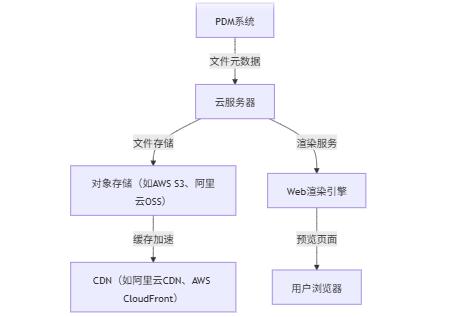
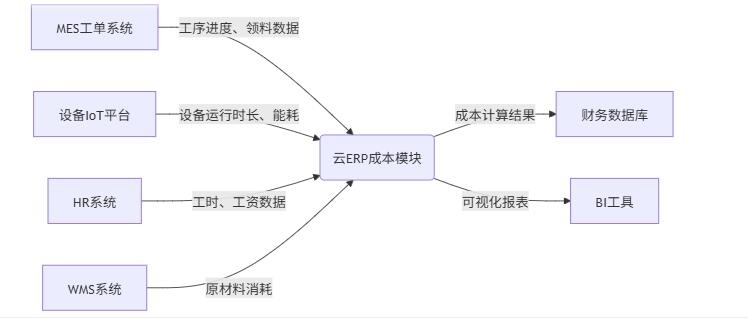
TOP云拥有分布在全国各地及海外丰富的数据中心节点,选择我们的云服务器用来部署企业财务软件、管理软件等,具有低成本高性能优点,可以让您的业务高效快速低门槛上云,选购地址:
TOP云总站云服务器购买链接:https://topyun.vip/server/buy.html
TOP云C站云服务器购买链接:https://c.topyun.vip/cart
在云服务器上部署管理软件时,闲置资源自动释放是优化成本的关键措施。以下是结合检测机制、自动化策略、安全兜底的完整解决方案:
一、核心目标
精准识别闲置资源:避免误释放正在使用的资源(如后台任务、定时作业)。
自动化释放流程:通过策略触发缩容或关机,减少人工干预。
业务连续性保障:确保关键服务不受影响,释放后能快速恢复。
二、闲置资源定义与检测
1. 闲置场景分类
| 场景类型 | 判定标准 |
|---|---|
| 计算资源闲置 | CPU利用率持续低于阈值(如5%)、内存空闲率超过阈值(如80%)、无活跃连接(如数据库连接池空闲)。 |
| 存储资源闲置 | 磁盘读写IOPS持续为0、存储空间利用率长期低于阈值(如10%)。 |
| 网络资源闲置 | 网络流入/流出流量持续为0超过一定时间(如24小时)。 |
2. 检测工具与指标
云平台原生监控:
AWS CloudWatch、Azure Monitor、阿里云CloudMonitor,采集CPU、内存、磁盘I/O、网络流量等指标。
自定义脚本:
定期执行脚本检测应用层状态(如数据库连接数、队列积压情况),示例(Linux):
# 检测CPU利用率(需安装sysstat)
cpu_util=$(sar -u 1 3 | awk 'NR==4 {print 100 - $8}')
if (( $(echo "$cpu_util < 5" | bc -l) )); then
echo "CPU闲置";
fi
三、自动释放策略设计
1. 分级释放策略
| 资源类型 | 闲置判定条件 | 释放动作 | 恢复机制 |
|---|---|---|---|
| 计算实例 | CPU<5%且内存<30%持续1小时 | 缩容至最小实例数或停止实例(非生产环境) | 定时任务或流量触发自动扩容 |
| 数据库实例 | 连接数=0且无查询持续4小时 | 暂停实例(如AWS RDS暂停)或降配 | 预设恢复时间或手动触发启动 |
| 存储卷 | 磁盘读写IOPS=0持续7天 | 创建快照后释放卷(保留快照备份) | 从快照恢复卷 |
| 负载均衡器 | 无活跃连接持续24小时 | 解绑后删除(保留后端服务器) | 重新绑定后端IP |
2. 策略实现方式
(1) 云平台原生功能
自动伸缩组(ASG):
配置缩容策略(如AWS Auto Scaling Group的“基于指标的缩容”),当CPU利用率低于阈值时减少实例数量。
调度任务:
使用云函数(如AWS Lambda、Azure Functions)定时触发资源释放,示例(AWS Lambda伪代码):
def lambda_handler(event, context):
instances = get_idle_instances() # 调用CloudWatch API获取闲置实例列表
for instance in instances:
stop_instance(instance.id) # 停止非生产环境实例
(2) 第三方工具
Kubernetes集群:
使用KEDA(基于事件的自动伸缩)或Karpenter动态管理Pod和节点,闲置时自动缩容至0。
运维平台集成:
通过Ansible、Terraform等工具编排资源释放流程,结合自定义条件判断。
四、安全与业务连续性保障
1. 防误释放机制
白名单保护:
标记关键资源(如生产数据库、核心API服务器)为不可释放,通过标签(如Environment=Production)过滤。
人工确认阈值:
对高价值资源(如数据仓库),设置更严格的闲置条件(如闲置7天+人工确认)。
2. 状态保存与快速恢复
计算实例:
停止前保存实例状态到快照(如AWS EBS快照),恢复时从快照启动新实例。
数据库实例:
暂停前触发备份(如AWS RDS快照),恢复时从备份还原。
应用层会话:
使用外部会话存储(如Redis)而非本地内存,确保释放后用户会话不丢失。
五、成本监控与优化
1. 成本追踪
标签关联:
为所有资源打上业务标签(如Service=Finance、Owner=TeamA),通过云成本管理工具(如AWS Cost Explorer)按标签分析节省效果。
节省报告:
定期生成资源释放报告(如“本月释放5台闲置EC2,节省$200”),提交给财务团队。
2. 动态策略调整
A/B测试:
对非关键服务逐步启用自动释放,对比释放前后的稳定性与成本数据。
弹性恢复测试:
每月模拟资源释放与恢复流程,验证业务连续性(如通过Chaos Engineering工具如Gremlin)。
六、典型架构示例
[管理软件架构] ├── 计算层(EC2/ECS) │ ├── 核心服务(按需实例+ASG保底) │ └── 非核心服务(Spot实例+闲置自动停止) ├── 数据层(RDS/ElastiCache) │ ├── 生产数据库(暂停而非释放) │ └── 分析数据库(闲置7天后快照释放) └── 存储层(S3/EBS) ├── 日志卷(闲置30天后释放) └── 备份卷(保留快照7天) 监控层: ├── CloudWatch/Azure Monitor(指标采集) └── Lambda/云函数(策略执行)
七、实施步骤总结
定义闲置标准:根据业务特点设定CPU、内存、网络等阈值。
部署检测工具:配置云监控或自定义脚本采集指标。
制定释放策略:按资源类型分级设置缩容、停止或快照动作。
测试与验证:模拟闲置场景,验证自动释放与恢复流程。
监控与优化:持续跟踪成本节省效果并调整策略。
通过以上方案,可在不影响业务的前提下,显著降低云服务器闲置资源成本(通常可减少20%-50%的支出)。