👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
本文介绍如何部署Stable Diffusion WebUI工具前端和Stable Diffusion训练模型,实现高质量AI图片生成,掌握整个AI作画推理流程及关键参数对图片输出的影响。
AIGC简介
AIGC(AI generated content)是一种利用AI技术自动生成内容的生产方式,代表着AI从理解语言、理解文字、理解图片和视频,走向了生成内容,是一种‘人机共创’新模式。
软件版本
NVIDIA驱动:本例使用Tesla 470.57.02,Cuda 11.4.1。
Python:编程语言,并提供机器学习库Numpy等。本例使用Python 3.11.3版本。
PIP:通用的Python包管理工具。本例使用PIP 20.0.2版本。
Git:分布式版本控制系统。本例使用Git 2.25.1版本
使用说明
为使Stable Diffusion WebUI与模型顺利运行,推荐实例配置为 12GB 显存,且内存大于 16GiB ,使支持的图片更大、预处理效率更高。
本例选用ecs.ini2.7xlarge计算规格,搭载NVIDIA A30 GPU卡,显存24GB,内存为234GiB。下载本例所需软件可能需要访问国外网站,建议您增加网络代理(例如FlexGW)以提高访问速度。您也可以将所需软件下载到本地,参考本地数据上传到GPU实例中。
