迟
日志特征:
应用日志显示API调用延迟高(如HTTP请求耗时>2s),云平台VPC流日志显示高丢包率。
优化措施:
将依赖服务(如支付网关)切换到同地域部署,减少跨AZ流量。
启用HTTP/2或gRPC替代REST API降低延迟。
2. 日志关联分析
跨日志关联:
通过请求ID(Request ID)串联应用日志、数据库日志、API网关日志,定位全链路瓶颈。
示例:用户提交订单时,应用日志显示订单创建耗时5s→数据库日志显示库存查询耗时4s→定位为库存表未索引。
工具支持:
AWS:使用CloudWatch Logs Insights跨日志组查询。
ELK:通过transaction插件实现请求链路追踪。
四、持续监控与自动化优化
1. 实时告警配置
阈值告警:
当错误率>1%或响应时间>P95阈值时,触发钉钉/Slack告警。
示例(AWS CloudWatch Alarm):
MetricName: "5xxErrorRate"
Namespace: "AWS/ApplicationELB"
Threshold: 1
EvaluationPeriods: 2趋势告警:
通过机器学习检测异常(如AWS Lookout for Metrics识别响应时间突增)。
2. 自动化修复
脚本化响应:
自动重启异常服务(如systemctl restart nginx)。
动态扩容(如AWS Auto Scaling Group在CPU>70%时扩容EC2实例)。
配置漂移修复:
通过AWS Config或阿里云资源目录检测配置变更(如数据库连接池大小被误改),自动回滚。
五、优化效果验证
1. A/B测试对比
场景:优化数据库索引后,对比优化前后的查询性能。
方法:
使用影子流量(Shadow Traffic)将部分请求导入优化后的环境,对比响应时间。
通过日志分析优化前后的SELECT语句执行时间(如MySQL Query_time)。
2. 长期趋势分析
仪表盘监控:
在Grafana或Kibana中创建Dashboard,展示关键指标趋势(如错误率、响应时间、资源利用率)。
定期复盘:
每月分析日志,总结性能优化效果(如“索引优化后慢查询减少70%”)。
六、典型架构示例
[管理软件架构] ├── 应用层(EC2/ECS) │ ├── 应用日志(ELK采集)→ 响应时间、错误率分析 │ └── 请求ID透传(全链路追踪) ├── 数据层(RDS/Redis) │ ├── 慢查询日志(MySQL Slow Query Log)→ 索引优化 │ └── 缓存命中率日志(Redis INFO命令)→ 缓存策略调整 └── 云平台层 ├── VPC流日志(网络延迟分析) └── CloudTrail日志(API调用审计)
通过以上方法,可系统化挖掘云服务器日志中的性能瓶颈,实现管理软件的持续优化,提升用户体验和系统稳定性。