👉点击这里申请火山引擎VIP帐号,立即体验火山引擎产品>>>
本功能正在邀测中,如需试用,请联系客户经理申请。
操作场景
注意事项
暂仅支持本地SSD型弹性裸金属ebmi3s规格的实例使用本功能。
请确保根据操作步骤指引,修改本地盘配置后,再进行运维授权,否则可能无法正常识别更换的新本地盘。
更换故障盘可能导致数据丢失,请提前备份数据,以防数据丢失,例如通过硬盘、U盘等将重要数据拷贝到外部存储设备。
操作步骤
步骤一:获取故障硬盘序列号
步骤二:修改硬盘配置
登录挂载故障盘的ECS实例,操作详情可查看登录实例。
执行如下命令,查看故障本地盘盘符。
请将$SN$替换为实际硬盘SN。
lsblk -oNAME,SERIAL | grep $SN$
执行如下命令,查看故障本地盘文件系统与其UUID。
请将/dev/vda2替换上一步中获取的实际故障盘盘符。
blkid /dev/vda2
执行如下命令,编辑/etc/fstab文件。
打开/etc/fstab文件。
vim /etc/fstab
按i键进入编辑模式,在文件中目标本地盘后添加nofail参数。
仅需加入nofail参数,无需调整其它内容。

参数 | 说明 |
24fd1325-bbf3-4814-b7e9-041deba***** | 故障本地盘的UUID。 |
/ | 故障本地盘挂载点。 |
ext4 | 故障本地盘文件系统类型。 |
nofail | 本地盘出现在文件系统中但实际缺失时,不会中断ECS实例的启动流程。 |
按esc键,输入:wq保存修改并退出。
执行如下命令,取消故障本地盘挂载。
umount /dev/vda2
步骤三:授权运维
登录云服务器控制台。
在左侧导航树,选择“运维与监控 > 事件监控”,进入事件监控页面。
在顶部导航栏选择业务所在地域与项目。
在事件监控页面,可以通过时间段或事件ID、实例ID搜索目标事件。
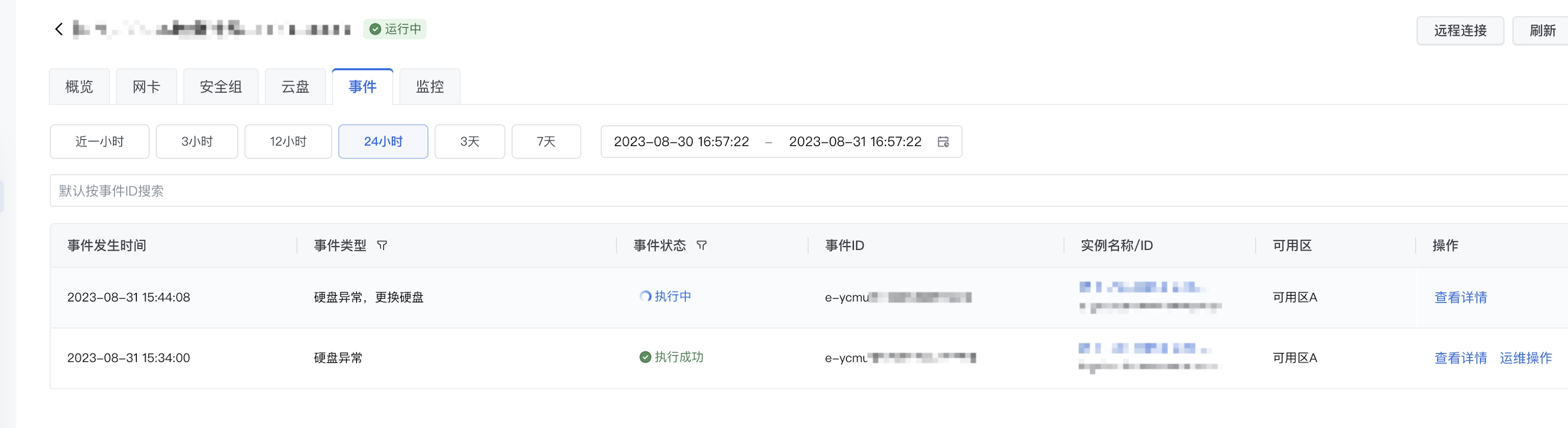
单击目标事件“操作”列的“运维操作”按钮,进入运维配置页面。
“运维方式”请选择“更换故障盘”。