步骤一:创建GPU计算型实例
请参考通过向导购买实例创建一台符合以下条件的实例:
计算规格:ecs.ini2.7xlarge
镜像:Ubuntu 20.04,选择后台自动安装以下GPU驱动。
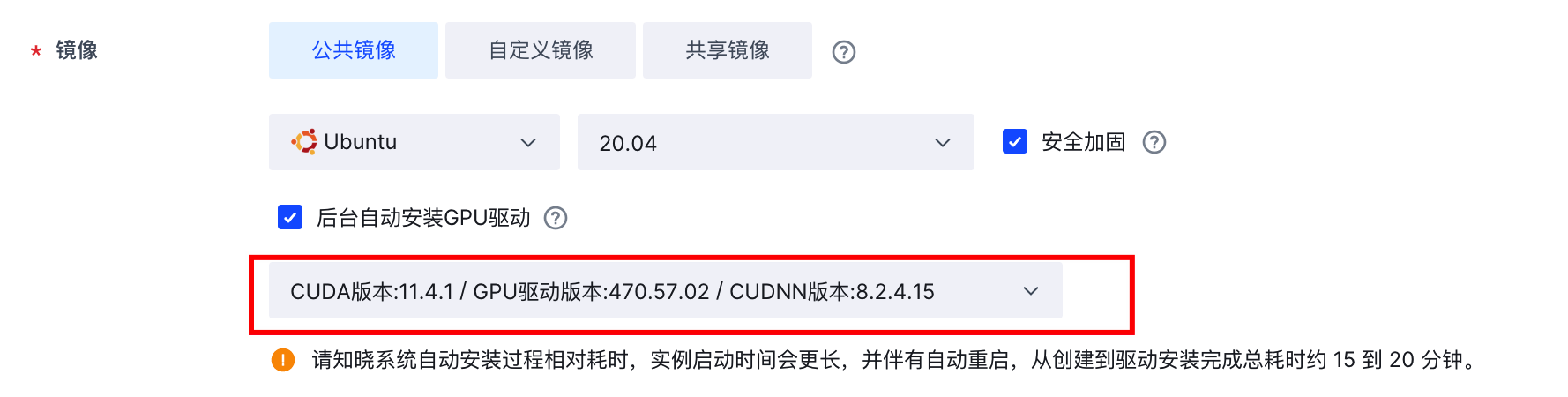
弹性公网IP:勾选“分配弹性公网IP”按钮。
步骤二:安装Python和PIP
登录Python网站。
找到并单击Python 3.11.3,进入3.11.3版本下载页面。
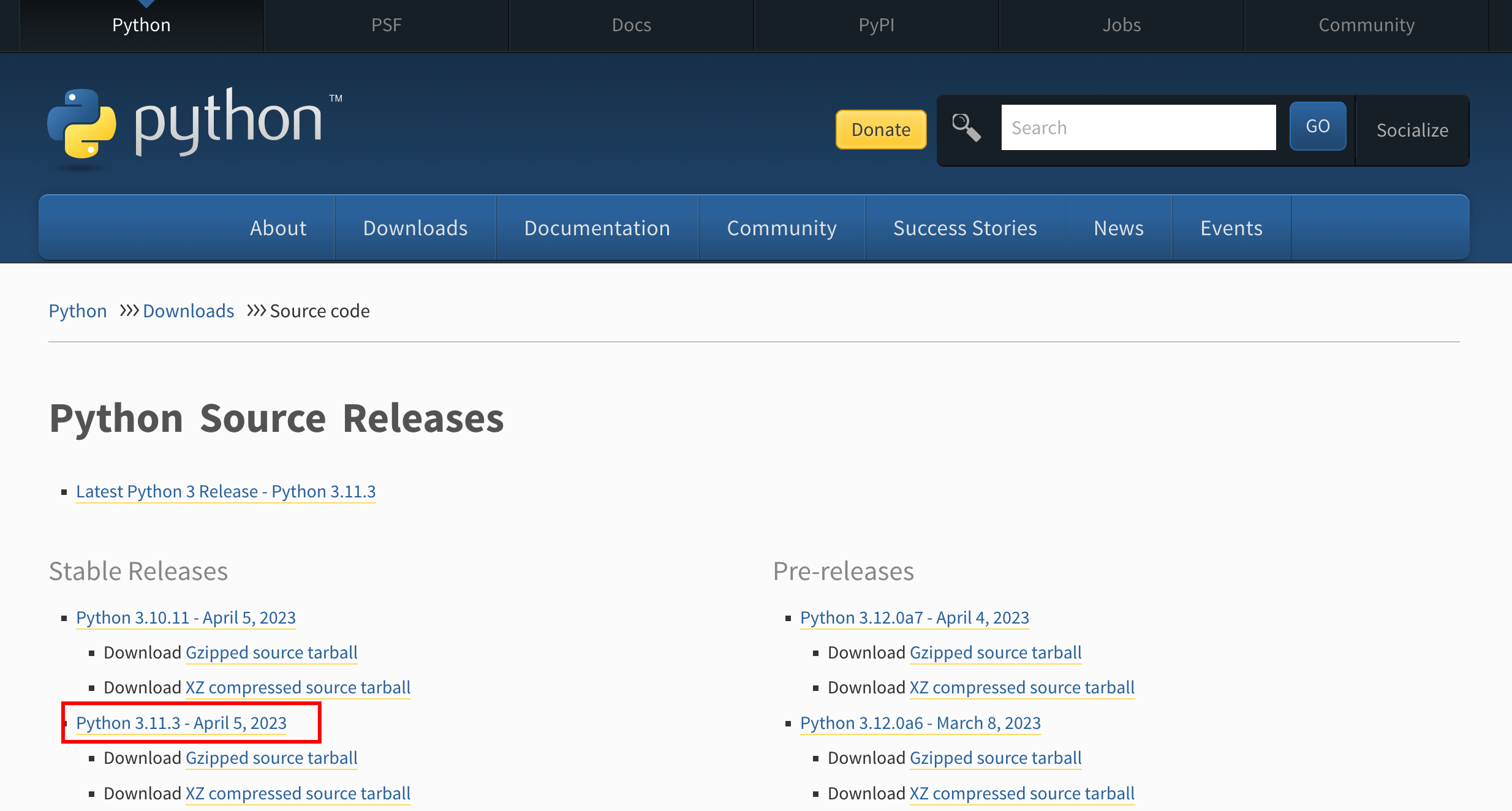
滑动页面至最下方,右键单击“Gzipped source tarball”,选择“复制链接地址”复制Python安装包下载地址,本例为https://www.python.org/ftp/python/3.11.3/Python-3.11.3.tgz。
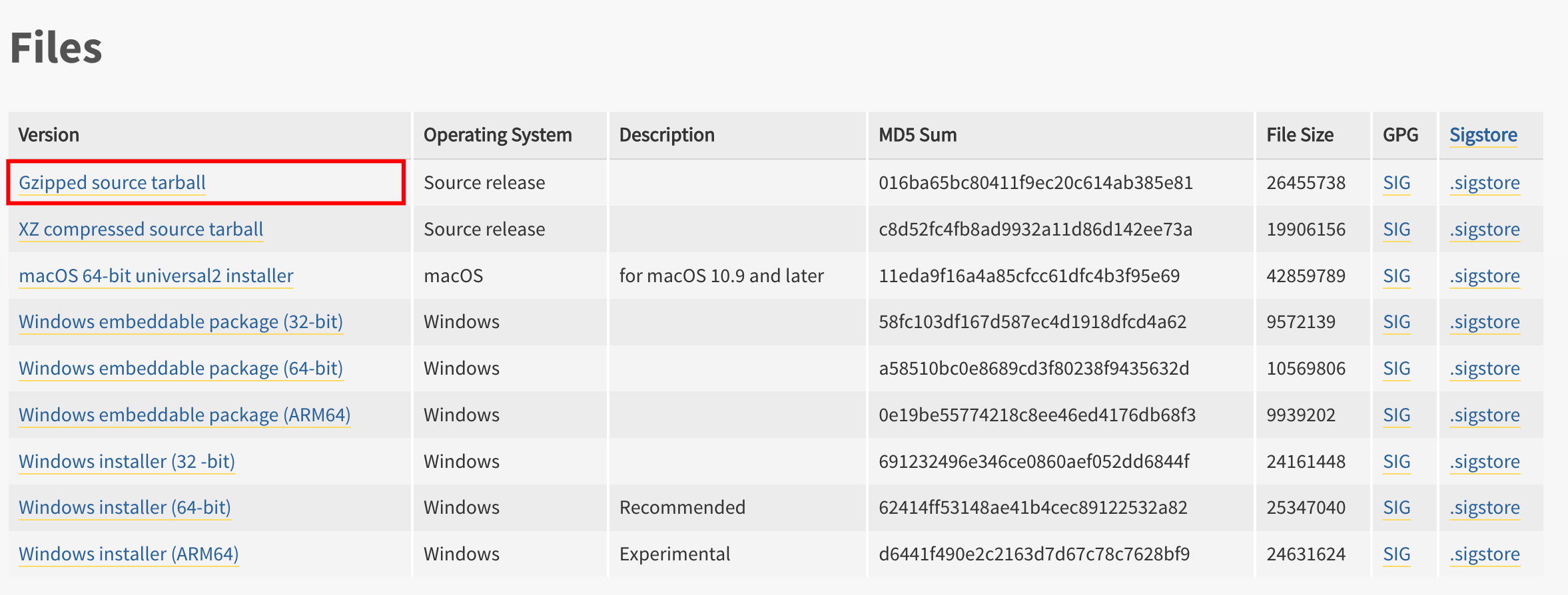
远程连接云服务器并登录,具体操作请参考通过控制台登录Linux实例
执行以下命令,拉取并安装Python安装包。
