👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
本文主要介绍在云服务器实例中部署meta-llama/Llama-2-7b-hf模型并使用CPU进行推理,以及通过Intel xFasterTransformer实现推理过程加速的方案。
背景信息
Llama-2-7b-hf模型
xFasterTransformer
oneCCL
oneDNN
操作步骤
步骤一:环境准备
创建搭载了第5代英特尔®至强®可扩展处理器(Emerald Rapids,EMR)的云服务器实例,详细操作请参见购买云服务器。
实例规格:本文选择通用型g3i(ecs.g3i.8xlarge)规格。
云盘:推荐云盘容量不低于80GiB。
镜像:本文选择Ubuntu 22.04 LTS 64位。
网络:需要绑定公网IP,操作详情可查看绑定公网IP。
为目标实例安装依赖工具、软件。
登录目标实例。
执行如下命令,为目标实例安装Git、Python及pip。
apt install -y git python3 python3-pip
执行如下命令,检查实例GCC版本。
gcc --version
若版本不低于10,请继续后续步骤。

若版本低于10,请执行如下命令,升级GCC版本。
sudo apt updatesudo apt install -y gcc
执行如下命令,安装oneCCL。
git clone https://github.com/oneapi-src/oneCCL.git /tmp/oneCCL \&& cd /tmp/oneCCL \&& git checkout 2021.9 \&& sed -i 's/cpu_gpu_dpcpp/./g' cmake/templates/oneCCLConfig.cmake.in \&& mkdir build \&& cd build \&& cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local/oneCCL \&& make -j install \&& cd ~ \&& rm -rf /tmp/oneCCL \&& echo "source /usr/local/oneCCL/env/setvars.sh" >> ~/.bashrc
安装oneDNN。
执行如下命令,安装oneDNN。
cd /usr/localwget https://github.com/oneapi-src/oneDNN/releases/download/v0.21/mklml_lnx_2019.0.5.20190502.tgz \&& tar -xzf mklml_lnx_2019.0.5.20190502.tgz \&& rm -f mklml_lnx_2019.0.5.20190502.tgz \&& echo 'exportLD_LIBRARY_PATH=/usr/local/mklml_lnx_2019.0.5.20190502/lib:$LD_LIBRARY_PATH' >> ~/.bashrc