单击“授权运维”按钮,并单击确认弹窗中的“确定”按钮,授权火山引擎运维人员更换故障硬盘。
授权后,将生成DiskError.ReplaceDisk(因硬盘异常更换硬盘)事件,提示您更换故障盘进度。
授权后,请勿对实例生命周期进行操作(例如重启、关机)。
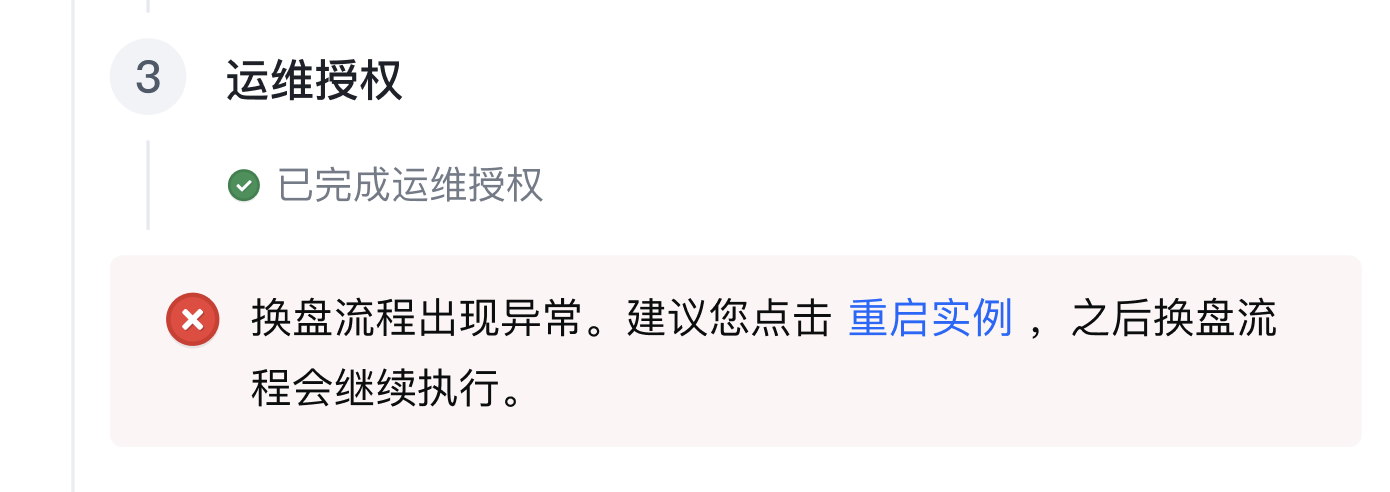
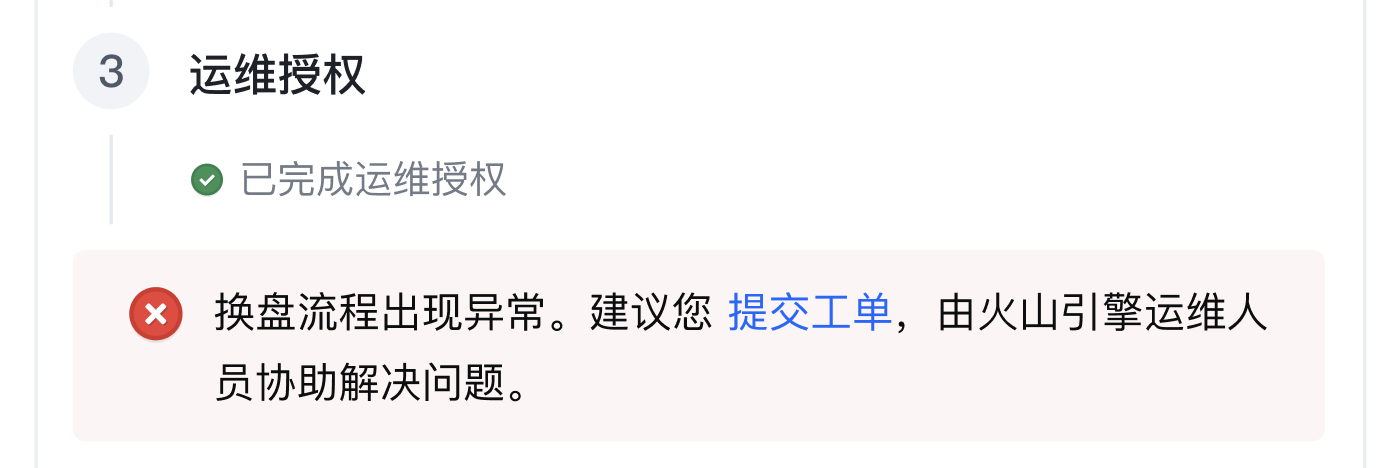
更换故障盘流程出现异常时,将向您发送DiskError.ReplaceDisk:Pending事件通知。收到通知后,您需要根据提示重启实例或提交工单解决异常问题。
通过重启实例解决问题
通过工单解决问题
更换故障盘成功,将向您发送DiskError.ReplaceDisk:Succeeded事件通知。
步骤四:进行硬件检测
登录实例。
在实例中执行如下命令,进行在位检测,确认本地盘是否连接到系统、是否可用。
nvme list

执行如下命令,检查目标磁盘的健康状态、坏道情况等SMART信息。
请将/dev/nvme0替换为实际磁盘名。
smartctl -d nvme -a /dev/nvme0
回显示例

参数说明
参数 | 无异常 | 异常说明 |
Critical Warning | 0x00 |
|
Error Information | No Errors Logged | error级别错误为可自修复性错误,您可以忽略。 |
Error Information Log Entries | 0 | 大于 0 条信息表示设备存在异常,异常详情可查看Error Information参数的回显信息。 |
硬件检测均无异常后,即可挂载硬盘。
步骤五:挂载硬盘
通过硬件检测后,您需要登录实例挂载本地盘。
若更换故障盘后,实例未识别到本地盘,请提交工单获取技术支持。
推荐您使用UUID而非设备名(如/dev/data1)进行挂载。
登录实例。
执行如下命令,查看未挂载(新本地盘)的数据盘信息。
lsblk -l
执行如下命令,为待挂载的数据盘制作文件系统。
mkfs -t <文件系统> <UUID>
执行如下命令,挂载数据盘。
mount -U <UUID> <挂载点>
执行如下命令,确认数据盘是否挂载成功。