apt update apt -y upgrade wget https://www.python.org/ftp/python/3.11.3/Python-3.11.3.tgz tar -zxvf Python-3.11.3.tgz cd Python-3.11.3/ ./configure --prefix=/usr/local/python3.11.3 make && make install
执行以下命令,安装PIP。
cd apt install python3-pip
执行pip --version命令,回显如下,表示安装成功。

步骤三:安装Git
执行以下命令,安装Git。
apt -y install git执行git --version命令,回显如下,表示安装成功。
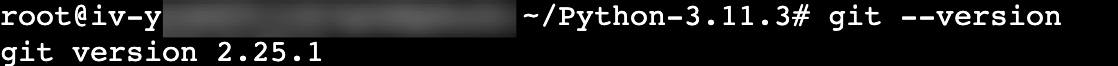
步骤四:确认NVIDIA驱动
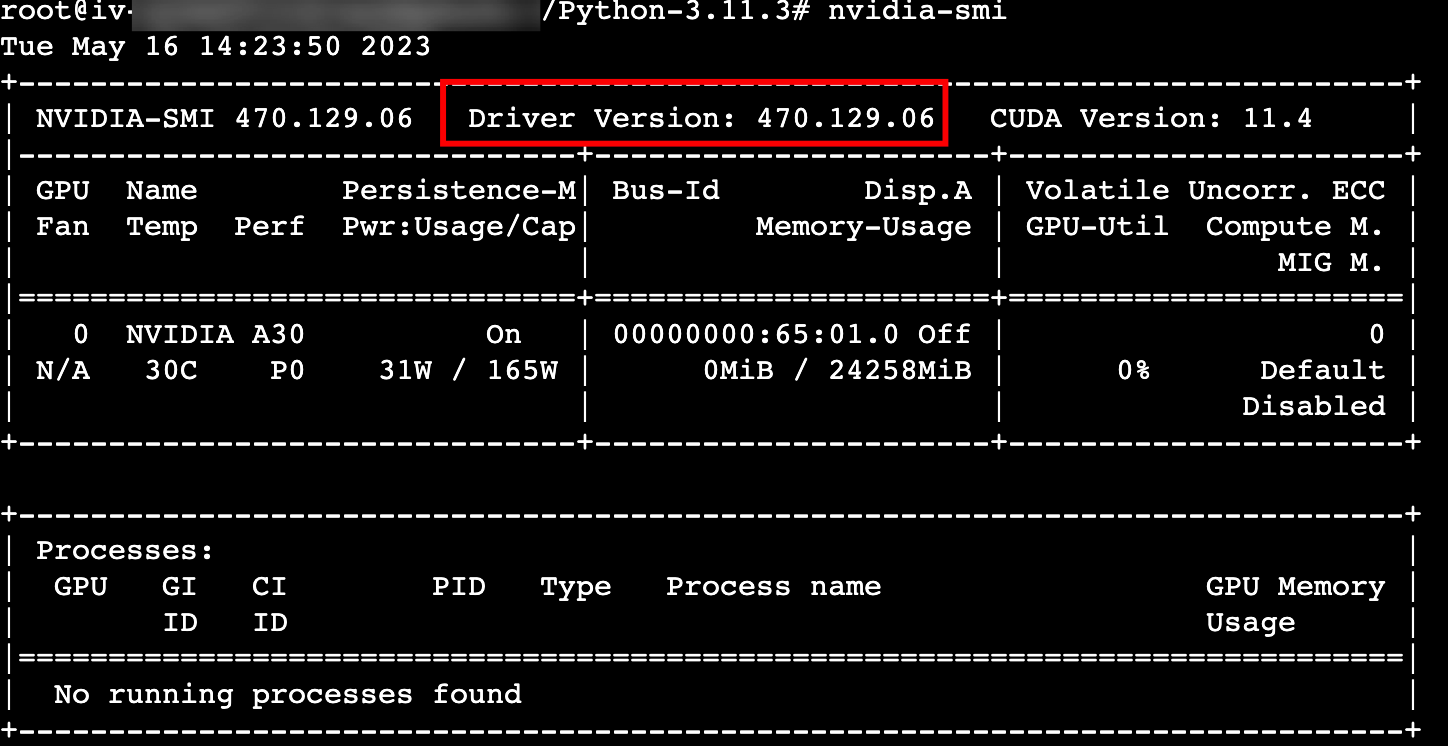
执行nvidia-smi命令,可以看到GPU驱动的版本,说明GPU驱动已安装成功。
执行/usr/local/cuda/bin/nvcc -V命令可以看到CUDA版本,说明CUDA已安装成功。
步骤五:安装Stable Diffusion UI
执行以下命令,安装Stable Diffusion UI。
