👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
问题描述
centos7.9系统中部署k8s,然后通过Nvidia GPU operator的方式运行Nvidia驱动,发现pod一直不能处于ready状态。
问题分析
查看Nvidia driver pod event无法获取有用信息,通过查看pod日志收集到以下信息。
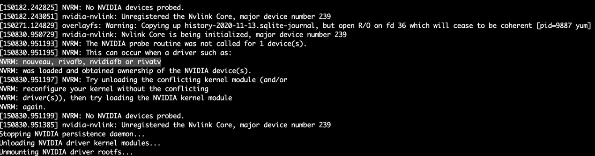
问题解决
需要从系统中去掉nouveau, rivafb, nvidiafb or rivatv这些模块。 1.把驱动加入黑名单中
cat /etc/modprobe.d/blacklist.conf blacklist nouveau options nouveau modeset=0
2.备份initramfs nouveau image镜像
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
3.使用dracut重新建立initramfs nouveau
dracut -v /boot/initramfs-$(uname -r).img $(uname -r)
4.重启系统
reboot
5.确认是否加载
lsmod | grep nouveau
6.确认Nvidia pod是否正常启动
kubectl get pod -n <GPU-namespace>