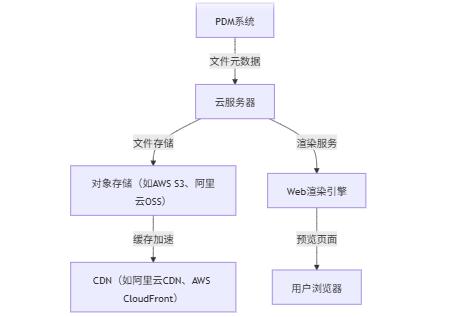
TOP云拥有分布在全国各地及海外丰富的数据中心节点,选择我们的云服务器用来部署企业财务软件、管理软件等,具有低成本高性能优点,可以让您的业务高效快速低门槛上云,选购地址:
TOP云总站云服务器购买链接:https://topyun.vip/server/buy.html
TOP云C站云服务器购买链接:https://c.topyun.vip/cart
在云服务器部署QMS(质量管理系统)时,保证检测数据不丢帧需从数据采集、传输、存储、处理全链路设计高可靠架构,并结合冗余机制、实时监控、自动化恢复策略。以下是具体实施方案:
一、数据采集层:确保源头数据完整性
1. 硬件级可靠性
工业级传感器与设备:
选用高可靠性传感器(如抗干扰工业相机、高精度称重仪),配置双电源冗余,避免因断电导致数据采集中断。
示例:康耐视In-Sight系列视觉系统支持双网口冗余,避免单点网络故障。
本地缓存缓冲:
在检测设备端部署本地缓存(如SD卡或工业级SSD),临时存储采集数据(如每秒1000条检测记录),防止网络抖动导致丢帧。
2. 采集协议优化
高可靠通信协议:
采用MQTT(QoS 2级)或OPC UA PubSub协议传输数据,确保消息不丢失、不重复(对比HTTP更可靠)。
示例:西门子SIMATIC IOT2050网关通过OPC UA PubSub将检测数据实时推送至云服务器。
数据打包与校验:
检测数据按固定大小打包(如每100条数据为一个批次),附加CRC32校验码,接收端验证完整性。
二、数据传输层:保障网络高可用
1. 网络架构设计
多链路冗余:
工厂本地部署双ISP接入(如电信+联通),通过SD-WAN(如阿里云SD-WAN、AWS Transit Gateway)动态选择最优链路。
关键数据传输使用专线(如AWS Direct Connect、阿里云Express Connect),降低延迟和丢包率。
边缘计算预处理:
在工厂边缘网关(如华为AR路由器)进行数据预处理(如去重、压缩),仅上传有效数据至云服务器,减少传输量。
2. 传输协议与容错
断点续传机制:
传输中断后,客户端记录已发送数据的偏移量(如Kafka的offset机制),网络恢复后从断点继续传输。
示例:使用AWS S3 Multipart Upload分块上传检测数据文件,支持断点续传。
实时监控与告警:
部署网络质量监控工具(如Pingmesh、Smokeping),实时检测延迟和丢包率,超阈值触发告警(如短信/钉钉通知)。
三、数据存储层:高可靠写入与持久化
1. 云存储架构
分布式对象存储:
使用高耐用性对象存储(如AWS S3、阿里云OSS),默认99.999999999%(11个9)的数据持久性,自动多副本存储(通常3副本跨可用区)。
时序数据库优化:
检测数据写入时序数据库(如AWS Timestream、阿里云TSDB),配置多可用区部署(如AWS Timestream跨3个AZ),避免单点故障。
2. 写入策略
批量提交与异步刷盘:
检测数据先缓存在内存缓冲区(如Kafka Producer Buffer),达到阈值(如1000条)或时间窗口(如1秒)后批量提交至数据库,减少I/O压力。
数据库配置异步刷盘(如MySQL
innodb_flush_log_at_trx_commit=2),平衡性能与可靠性(牺牲部分持久性换吞吐量)。数据预写入日志(WAL):
启用数据库预写入日志(如MySQL Binlog、MongoDB Oplog),即使系统崩溃也可通过日志恢复未持久化的数据。
四、数据处理层:容错与自动恢复
1. 分布式计算框架
流处理引擎:
使用Apache Flink或Kafka Streams实时处理检测数据,配置Checkpointing机制(如每10秒保存一次状态快照),故障恢复后从最近Checkpoint继续处理。
示例:Flink作业从Kafka消费检测数据,异常重启后自动恢复未完成的计算任务。
消息队列缓冲:
检测数据先写入高吞吐消息队列(如Kafka、RocketMQ),消费者(如QMS分析服务)异步处理,避免数据丢失。
配置队列持久化(如Kafka Topic副本数≥3)和消息保留策略(如保留7天)。
2. 自动化故障转移
服务无状态化:
QMS分析服务设计为无状态(Stateless),会话信息存储到Redis集群,节点故障时可快速扩容新实例。
负载均衡与健康检查:
使用云负载均衡器(如AWS ALB、阿里云SLB)分发请求,自动剔除异常节点(健康检查间隔≤10秒)。
五、监控与审计体系
1. 全链路监控
数据流向追踪:
通过分布式追踪系统(如AWS X-Ray、阿里云ARMS)跟踪检测数据从采集到存储的全链路,定位丢帧节点。
关键指标监控:
采集端:传感器数据生成速率、本地缓存利用率。
传输层:网络延迟、丢包率、MQTT消息堆积数。
存储层:数据库写入延迟、磁盘I/O利用率。
2. 审计与告警
日志集中化:
所有数据操作日志(如采集、写入、删除)实时同步至云日志服务(如AWS CloudWatch Logs、阿里云SLS),保留至少180天。
异常告警规则:
设置多级告警阈值(如“1分钟内丢帧>100条”触发严重告警,“1小时内丢帧>1000条”触发紧急告警)。
六、典型场景示例
汽车制造质检场景
数据流:
工业相机(10台)每秒采集2000张图片→边缘网关(华为AR3260)通过OPC UA PubSub推送至AWS IoT Core→Kafka消息队列→Flink实时检测(缺陷分类)→结果写入AWS Timestream。
丢帧防护措施:
边缘网关本地缓存最近1小时数据(SSD存储),网络中断时持续写入;Kafka配置3副本+日志保留7天;Timestream跨3个AZ部署。
七、成本与性能平衡建议
分层存储策略:
近期数据(7天内)存高性能存储(如AWS Timestream),历史数据转存低成本对象存储(如AWS S3 Glacier)。
弹性资源分配:
检测高峰期(如生产线满负荷)自动扩容Kafka分区和Flink算力(AWS Auto Scaling Group),低谷期缩容降低成本。
定期演练:
每月模拟网络中断、节点故障等场景,验证数据恢复流程的有效性。
通过以上方案,QMS系统可在云服务器上实现99.99%以上的检测数据完整性,满足汽车、电子、医药等行业的高精度质检需求。