cd git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
回显如下,表示下载成功。

步骤六:下载训练模型Stable Diffusion
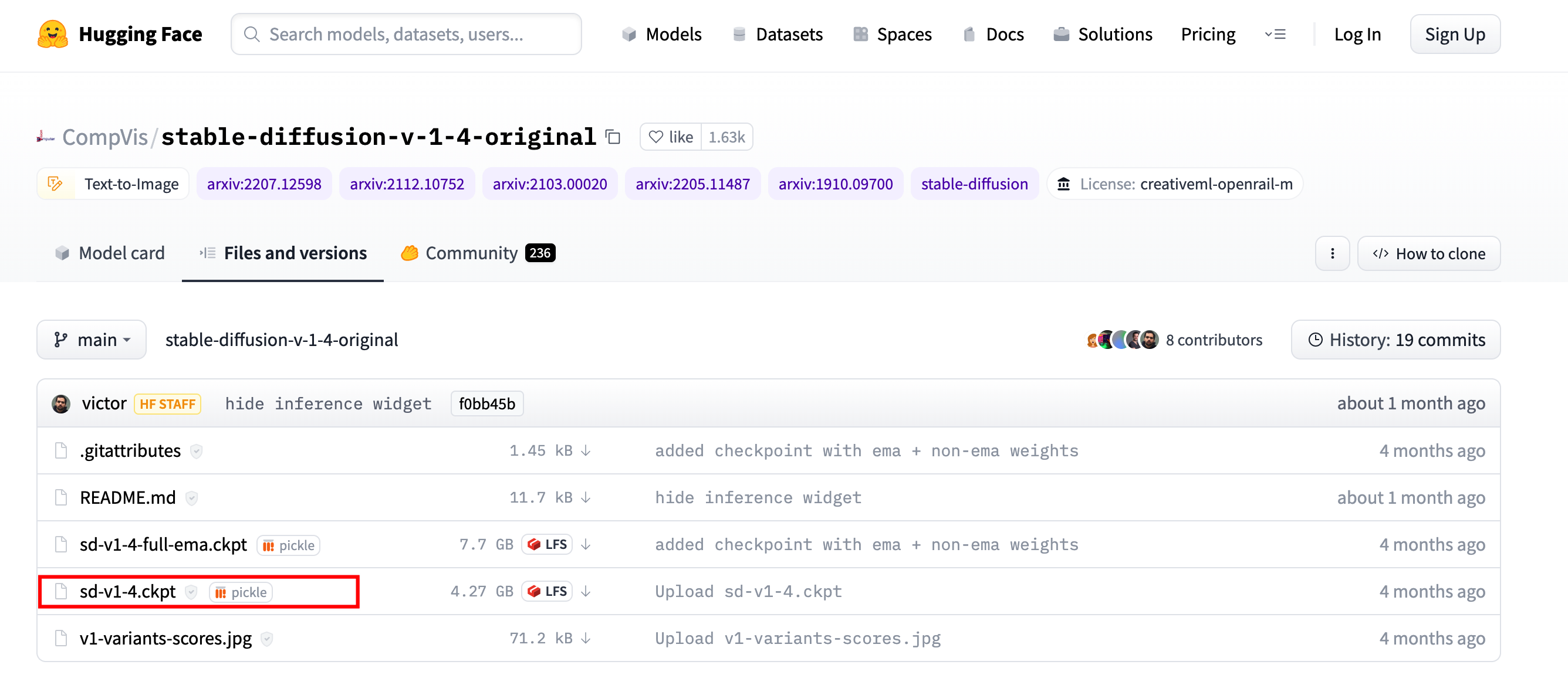
登录Stable Diffusion代码库,单击“Files and versions”页签。
右键单击“sd-v1-4.ckpt”训练模型,复制下载链接地址,本例为https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/blob/main/sd-v1-4.ckpt。
依次执行以下命令,进入训练模型存放目录并下载。
cd stable-diffusion-webui/models/Stable-diffusion/ wget https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/blob/main/sd-v1-4.ckpt
执行以下命令,进入训练模型webui目录。
cd & cd stable-diffusion-webui/执行以下命令,添加清华源。
执行vi launch_utils.py命令。
