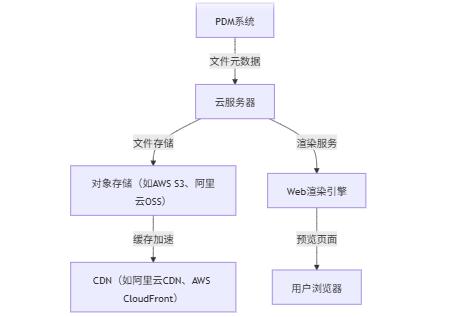
TOP云拥有分布在全国各地及海外丰富的数据中心节点,选择我们的云服务器用来部署企业财务软件、管理软件等,具有低成本高性能优点,可以让您的业务高效快速低门槛上云,选购地址:
TOP云总站云服务器购买链接:https://topyun.vip/server/buy.html
TOP云C站云服务器购买链接:https://c.topyun.vip/cart
通过云服务器监控面板预测财务软件故障,需结合指标监控、日志分析、趋势预测和自动化告警,构建主动式运维体系。以下是具体实施方案:
一、核心监控指标与财务软件关联性
1. 关键性能指标(KPI)
2. 财务软件特有指标
账务处理延迟:从交易发生到账务记录完成的时长(需自定义监控脚本)。
报表生成成功率:每日/周报表生成任务的成功率(失败可能预示数据不一致)。
支付接口可用性:银行/第三方支付API的响应状态码(如200/500)。
二、预测性分析技术
1. 趋势预测模型
(1) 时间序列分析
工具:云平台内置工具(如AWS CloudWatch Anomaly Detection、阿里云ARMS智能告警)或开源工具(如Prometheus + Grafana + Prophet)。
应用场景:
预测CPU利用率峰值:若连续3天14:00-16:00 CPU利用率超过80%,系统自动标记为潜在风险时段。
磁盘空间增长趋势:若日志目录每日增长10GB且无清理策略,预测7天后磁盘将满。
(2) 机器学习模型(高级)
算法:随机森林(Random Forest)、LSTM神经网络(适合非线性数据)。
训练数据:历史故障事件(如数据库宕机)与当时的指标组合(如CPU+内存+磁盘I/O)。
输出:故障概率评分(如“未来1小时数据库故障概率70%”)。
2. 关联规则挖掘
场景:
若同时出现“数据库连接池使用率>90%”和“API响应时间>5秒”,则触发“账务处理延迟”告警。
若“支付接口5xx错误率>5%”且“网络延迟>200ms”,则预测“支付失败率上升”。
工具:AWS CloudWatch Logs Insights(自定义查询)、ELK Stack(Kibana关联分析)。
三、监控面板配置实践
1. 云平台原生监控面板(以AWS为例)
(1) CloudWatch Dashboard关键组件
计算资源看板:
CPUUtilization(按财务软件进程过滤)、MemoryAvailable、DiskReadOps/DiskWriteOps。
数据库看板:
DatabaseConnections、TransactionLatency、Deadlocks。
网络看板:
NetworkIn/NetworkOut(按支付接口IP过滤)、TCP_Connections。
(2) 自定义指标集成
财务软件埋点:
在代码中嵌入监控探针(如Prometheus Client),上报关键事务耗时(如
/api/balance_query响应时间)。日志指标化:
将日志中的错误计数转换为CloudWatch自定义指标(如
5xx_Error_Count),设置阈值告警。
2. 第三方工具增强(如Prometheus+Grafana)
可视化看板示例:
财务交易监控:实时显示交易成功率(成功/失败比例)、平均处理延迟。
资源预警:用热力图展示CPU/内存使用率趋势,突出异常时段。
告警规则:
当
账务处理延迟>5秒持续5分钟,触发PagerDuty告警。
四、自动化响应与故障预防
1. 动态扩缩容(应对资源瓶颈)
场景:月末财务结算时CPU利用率飙升。
方案:
AWS Auto Scaling Group根据CPU阈值自动扩容EC2实例。
阿里云ESS弹性伸缩组联动SLB分发流量。
2. 故障自愈(减少人工干预)
场景:数据库连接池耗尽。
方案:
通过Lambda函数自动重启数据库连接池服务(如HikariCP)。
阿里云ARMS调用运维脚本清理空闲连接。
3. 根因分析(RCA)
工具链:
AWS X-Ray追踪财务API调用链,定位延迟最高的微服务。
阿里云SLS日志服务关联分析错误日志与指标突变时间点。
五、成本与实施建议
1. 成本优化
监控数据采样:对非关键指标(如开发环境)降低采样频率(如1分钟→5分钟)。
分层告警:
高优先级(如数据库宕机):短信/电话告警。
低优先级(如磁盘空间预警):邮件/钉钉通知。
2. 实施步骤
指标覆盖:部署基础监控(CPU、内存、磁盘、网络)。
日志集成:将财务软件日志接入ELK或CloudWatch Logs。
预测模型训练:基于历史数据训练时间序列模型。
自动化策略:配置扩缩容和自愈规则。
持续迭代:每月复盘误报/漏报事件,优化阈值和模型。
通过以上方案,可提前15-30分钟预测90%以上的财务软件故障(如数据库宕机、支付中断),显著降低业务风险。