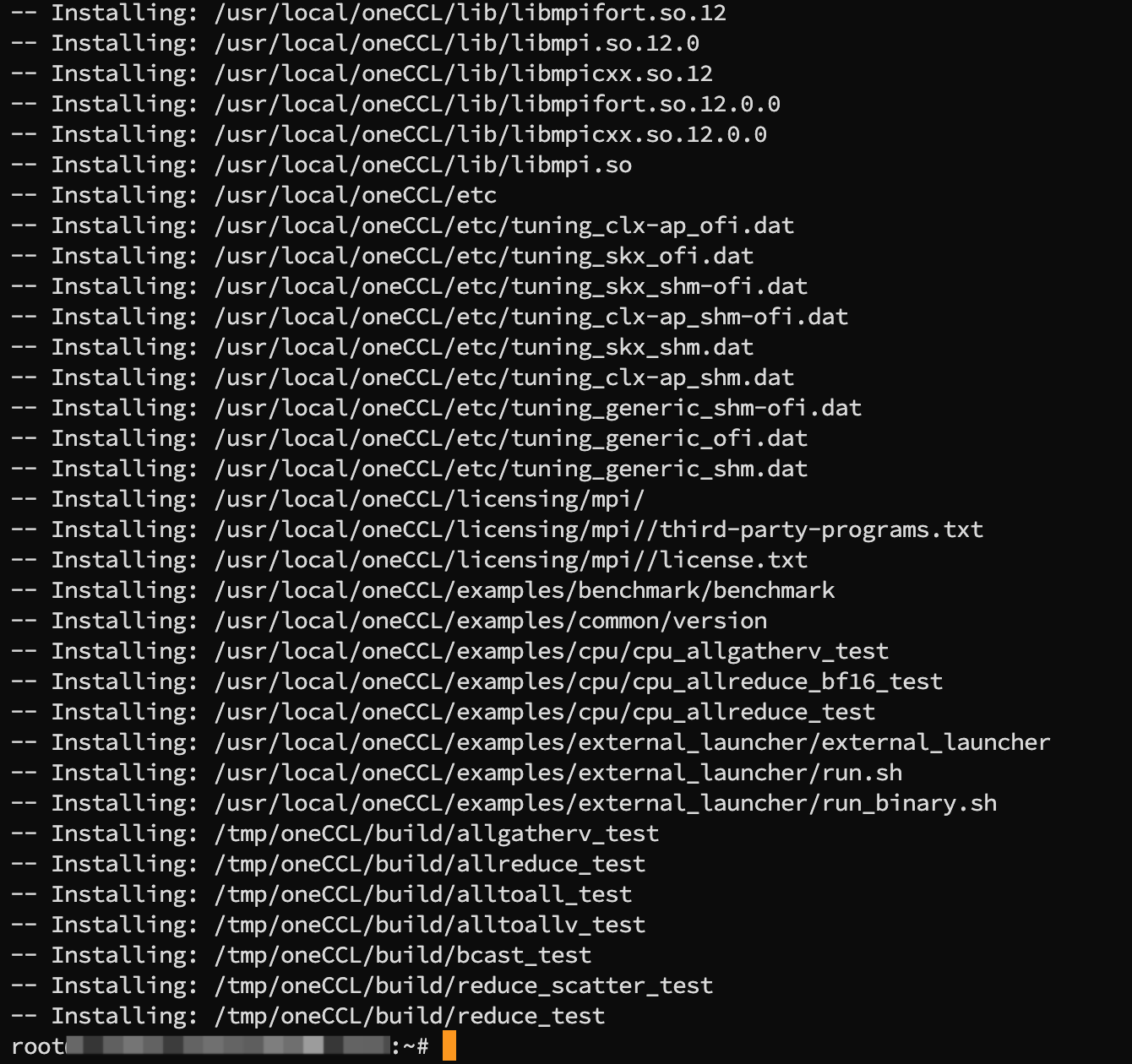
执行如下命令,验证是否完成安装。
cat ~/.bashrc | grep '/usr/local/mklml_lnx_2019.0.5.20190502/lib:$LD_LIBRARY_PATH'
成功安装示例

若未成功安装,请重新执行安装命令进行安装。
执行如下命令,安装xFasterTransformer。
pip install torch==2.0.1+cpu --index-url https://download.pytorch.org/whl/cpupip install cmake==3.26.1 transformers==4.30.0 sentencepiece==0.1.99 tokenizers==0.13.3 accelerate==0.23.0pip install xfastertransformerpip install gradio
成功安装示例
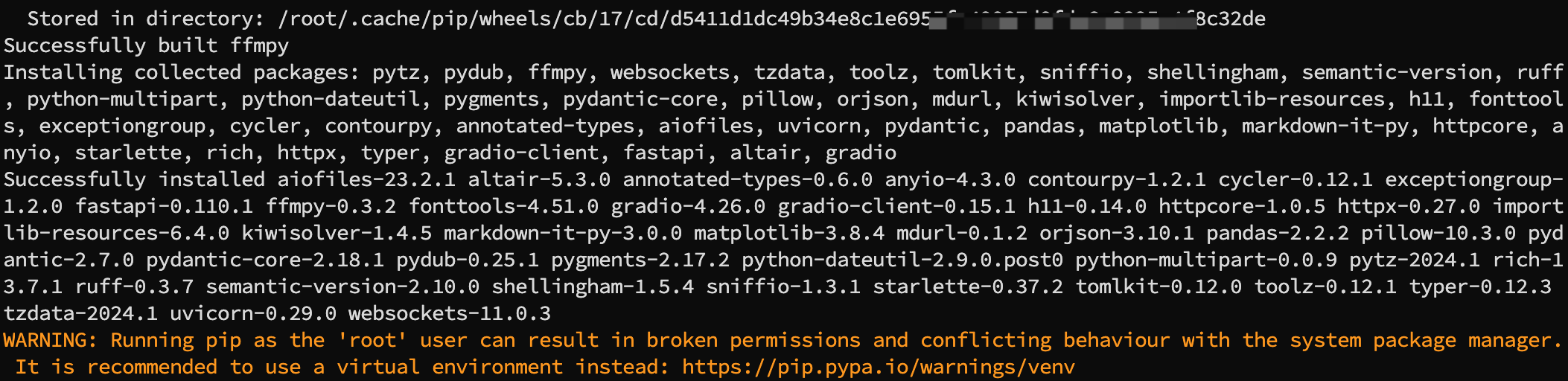
若未成功安装,请重新执行安装命令进行安装。
步骤二:部署Llama-2-7b-hf模型
获取下载授权。
访问Huggingface官方meta-llama/Llama-2-7b-hf模型页面。
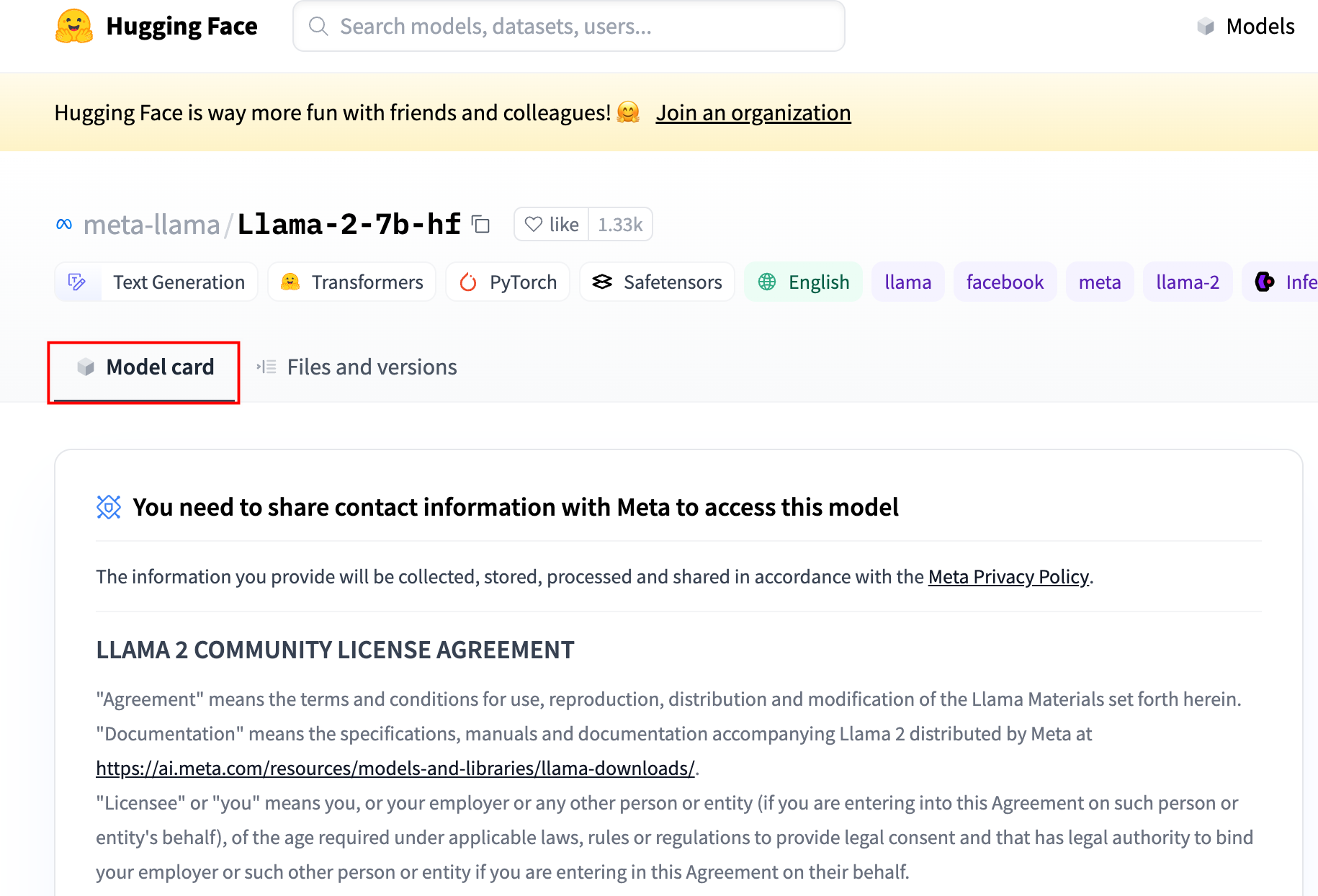
下划阅读模型使用许可协议,并填写所需信息,单击“Submit”按钮提交申请。
申请通过后,请登录HuggingFace Token页面,获取您有下载权限的Token。详情可查看User access tokens。
登录目标实例。
执行如下命令,下载模型。
请将命令中<your_token>替换为上一步获取的Token。
本文通过huggingface 镜像站下载模型,您也可以前往huggingface 官网进行下载。
pip install -U huggingface_hub hf_transferHF_ENDPOINT=https://hf-mirror.com HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download --token <your_token> --resume-download meta-llama/Llama-2-7b-hf --local-dir Llama-2-7b-hf --local-dir-use-symlinks=False
创建运行模型的Demo文件。
执行如下命令,创建llm2-demo.py文件。
vim llm2-demo.py
按i键进入编辑模式,复制如下内容粘贴入文件。