搜索代码run(f'"{python}" -m {torch_command},并添加清华源-i https://pypi.tuna.tsinghua.edu.cn/simple。

搜索代码return run(f'"{python}" -m pip {command},并添加清华源-i https://pypi.tuna.tsinghua.edu.cn/simple。

依次执行以下命令,进入并启动python-venv虚拟环境。
apt -y install python3.8-venv python3 -m venv venv_name source venv_name/bin/activate
回显如下,表示成功进入虚拟环境。

执行以下命令,安装gfpgan。
git clone https://github.com/TencentARC/GFPGAN.git pip install gfpgan
依次执行以下命令,运行webui.sh文件。
./webui.sh --share -f
根据网速不同,大约需要20分钟 - 2个小时不等,请耐心等待,一定不要关闭远程连接窗口。如果过程中出现运行失败的情况,请稍后重试或按需解决。回显如下,表示下载完成。
使用浏览器打开http://127.0.0.1:7860,注意不要关闭远程连接窗口。
步骤七:生成图片
在http://127.0.0.1:7860中配置相关参数。
参数 说明 取值示例 Sampling Steps AI推理的步数,步数越多画面中的细节就越多,需要的时间也就越久,一般设置20~30。 20 Sampling method AI推演的算法,一般可以选择Euler a、Euler 、DDIM。 Euler a 图片分辨率 取决于显卡,低于512 X 512画面不会有太多细节。 512*512 扩展选项
不配置
Batch count 运行次数。 1 Batch size 同时生成图片的张数。 1 CFG Scale 设置的越高,AI越严格按照设定生成图片,但也会有越少的创意;设置的越低,AI就会有更多的创意。一般设置为7左右。 7 Seed 生成每张图片时的随机种子,作为确定扩散初始状态的基础,一般保持默认。 -1 Restore faces:可以生成更真实的脸,第一次勾选使用时,需要先下载几个G的运行库。
Tiling:可以平铺图片,类似瓷砖,生成的图案左右上下都可以无缝衔接。
Highres. fix:让AI用更高的分辨率填充内容。
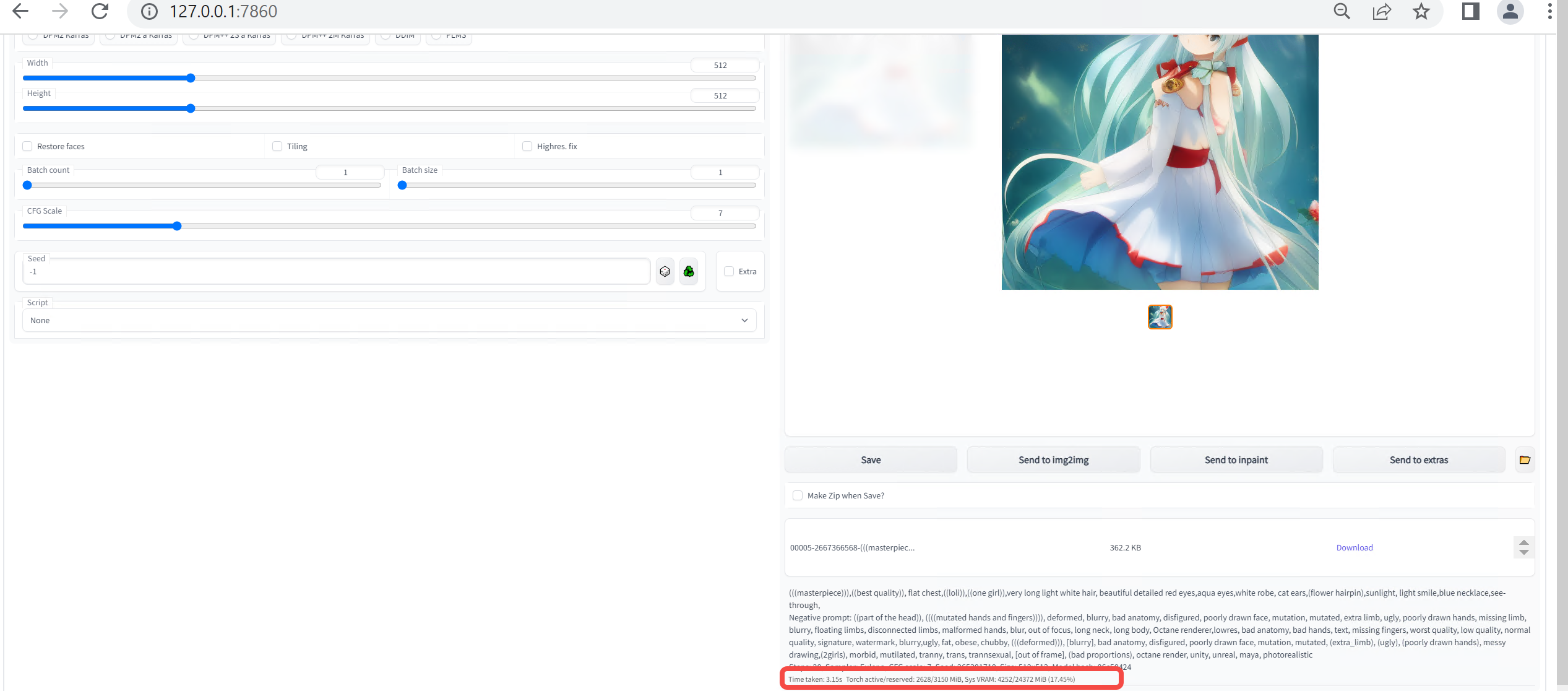
单击“生成”按钮后,即会获得一张本地AI生成的图片,以及图片产生用时和GPU利用率,如下图所示。