import gradio as grimport argparseimport osfrom transformers import AutoTokenizer, TextStreamerimport pathlibimport importlib.utilxft_spec = importlib.util.find_spec("xfastertransformer")if xft_spec is None:print("[INFO] xfastertransformer is not installed in pip, using source code.")exit()else:print("[INFO] xfastertransformer is installed, using pip installed package.")import xfastertransformerMODEL_PATH = "/root/Llama-2-7B-hf"TOKEN_PATH = "/root/Llama-2-7B-hf"MODEL_TYPE = "int8"cover_model_path = TOKEN_PATH+"/conver"if not os.path.exists(cover_model_path):os.mkdir(cover_model_path)if not os.listdir(cover_model_path):xfastertransformer.LlamaConvert().convert(MODEL_PATH,cover_model_path)def greet(input_prompts, answer_length):tokenizer = AutoTokenizer.from_pretrained(TOKEN_PATH, use_fast=False, padding_side="left", trust_remote_code=True)streamer = TextStreamer(tokenizer, skip_special_tokens=True, skip_prompt=False)input_ids = tokenizer([input_prompts], return_tensors="pt", padding=False).input_idsmodel = xfastertransformer.AutoModel.from_pretrained(cover_model_path, dtype=MODEL_TYPE)generated_ids = model.generate(input_ids, max_length=answer_length, streamer=streamer)output_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)return output_textif __name__ == "__main__":demo = gr.Interface(fn=greet,inputs=["text", gr.Slider(value=128, minimum=1, maximum=4096, step=1)],outputs=["text"],)demo.launch()修改脚本中MODEL_PATH、TOKEN_PATH,MODEL_TYPE三个参数的值。
参数名 | 说明 |
MODEL_PATH | 模型地址,请修改为您下载的Llama-2-7b-hf模型绝对路径。 |
TOKEN_PATH | tokenizer地址,一般和模型在一个文件夹下。 |
MODEL_TYPE | 模型精度,支持int4、int8、bf16等精度。 |
(可选) 若您需要生成可公网访问、可分享给他人访问的模型使用地址(URL),请修改demo.launch()为demo.launch(share=True)。
按esc键退出编辑,输入:wq保存并退出文件。
(可选) 下载生成公网地址依赖文件。
执行如下命令,下载依赖文件。
wget https://cdn-media.huggingface.co/frpc-gradio-0.2/frpc_linux_amd64
执行如下命令,修改文件名称。
mv frpc_linux_amd64 frpc_linux_amd64_v0.2
执行如下命令,将文件移动至gradio目录。
sudo mv frpc_linux_amd64_v0.2 /usr/local/lib/python3.10/dist-packages/gradio/
执行如下命令,为依赖文件增加可执行权限。
chmod +x /usr/local/lib/python3.10/dist-packages/gradio/frpc_linux_amd64_v0.2
步骤三:运行Llama-2-7b-hf模型
登录目标实例。
llm2-demo.py文件所在目录,执行如下命令,运行模型。
若您也使用通用型g3i(ecs.g3i.8xlarge)规格实例,推荐您使用本命令进行绑核推理。
若您使用其他规格实例,请根据实际情况调整物理CPU绑定范围。
numactl -C 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30 python3 llm2-demo.py

您可以使用回显的URL,通过浏览器进入模型推理页面。

性能说明
测试数据
Llama3-8B模型部署、推理流程与本实践相同。模型详情可查看meta-llama/Meta-Llama-3-8B。
数据说明:
吞吐性能:本实践中,吞吐指模型在单位时间内输出的新Token数量(1个Token对应1个单词)。
首包延时:模型在接收到输入文本后产生第一个输出的时间。
实例规格 | 模型 | 数据精度 | 参数 | 吞吐性能 | 首包延时 |
ecs.g3i.8xlarge (32 vCPU 128 GiB) | Llama-2-7b-hf | w8a8 |
| 24.04 Tokens/s | 0.67 s |
bf16 | 14.48 Tokens/s | 0.85 s | |||
Llama-3-8B | w8a8 | 22.12 Tokens/s | 0.75 s | ||
bf16 | 13.1 Tokens/s | 0.89 s |
测试结论